Code environment: Windows 10 + Idea19-01 + spring-boot 2.1.6 + JDK1.8
jar package running environment: centos virtual machine + Hadoop 3.1.1 + hive3.1.1 + JDK1.8
Create a new spring-boot project in idea, including the basic ones. This project contains only one web package, as follows: pom.xml
The use of idea for udf operations must include hive and Hadoop-common packages, and must be the same version as in your cluster environment.
Be careful:
(1) All jar packages under lib of hive and hadoop-common-2.5.1.jar under share in Hadoop were added to the project (the latest version of Hadoop is 2.5.1).
(2) UDF class should inherit the class of org.apache.hadoop.hive.ql.exec.UDF. evaluate is implemented in the class.
When we use our own UDF in hive, hive calls the evaluate method in the class to implement specific functions
The export project is a jar file.
Note: The jdk of the project should be consistent with the jdk of the cluster.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.6.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.hello</groupId>
<artifactId>hive</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>hive</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>com.vaadin.external.google</groupId>
<artifactId>android-json</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--Add to hive rely on -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.1</version>
</dependency>
<!--Add to hadoop Rely on 2.7.3-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.1</version>
</dependency>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
Then create a new class GetCommentNameOrId
package com.hello.hive;
import org.apache.hadoop.hive.ql.exec.UDF;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetCommentNameOrId extends UDF {
//In a cluster, the udf operation of hive only runs the evaluate method
public String evaluate(String url,String flag){
String str = null;
Pattern p = Pattern.compile(flag+"/[a-zA-Z0-9]+");
Matcher m = p.matcher(url);
if(m.find()){
str = m.group(0).toLowerCase().split("/")[1];
}
return str;
}
public static void main(String[] args) {
String url = "http://cms.yhd.com/sale/vtxqCLCzfto?tc=ad.0.0.17280-32881642.1&tp=1.1.36.9.1.LEffwdz-10-35RcM&ti=ZX8H";
GetCommentNameOrId gs = new GetCommentNameOrId();
System.out.println(gs.evaluate(url,"sale"));
}
}
Then pack it with maven
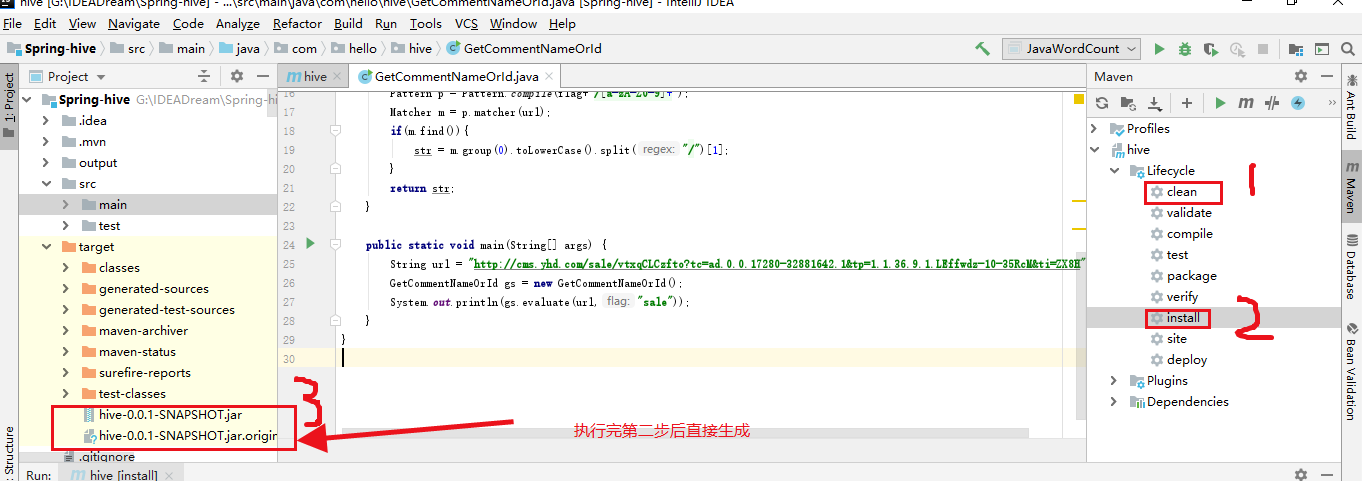
Generate two files, I use the second. original file, using this need to change the suffix to. jar, directly generated jar package, tested, I failed here.
After uploading the improved jar package to the virtual machine, the hive operation is successful.
Usage method
Run the start-dfs.sh cluster first, then hive
Operating in hive
1. Import jar packages into hive
add jar /**/**/**.jar;
2. Change the method name in the jar package to a simple temporary name
create temporary function GetComment as 'com.hello.hive.GetCommentNameOrId';
3. Check to see if methods are added to hive
show functions;
4. Using udf
select GetComment ("sdfas/vtxqCLCzfto? 782 dajkf", "sale") from a; //Create a data table of a before using a
create table a(a string);