Author: duktig
Blog: https://duktig.cn (first article)
Excellent still work hard. May you enjoy what you give and enjoy what you get.
See github knowledge base for more articles: https://github.com/duktig666/knowledge
background
After learning Hadoop, do you feel that writing a MapReduce program is very complex, and it requires a lot of development cost to conduct analysis and statistics. Then let's learn about Hive, another member of the Hadoop ecosystem. Let's learn how to use SQL like language to quickly query and analyze data.
In the previous article, we learned about Hive's overview, DDL statements and DML statements (key points). This article mainly understands Hive's bucket table and partition table.
Hive series articles are as follows:
Partition table
The partition table actually corresponds to an independent folder on an HDFS file system. Under this folder are all the data files of the partition. The partition in Hive is a subdirectory, which divides a large data set into small data sets according to business needs. When querying, select the specified partition required by the query through the expression in the WHERE clause, which will greatly improve the query efficiency.
Create partition table
create table dept_partition( deptno int, dname string, loc string ) partitioned by (day string) row format delimited fields terminated by ' ';
Data preparation - introduce partition table (manage the log according to the date and simulate through department information)
dept_20211027.log
10 ACCOUNTING 1700 20 RESEARCH 1800
dept_20211028.log
30 SALES 1900
dept_20211029.log
40 OPERATIONS 1700 50 DK 1500 60 GEN 1200
Load data into partition table
load data local inpath './dept_20211027.log' into table dept_partition partition(day='20211027'); load data local inpath './dept_20211028.log' into table dept_partition partition(day='20211028'); load data local inpath './dept_20211029.log' into table dept_partition partition(day='20211029');
Note: the partition must be specified when the partition table loads data
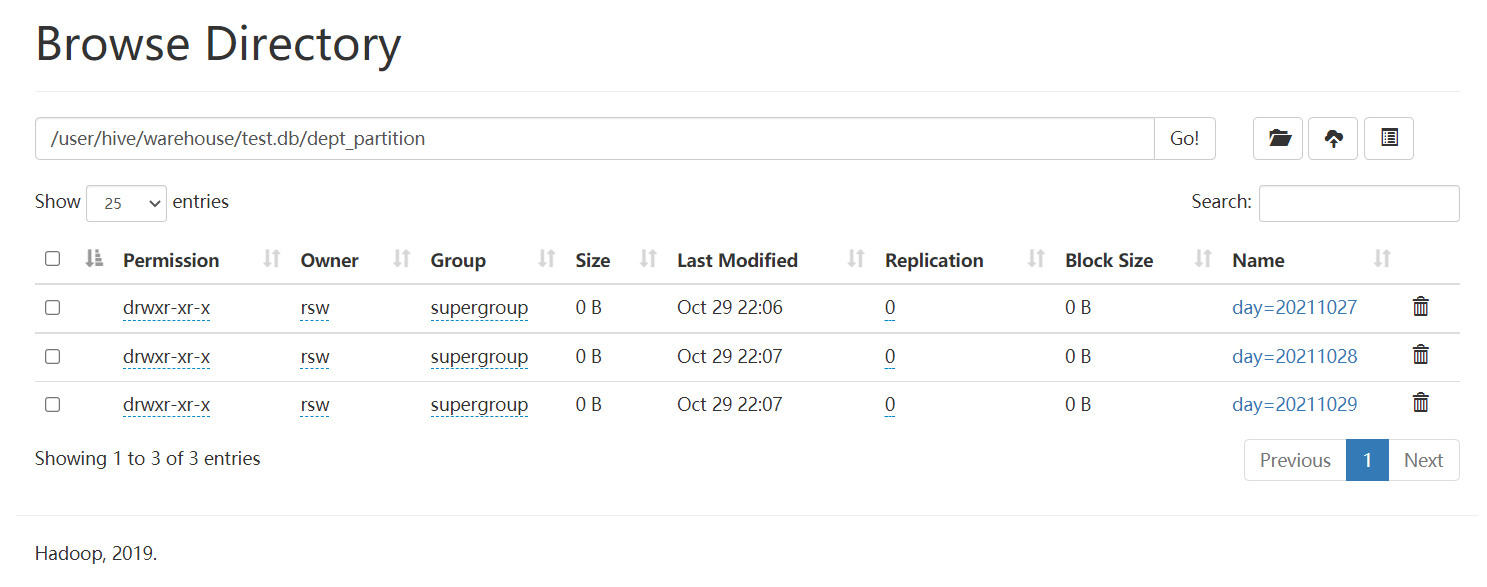
Basic operations of partition table
Query data in partition table
# Single partition query
select * from dept_partition where day='20211027';
# Multi partition joint query
select * from dept_partition where day='20211027'
union
select * from dept_partition where day='20211028'
union
select * from dept_partition where day='20211029';
## The results of the two operations are the same, and this is faster
select * from dept_partition where day='20211027' or day='20211028' or day='20211029';
Add partition
alter table dept_partition add partition(day='20211030'); alter table dept_partition add partition(day='20211031') partition(day='20211101');
delete a partition
alter table dept_partition drop partition(day='20211030'); alter table dept_partition drop partition(day='20211031') partition(day='20211101');
View how many partitions the partition table has
show partitions dept_partition;
View partition table structure
desc formatted dept_partition;
Secondary partition
Thinking: if there is a large amount of log data in a day, how to split the data?
Create secondary partition table
create table dept_partition2( deptno int, dname string, loc string ) partitioned by (day string, hour string) row format delimited fields terminated by ' ';
Normal load data
Load data into secondary partition table
load data local inpath './dept_20211027.log' into table dept_partition2 partition(day='20211027',hour='12');
Query secondary partition data
select * from dept_partition2 where day='20211027' and hour='12';
There are three ways to upload data directly to the partition directory and associate the partition table with the data
Method 1: repair after uploading data
Upload data
hadoop fs -mkdir /user/hive/warehouse/test.db/dept_partition2/day=20211028/hour=13; hadoop fs -put ./dept_20211028.log /user/hive/warehouse/test.db/dept_partition2/day=20211028/hour=13;
Query data (the data just uploaded cannot be queried)
select * from dept_partition2 where day='20211028' and hour='13';
Execute repair command
msck repair table dept_partition2;
You can query the data again.
Method 2: add partition after uploading data
Upload data
hadoop fs -mkdir -p /user/hive/warehouse/test.db/dept_partition2/day=20211028/hour=14; hadoop fs -put ./dept_20211028.log /user/hive/warehouse/test.db/dept_partition2/day=20211028/hour=14;
Execute add partition
alter table dept_partition2 add partition(day='20211028',hour='14');
Query data
select * from dept_partition2 where day='20211028' and hour='14';
Method 3: after creating a folder, load data to the partition
Create directory
hadoop fs -mkdir -p /user/hive/warehouse/test.db/dept_partition2/day=20211029/hour=15;
Upload data
load data local inpath './dept_20211028.log ' into table dept_partition2 partition(day='20211028',hour='15');
Query data
select * from dept_partition2 where day='20211028' and hour='15';
After actual test, the following problems are found
hadoop fs -mkdir -p directory contains = and cannot create the folder as scheduled.
However, based on the partition table, directly executing the add partition command will create a directory by itself
alter table dept_partition2 add partition(day='20211029',hour='18');
Then upload the data
load data local inpath './dept_20211029.log' into table dept_partition2 partition(day="20211029",hour="18");
Query data
select * from dept_partition2 where day='20211029' and hour='18';
Dynamic partition adjustment
When inserting data into a partition table in a relational database, the database will automatically Insert the data into the corresponding partition according to the value of the partition field. Hive also provides a similar mechanism, dynamic partition. However, using hive's dynamic partition requires corresponding configuration.
Parameter configuration
-
Enable the dynamic partition function (true by default, enabled)
set hive.exec.dynamic.partition=true;
-
Set to non strict mode (dynamic partition mode, strict by default), indicating that at least one partition must be specified as
Static partition, nonstrict mode means that all partition fields are allowed to use dynamic partition.)set hive.exec.dynamic.partition.mode=nonstrict;
-
How many dynamic partitions can be created on all MR nodes. Default 1000
set hive.exec.max.dynamic.partitions=1000;
-
How many dynamic partitions can be created on each node executing MR. This parameter needs to be set according to the actual data. For example, if the source data contains one year's data, that is, the day field has 365 values, then the parameter needs to be set to greater than 365. If the default value of 100 is used, an error will be reported.
set hive.exec.max.dynamic.partitions.pernode=100
-
How many HDFS files can be created in the whole MR Job. Default 100000
set hive.exec.max.created.files=100000;
-
Whether to throw an exception when an empty partition is generated. Generally, no setting is required. Default false
set hive.error.on.empty.partition=false;
Instance operation
Requirement: insert the data in the dept table into the target table Dept by Region (loc field)_ In the corresponding partition of partition.
-
Create target partition table
Note that partition fields and table fields cannot be the same.
create table dept_partition_dy(id int, name string) partitioned by (loc int) row format delimited fields terminated by ' ';
-
Set dynamic partition
set hive.exec.dynamic.partition.mode = nonstrict;
-
insert data
Hive 3.0 can insert without specifying the partition field.
insert into table dept_partition_dy partition(loc) select deptno, dname, loc from dept;
-
View the partition of the target partition table
show partitions dept_partition_dy;
dept content:
10 ACCOUNTING 1700 20 RESEARCH 1800 30 SALES 1900 40 OPERATIONS 1700
Results: three zones were divided according to 1700, 1800 and 1900
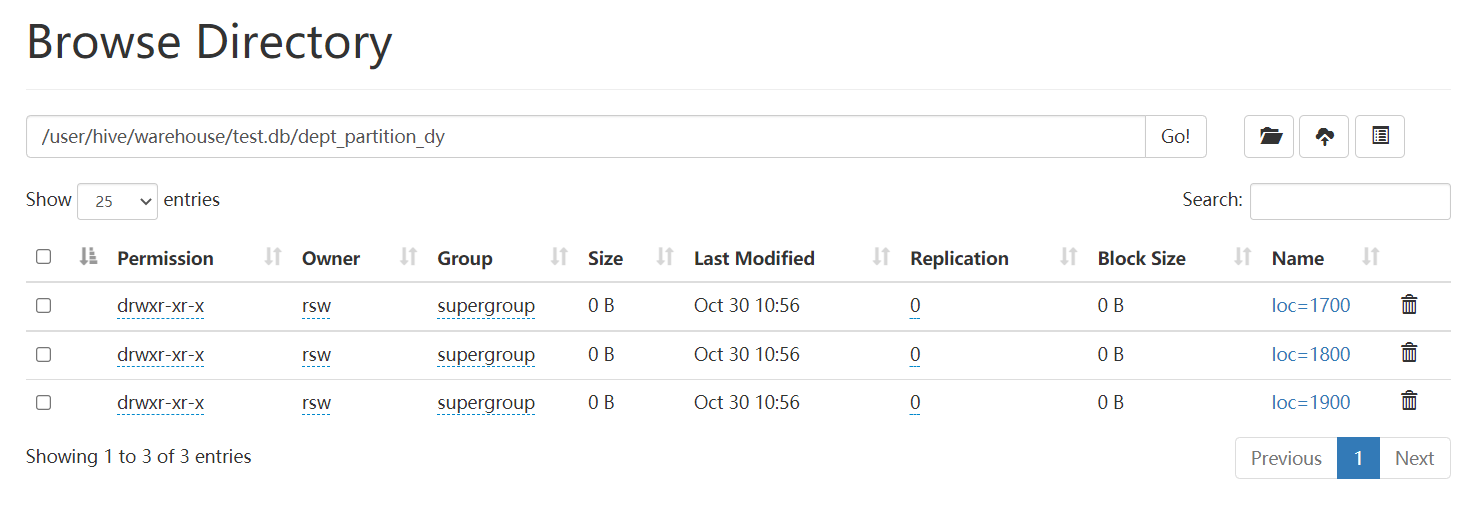
Think: how does the target partition table match to the partition field?
Barrel table
Partitioning provides a convenient way to isolate data and optimize queries. However, not all data sets can form reasonable partitions. For a table or partition, Hive can be further organized into buckets, that is, more fine-grained data range division.
Bucket splitting is another technique for breaking up a data set into parts that are easier to manage.
Partition refers to the storage path of data; Buckets are for data files.
Create bucket table
Data preparation: create a new student.txt
1001 ss1 1002 ss2 1003 ss3 1004 ss4 1005 ss5 1006 ss6 1007 ss7 1008 ss8 1009 ss9 1010 ss10 1011 ss11 1012 ss12 1013 ss13 1014 ss14 1015 ss15 1016 ss16
Create bucket table
create table stu_buck(id int, name string) clustered by(id) into 4 buckets row format delimited fields terminated by ' ';
View table structure
desc formatted stu_buck;
Upload local files to hdfs
hadoop fs -put ./student.txt /user/hive/warehouse
Import data into the bucket splitting table by load ing
load data inpath '/user/hive/warehouse/student.txt' overwrite into table stu_buck;
Errors will be reported when importing data as follows:
Diagnostic Messages for this Task:
Error: java.lang.RuntimeException: org.apache.hadoop.hive.ql.metadata.HiveException: Hive Runtime Error while processing row (tag=0) {"key":{},"value":{"
_col0":1011,"_col1":"ss11"}}
solve:
stackoverflow solution: Hive Runtime Error while processing row in Hive However, the actual test was not successful.
Check whether the created bucket table is divided into 4 buckets
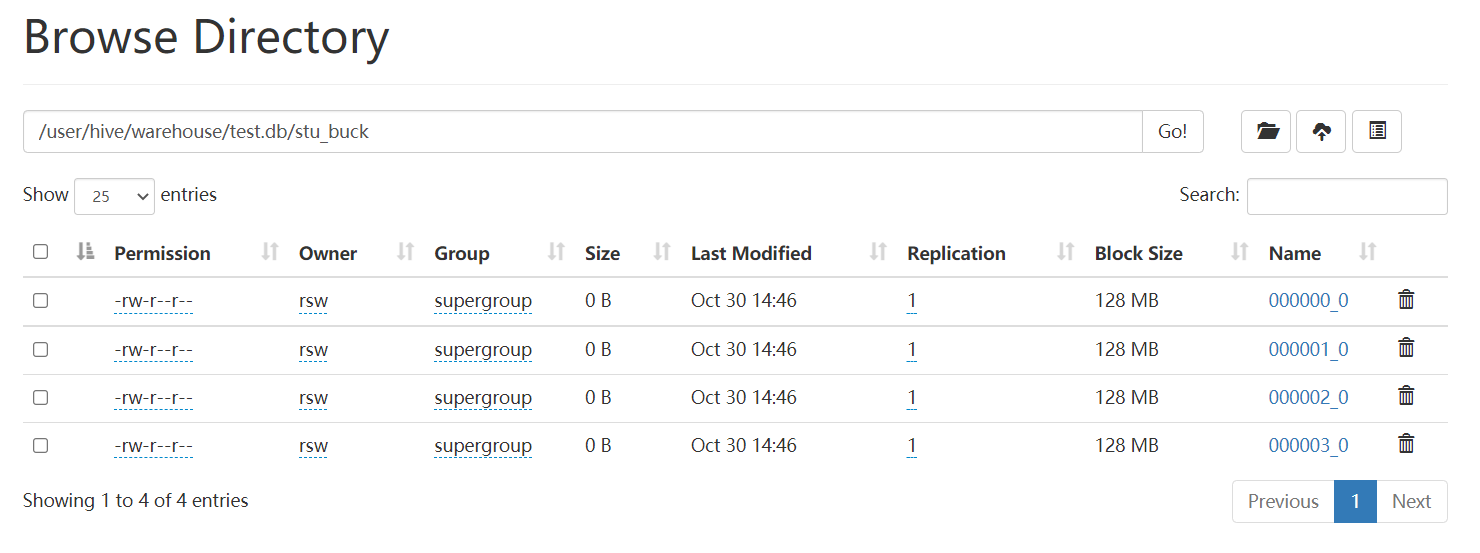
Query bucket data
select * from stu_buck;
Barrel separation rules:
According to the results, Hive's bucket splitting method hashes the value of the bucket splitting field, and then divides it by the number of buckets to find the remainder
Determines which bucket the record is stored in
Precautions for operation of drum dividing table
-
Set the number of reduce to - 1, and let the Job decide how many reduce to use or set the number of reduce to be greater than or equal to the number of buckets in the bucket splitting table
-
load data from hdfs to the bucket table to avoid the problem that the local file cannot be found
-
Import data into bucket table in insert mode
insert into table stu_buck select * from student_insert;
Sampling query
For very large data sets, sometimes users need to use a representative query result rather than all the results. Hive can meet this requirement by sampling tables.
Syntax:
TABLESAMPLE(BUCKET x OUT OF y)
Query table stu_ Data in buck.
select * from stu_buck tablesample(bucket 1 out of 4 on id);
Note: the value of x must be less than or equal to the value of y, otherwise an error is reported:
FAILED: SemanticException [Error 10061]: Numerator should not be bigger than denominator in sample clause for table stu_buck