Download & Unzip
Download Hive 1.2.1 from this address https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-1.2.1/apache-hive-1.2.1-bin.tar.gz
Then use the following command to extract it to the specified directory:
tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /root/apps/
Then change the name with the following command:
mv apache-hive-1.2.1-bin hive-1.2.1
Install MySQL
MySQL is used to store Hive's metadata. It is not recommended to use Derby as Hive's metadata database because its data files are stored under the running directory by default, and the data before can't be seen next time a new directory is launched.
I have installed it here, if you need to install it, you can refer to it. http://www.cnblogs.com/liuchangchun/p/4099003.html Remember to configure remote login.
Modify configuration files
Use the following command to create the configuration file:
vim /root/apps/hive-1.2.1/conf/hive-site.xml
Insert the following contents:
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>sorry</value>
<description>password to use against metastore database</description>
</property>
</configuration>
Copy Jar Pack
There is no mysql-connector-java.jar to go http://download.csdn.net/detail/u014436218/7217805 Download.
Copy the mysql-connector-java-5.1.30-bin.jar you just downloaded to hive's lib directory.
Start Hive
Before starting Hive, you need to start the Hadoop cluster. Then use the following command to start Hive:
/root/apps/hive-1.2.1/bin/hive
Successful startup is indicated by the following prompt:
hive>
Verify that Hive is working properly
After starting Hive, enter the following command:
hive> show databases;
The output is:
OK default Time taken: 1.029 seconds, Fetched: 1 row(s)
Create a database
Use the following command to create a database:
create database test_db;
The output results are as follows:
OK Time taken: 0.216 seconds
The data files of the database are stored under / user/hive/warehouse/test_db.db of HDFS.
Create tables
Use the following command to create a table:
use test_db; create table t_test(id int,name string);
The output results are as follows:
OK Time taken: 0.237 seconds
The data file of the table is stored under / user/hive/warehouse/test_db.db/t_test of HDFS.
insert data
Next, let's import some data into the table.
Prepare the following data file, sz.data. The document reads as follows:
1. Zhang San 2. Li Si 3. Fengling Four, Three Less May, Yueguan 6,abc
Then upload the file to hdfs using the following command:
hadoop fs -put sz.data /user/hive/warehouse/test_db.db/t_test/sz.data
Then try to query with the following statement:
select * from t_test;
The output results are as follows:
OK NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL NULL Time taken: 0.329 seconds, Fetched: 6 row(s)
Data was not successfully identified because no data separator was specified.
Clear the table data using the following command:
truncate table t_test;
The table still exists, but the data under HDFS is no longer available.
Use the following command to delete the table:
drop table t_test;
Use the following command to recreate the table, specifying the data separator.
create table t_test(id int, name string) row format delimited fields terminated by ',';
Then copy the data again.
hadoop fs -put sz.data /user/hive/warehouse/test_db.db/t_test/sz.data
Re-execute the query:
hive> select * from t_test;
The output is as follows:
OK 1 Zhang San 2 Li Si 3 Wind drift 4 Three less 5 Lunar month pass 6 abc Time taken: 0.146 seconds, Fetched: 6 row(s)
count query
Use the following command to experience how Hive uses MapReduce to run queries:
select count(1) from t_test;
You can see the following running tips:
Query ID = root_20170325234306_1aaf3dcf-e758-4bbd-9ae5-e649190d8417 Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks determined at compile time: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapreduce.job.reduces=<number> Starting Job = job_1490454340487_0001, Tracking URL = http://amaster:8088/proxy/application_1490454340487_0001/ Kill Command = /root/apps/hadoop-2.7.3/bin/hadoop job -kill job_1490454340487_0001 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 2017-03-25 23:43:23,084 Stage-1 map = 0%, reduce = 0% 2017-03-25 23:43:36,869 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.71 sec 2017-03-25 23:43:48,392 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.4 sec MapReduce Total cumulative CPU time: 3 seconds 400 msec Ended Job = job_1490454340487_0001 MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.4 sec HDFS Read: 6526 HDFS Write: 2 SUCCESS Total MapReduce CPU Time Spent: 3 seconds 400 msec
At the same time, task information can also be seen in the YARN cluster.
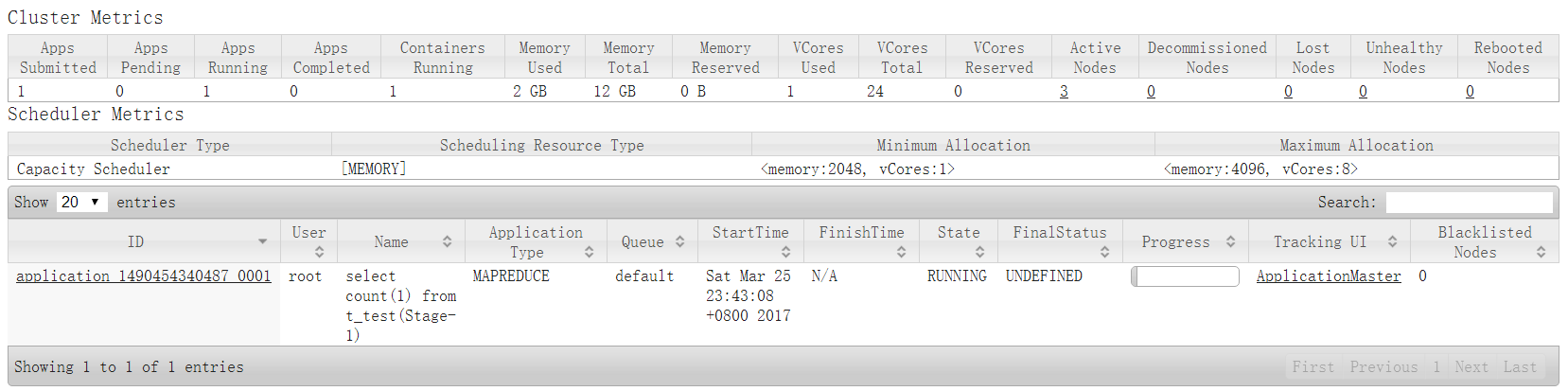
The output results are as follows:
OK 6 Time taken: 44.51 seconds, Fetched: 1 row(s)
Hive was found to be slow and unsuitable for online business support.
Hive's metadata
Next, let's look at Hive's metadata stored in MySQL.
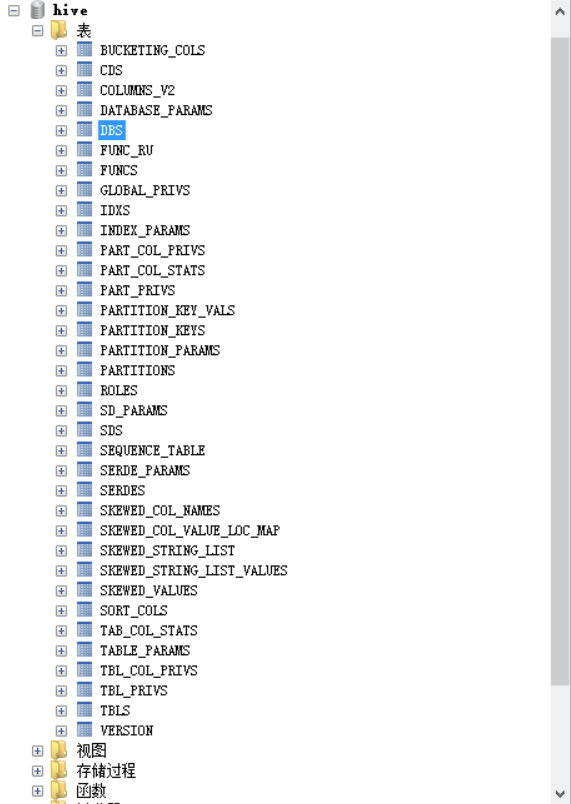
You can see many tables. The DBS table records the records of the database:

The functions of other tables can be explored on their own.