Hive tuning:
-
Choosing the appropriate "storage format" and "compression method" for the analyzed data can improve the analysis efficiency of hive
-
Data compression format:
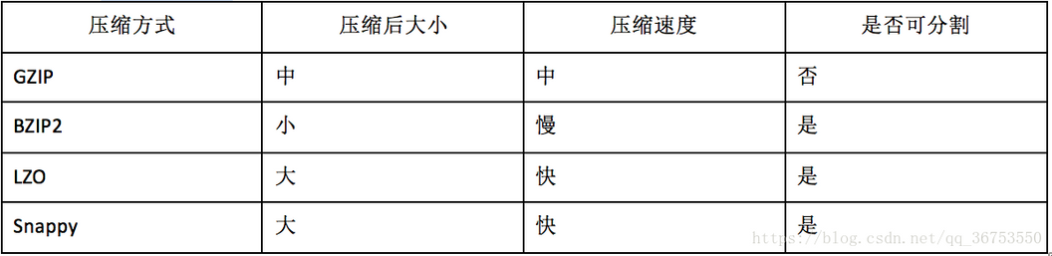
- When selecting a compression algorithm, you need to consider whether it can be divided, If segmentation is not supported (the integrity of a piece of data needs to be determined during slicing), a map needs to execute a file. If the file is large, the efficiency is very low. Generally, hdfs a block (128M) is the input slice of a map, and the block is physically cut, and a piece of data may be cut into two blocks
-
Storage format of data:
- TextFile (row storage, Gzip compression)
- The default format of Hive data table. Storage method: row storage. Gzip compression algorithm can be used, but the compressed file does not support split. In the process of deserialization, you must judge whether it is a delimiter and line terminator character by character. Therefore, the deserialization overhead will be dozens of times higher than that of SequenceFile.
- Sequence Files (row storage, NONE/RECORD/BLOCK compression)
- One of the disadvantages of some native compressed files in Hadoop is that it does not support segmentation. Split files can be processed by multiple mapper programs in parallel. Most files do not support splitting because these files can only be read from the beginning. Sequence File is a separable file format and supports Hadoop block level compression. A binary file provided by hadoop api, which is serialized into the file in the form of key value. Storage method: row storage. sequencefile supports three compression options: NONE, record and block. The compression ratio of record is low, and record is the default option. Generally, block will bring better compression performance than record. The advantage is that the file and MapFile in hadoop api are compatible
- RCFile (row column combined storage)
- Storage method: the data is divided into blocks by row, and each block is stored by column. It combines the advantages of row storage and column storage
- Firstly, RCFile ensures that the data of the same row is located at the same node, so the overhead of tuple reconstruction is very low. Secondly, like column storage, RCFile can use the data compression of column dimension and skip unnecessary column reading and data addition: RCFile does not support data writing in any way, but only provides an addition interface, This is because the underlying HDFS currently only supports adding data to the end of the file. Row group size: increasing the row group size helps to improve the efficiency of data compression, but may damage the data reading performance, because it increases the consumption of Lazy decompression performance. Moreover, row group change will occupy more memory, which will affect other MR jobs executed concurrently
- ORCFile (row column combined storage)
- Storage method: the data is divided into blocks according to rows, and each block is stored according to columns
- Fast compression, fast column access. The efficiency is higher than that of rcfile, which is an improved version of rcfile
- Parquet (row store)
- Parquet is also a kind of line storage with good compression performance; At the same time, it can reduce a lot of table scanning and deserialization time
- TextFile (row storage, Gzip compression)
-
-
Create partition table, bucket table and split table
-
Hive parameter optimization
-
Do not perform MR:
- When fetch task is hive, MapReduce does not need to be executed, such as select * from emp
Hive.fetch.task.conversion Default to minimal Modify profile hive-site.xml <property> <name>hive.fetch.task.conversion</name> <value>more</value> <description> Some select queries can be converted to single FETCH task minimizing latency.Currently the query should be single sourced not having any subquery and should not have any aggregations or distincts (which incurrs RS), lateral views and joins. 1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only 2. more : SELECT, FILTER, LIMIT only (+TABLESAMPLE, virtual columns) </description> </property> Or current session modify hive> set hive.fetch.task.conversion=more; implement SELECT id, money FROM m limit 10; Don't go mr -
Parallel execution:
- When there are multiple jobs in an sql and there is no dependency between the multiple jobs, the sequential execution can be changed to parallel execution (generally using union all)
// Enable parallel execution of tasks set hive.exec.parallel=true; // Maximum number of threads allowed for parallel tasks in the same sql set hive.exec.parallel.thread.number=8;
-
JVM reuse:
- JVM reuse has a great impact on hive's performance, especially in scenarios where it is difficult to avoid small files or where there are too many tasks. Most of these scenarios have a short execution time. The JVM startup process can cause considerable overhead, especially if the executed job contains thousands of task tasks.
- One disadvantage of JVM is that turning on JVM reuse will always occupy the used task slot for reuse, which can not be released until the task is completed. If several reduce tasks in an "unbalanced" job take much more time to execute than other reduce tasks, the reserved slots will remain idle but can not be used by other jobs until all tasks are completed
set mapred.job.reuse.jvm.num.tasks=10;
-
Set the number of reduce:
-
The setting of the number of reduce greatly affects the task execution efficiency. If the number of reduce is not specified, Hive will guess and determine a number of reduce based on the following two settings:
- hive.exec.reducers.bytes.per.reducer (amount of data processed by each reduce task)
- hive.exec.reducers.max (maximum number of reduce per task)
-
How to adjust the number of reduce:
- Adjust hive exec. reducers. bytes. per. The value of the reducer parameter
set hive.exec.reducers.bytes.per.reducer=500000000; (500M)
- Adjust mapred reduce. The value of the tasks parameter
set mapred.reduce.tasks = number
-
The number of reduce is not the more the better; Like map, starting and initializing reduce will consume time and resources; In addition, there will be many output files according to the number of reduce files. If many small files are generated, there will be too many small files if these small files are used as the input of the next task
-
-
-
Optimize SQL queries
-
where condition optimization:
- Before optimization (the relational database will be automatically optimized without consideration):
select m.cid,[u.id](http://u.id/) from order m join customer u on( m.cid =[u.id](http://u.id/) )where m.dt='20180808'
- After optimization (where conditions are executed on the map side instead of the reduce side):
select m.cid,[u.id](http://u.id/) from (select * from order where dt='20180818') m join customer u on( m.cid =[u.id](http://u.id/));
-
union Optimization:
- Try not to use Union (Union removes duplicate records), but use union all, and then use group by to remove duplicates
-
count distinct Optimization:
- Do not use count (distinct cloumn), use subquery
select count(1) from (select id from tablename group by id) tmp;
-
Replace join with in:
- If you need to constrain one table to another according to its fields, try to use in instead of join
select id,name from tb1 a join tb2 b on([a.id](http://a.id/) = [b.id](http://b.id/)); select id,name from tb1 where id in(select id from tb2); in Than join fast
-
Eliminate group by, COUNT(DISTINCT), MAX, MIN in the subquery. You can reduce the number of job s
-
join Optimization:
- When join ing small and large tables, putting the small table in front will be more efficient, and hive will cache the small table
-
-
Data skew:
-
Performance: the task progress is maintained at 99% (or 100%) for a long time. When viewing the task monitoring page, it is found that only a few (1 or several) reduce subtasks have not been completed, because the amount of data processed is too different from other reduce subtasks
-
Reason: the data input of a reduce is much larger than that of other reduce
- Uneven key distribution
- Characteristics of business data itself
- Improper consideration in table building
- Some SQL statements have data skew themselves

-
Solution:
- Parameter adjustment:
set hive.map.aggr=true //Partial aggregation at the map end, equivalent to combiner set hive.groupby.skewindata=true
- In the first MRJob, the output result set of Map will be randomly distributed to Reduce. Each Reduce performs partial aggregation operations and outputs results. The result of this processing is that the same GroupBy Key may be distributed to different Reduce, so as to achieve the purpose of load balancing
- The second MRJob is distributed to Reduce according to the group by key according to the preprocessed data results (this process can ensure that the same group by key is distributed to the same Reduce), and finally complete the final aggregation operation
-
Be familiar with data distribution, optimize SQL logic, and find the reason for data skew
-
-
Merge small files
-
There are three places to generate small files: map input, map output and reduce output. Too many small files will also affect hive's analysis efficiency:
- Set small file merge for map input:
set mapred.max.split.size=256000000; //The minimum size of split on a node (this value determines whether files on multiple datanodes need to be merged) set mapred.min.split.size.per.node=100000000; //The minimum size of split under a switch (this value determines whether files on multiple switches need to be merged) set mapred.min.split.size.per.rack=100000000; //Merge small files before executing Map set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
- Set relevant parameters for merging map output and reduce output:
//Set the map side output to merge. The default value is true set hive.merge.mapfiles = true //Set the reduce output to merge. The default value is false set hive.merge.mapredfiles = true //Sets the size of the merged file set hive.merge.size.per.task = 256*1000*1000 //When the average size of the output file is less than this value, start an independent MapReduce task to merge the file. set hive.merge.smallfiles.avgsize=16000000
-
-
To view the HQL execution plan:
- Explain SQL