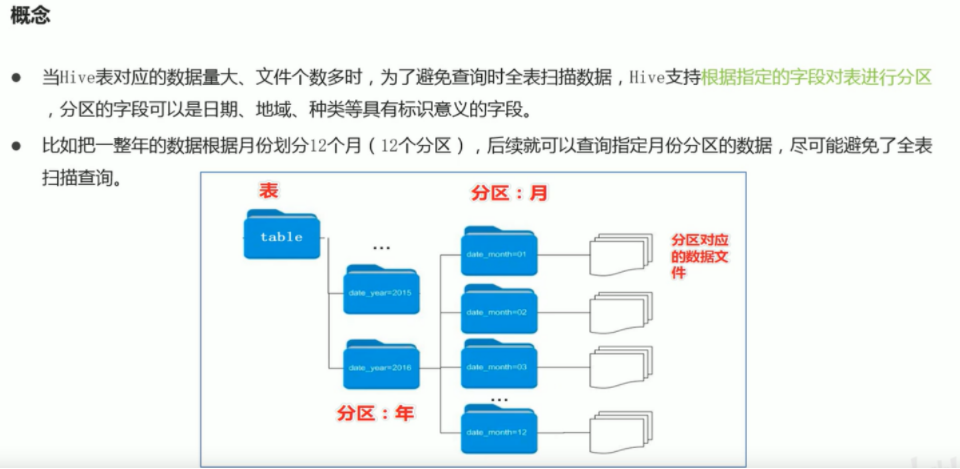
hive partition
1. Primary zoning
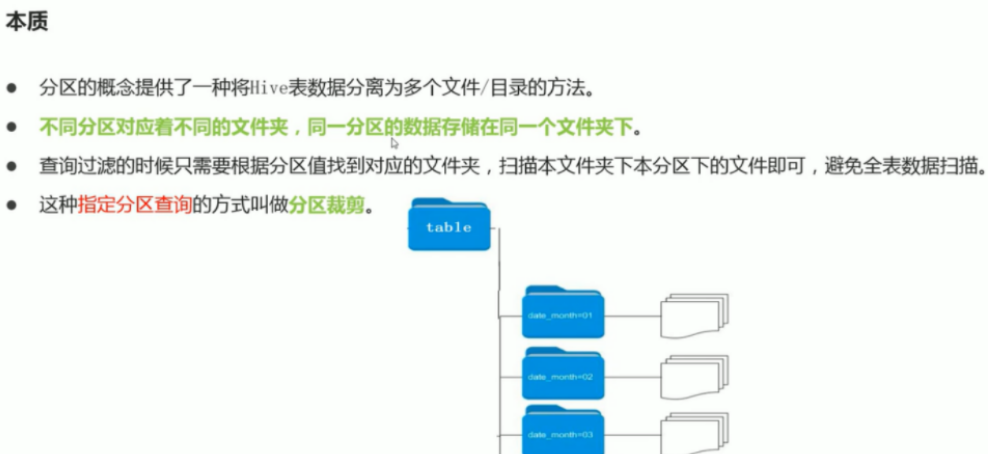
A partition in Hive is a subdirectory. It is basically consistent with the slice in map. Map slicing is also to improve parallelism. Open the data in the table separately. When you check the data in the table, write the partition information to avoid scanning the whole table; It is an optimized scheme.
The partition table is actually an independent folder corresponding to an HDFS file system. Under this folder are all the data files of the partition. The partition in Hive is a subdirectory, which divides a large data set into small data sets according to business needs. When querying, select the specified partition required by the query through the expression in the WHERE clause, which will greatly improve the query efficiency.
2. Create partition table
Note: the partition field cannot be the existing data in the table. The partition field can be regarded as a pseudo column of the table
create table stu1(name string, age int, score int) partitioned by (site string)
row format delimited fields terminated by ",";
3. Import data
3-1. Static partition
Note: the partition must be specified when the partition table loads data. This method of specifying is called static partition
3-1-1. Import from file
Note: only partitions can be specified
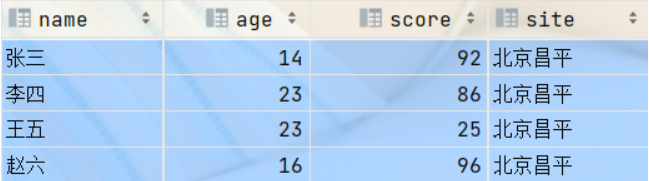
load data local inpath "/root/data/day11/stu.txt" into table stu1 partition (site = "Beijing Changping"); #Partition field data should be in the last position
3-1-2. Import from table
insert into stu1 partition (site="Puyang, Henan")
(select s.name, s.age, s.score from stu s where s.site = "Puyang, Henan");
3-2. Dynamic partition
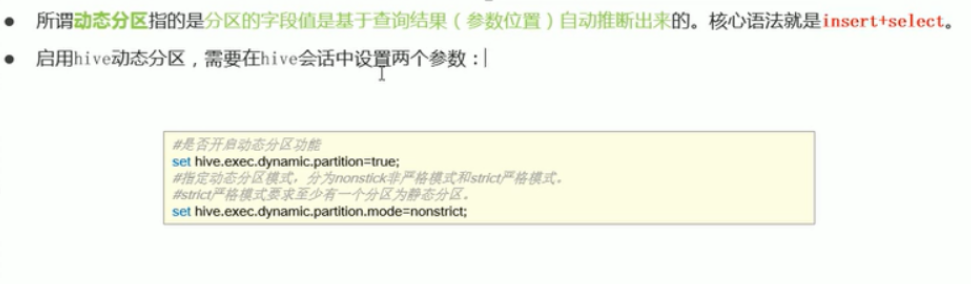
Sometimes we don't know which partition the data will go to from the beginning. The final data will enter the partition according to the query conditions. This is called dynamic partitioning. Therefore, the results must be found first and filled into the partition table. The previous load mode meets our needs.
Therefore, it is an insert+select mode;
insert into stu1 partition (site)
select s.name, s.age, s.score, s.site from stu s;
Note: the partition field is written at the top
Set to non strict mode (dynamic partition mode, strict by default), which means that at least one partition must be specified as a static partition, and non strict mode means that all partition fields are allowed to use dynamic partitions.
set hive.exec.dynamic.partition.mode="nonstrict";
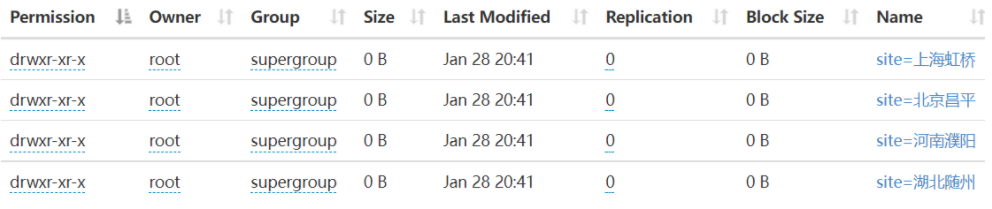
4. View partition
4-1 viewing the number of partitions
show partitions stu1;
4-2 view partition table structure
desc formatted stu1;
4-3 single partition view
select * from dept_partition where site='Henan';
4-2: union multi partition joint view
select * from dept_partition where site='Henan' union select * from dept_partition where site='Shandong' union select * from dept_partition where site='Hubei'; select * from dept_partition where site='Henan' or site='Shandong' or site='Hubei';
5. Secondary zoning
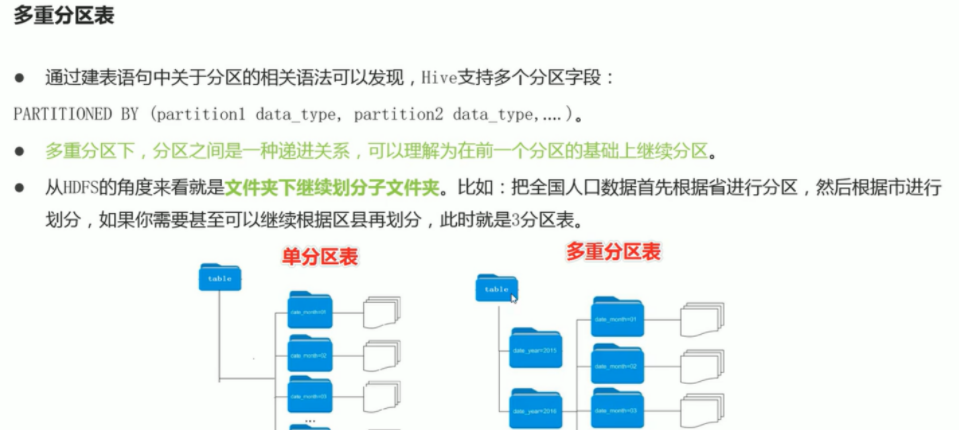
Build table
create table stu1(name string, age int, score int) partitioned by (state string, city string)
row format delimited fields terminated by ",";
Import data
insert into stu1 partition (state,city)
select s.name, s.age, s.score, s.state, s.city from stu s;
6. Add zoning
alter table stu1 add partition (state="China",city="Tianjin");
Add multiple partitions, separated by spaces:
alter table stu1 add partition (state="China",city="Tianjin") partition (state="China",city="Shandong");
7. Delete partition
alter table stu1 drop partition (state="China",city="Tianjin");
Delete multiple partitions, separated by commas
alter table stu1 drop partition (state="China",city="Tianjin"),partition (state="China",city="Shandong");