OVER function
1. Meaning:
The window function is mainly used to open a window with a specified row range for each piece of data when analyzing the overall data;
over() specifies the size of the data window when the analysis function works. This window size may change with the change of the line;
Used for between... and... To indicate the range concept:
CURRENT ROW: CURRENT ROW
N predicting: data in the previous n rows
n FOLLOWING: data in the next n rows
UNBOUNDED: starting point,
Unbounded forecasting means from the previous starting point,
UNBOUNDED FOLLOWING indicates to the following end point
LAG(col,n,default_val): data in the nth row ahead
LEAD(col,n, default_val): data of the nth row in the future
NTILE(n): distribute the rows of the ordered window to the groups of the specified data. Each group has a number, starting from 1. For each row, NTILE returns the number of the group to which the row belongs. Note: n must be of type int.
Common formats:
over() will open a window for each data. The default window size is the size of the current dataset
over(partition by field) will partition according to the specified field, and divide the data with the same partition field value into the same partition; Each data in the partition opens a window. The default window size of each data is the size of the current partition dataset
over(order by field) will sort the data according to the specified field in the window; A window will be opened for each data. The default window size is unbounded forecasting from the dataset to the CURRENT ROW
over(partition by field order by field) will partition according to the specified field, divide the data with the same partition field value into the same partition, and sort according to the specified field in each partition; Each data in the partition opens a window. The default window size of each data is the current partition from unbounded forecasting to CURRENT ROW from the dataset
over(partition by field order by fields rows between... And...) will partition according to the specified fields, divide the data with the same partition field value into the same partition, and sort according to the specified fields in each partition; Each data in the partition opens a window, and the window size of each data is the specified window size
2. Example:
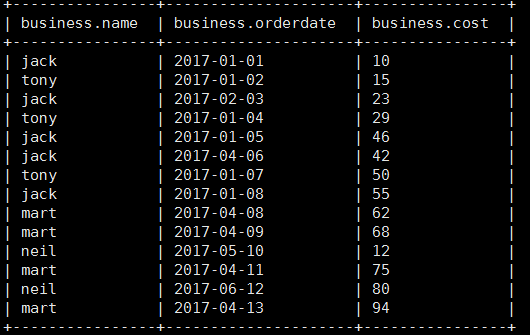
business table data:
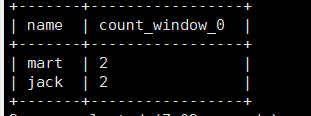
(1) Query the customers and total number of people who purchased in April 2017
select name,count(*) over () from business where substring(orderdate,1,7) = '2017-04' group by name;
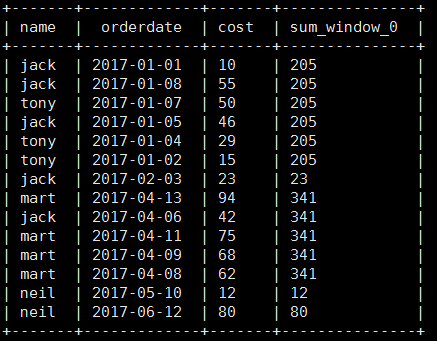
(2) Query the purchase details of customers and the total monthly purchase amount of all customers every month
select name,orderdate,cost,sum(cost) over(partition by month(orderdate)) from business;
Query the customer's purchase details and the monthly total purchase amount of each customer
select name,orderdate,cost,sum(cost) over(partition by name, substring(orderdate,0,7)) from business;
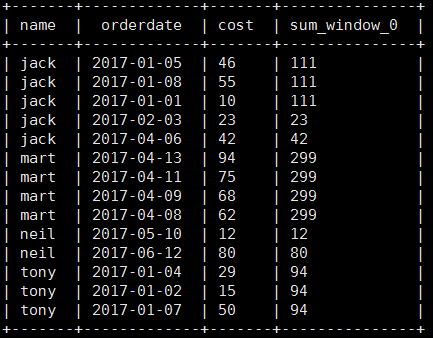
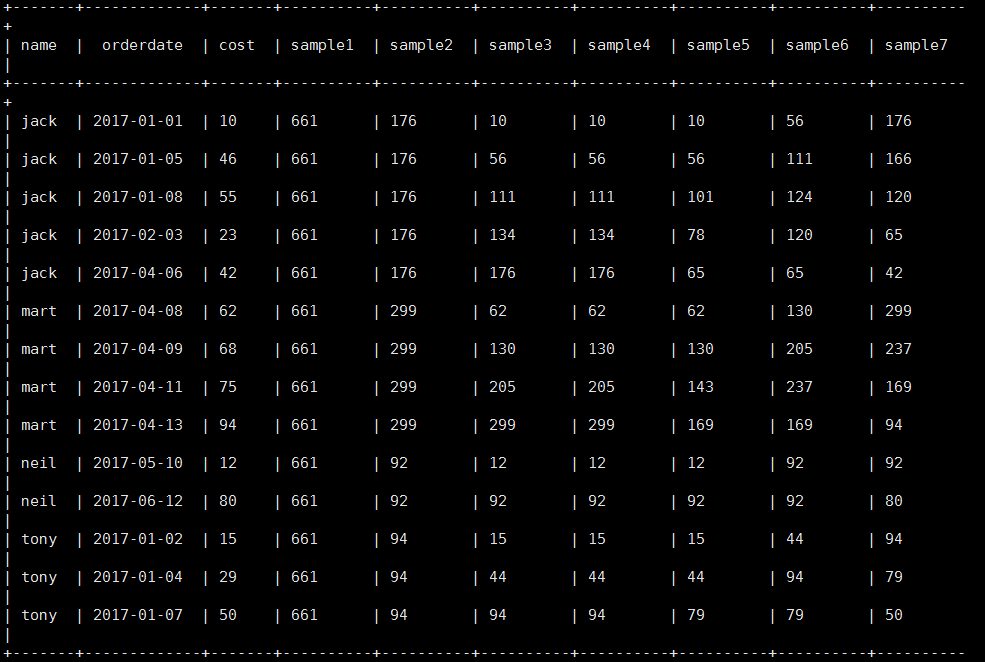
(3) The cost of each customer is accumulated according to the date
select name,orderdate,cost, sum(cost) over() as sample1,--Add all rows sum(cost) over(partition by name) as sample2,--Press name Grouping, intra group data addition sum(cost) over(partition by name order by orderdate) as sample3,--Press name Grouping, intra group data accumulation sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 ,--and sample3 equally,Aggregation from starting point to current row sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5, --Aggregate the current row with the previous row sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6,--The current line and the previous and subsequent lines sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7 --Current line and all subsequent lines from business;
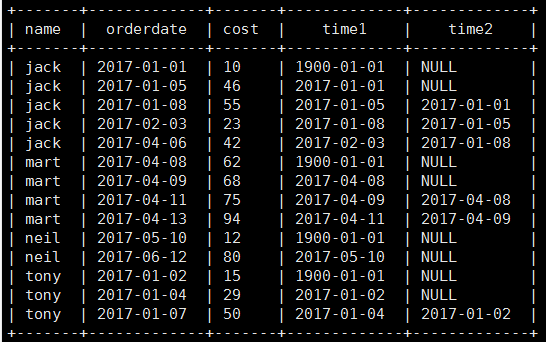
(4) Check the customer's last purchase time and the next purchase time
select name,orderdate,cost, lag(orderdate,1,'1900-01-01') over(partition by name order by orderdate ) as time1, lag(orderdate,2) over (partition by name order by orderdate) as time2 from business;
(5) Order information 20% before query
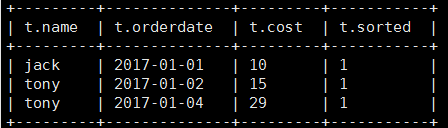
select * from (
select name,orderdate,cost, ntile(5) over(order by orderdate) sorted
from business
) t
where sorted = 1;