1, What is the window function
2, Window function classification
1, Cumulative calculation window function
1,sum() over()
It is often encountered in work to calculate the cumulative value up to a certain month. At this time, you need to use sum() to open the window
For example, give a transaction form_ trade:
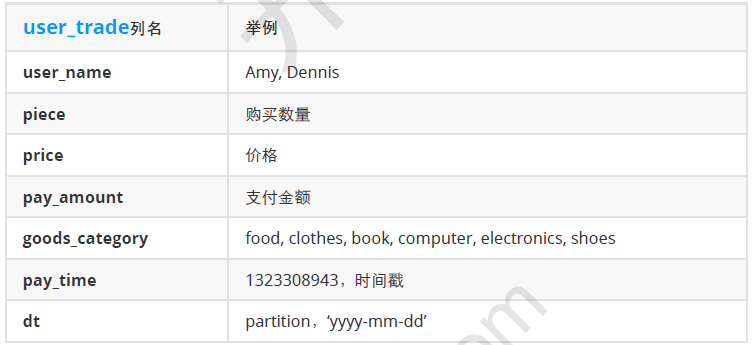
Now it is necessary to calculate the monthly total payment in 2018 and the cumulative total payment in the current year:
select
a.month,
a.pay_amount,
sum(pay_amount) over(order by month) pay_amount
from(
select
month(dt) month,
sum(pay_amount) pay_amount
from
user_trade
where year(dt)=2018
group by month(dt)
) a;
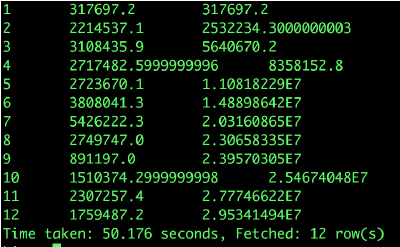
Now it is necessary to calculate the total monthly payment in 2017-2018 and the total cumulative payment in the current year:
select
a.year,
a.month,
a.pay_amount,
sum(a.pay_amount) over(partition by a.year order by a.month)
from
(
select
year(dt) year,
month(dt) month,
sum(pay_amount) pay_amount
from
user_trade
where year(dt) in (2017,2018)
group by year(dt),month(dt)
)a;
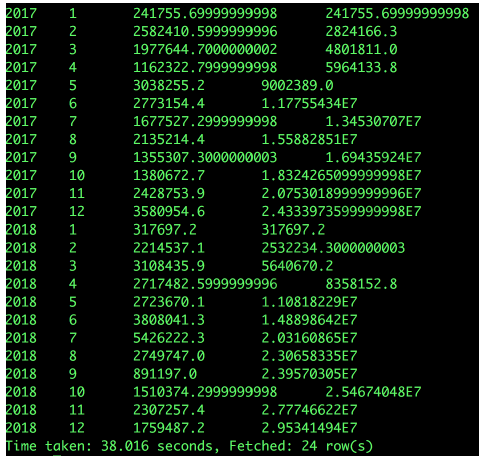
be careful:
1. partition by: plays the role of grouping
2. order by: in which order to accumulate, ascending ASC, descending DESC, and ascending by default
2,avg() over()
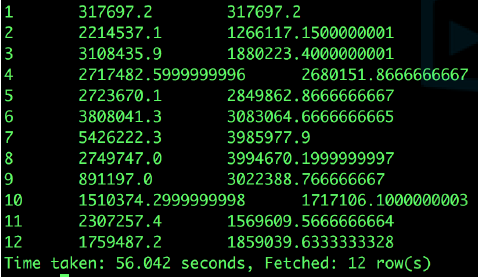
Now it is necessary to calculate the average payment amount of each month in 2018 in recent three months:
select
a.month,
a.pay_amount,
avg(a.pay_amount) over(order by a.month rows between 2 preceding and current row)
from
(select
month(dt) month,
sum(pay_amount) pay_amount
from
user_trade
where year(dt)=2018
group by month(dt)
)a;
3. Grammatical summary
sum(...A...) over(partition by ...B... order by ...C... rows between ...D1... and ...D2...)
avg(...A...) over(partition by ...B... order by ...C... rows between ...D1... and ...D2...)
A: Field name to be processed
B: Field name of the group
C: Sorted field name
D: Calculated rows range
rows between unbounded preceding and current row: includes this line and all previous lines
rows between current row and unbounded following: includes the current row and all subsequent rows
rows between 3 preceding and current row:
rows between 3 preceding and 1 following:
2, Partition sorting window function
There are three partition sorting window functions:
1,row_number() over(partition by A order by B)
2,rank() over(partition by A order by B)
3,dense_rank() over(partition by A order by B)
Where A represents the field name of the partition and B represents the field name of the sorting
Differences between the three:
row_number: it will generate a sequence number for each row of queried records, which will be sorted in order and will not be repeated
Rank: records with the same value after sorting are marked with the same sequence number. Adjacent different record values are added by 1 according to the number of previous same record values, that is, the sequence numbers after rank sorting are discontinuous
dense_rank: records with the same sorted value are marked with the same serial number. Adjacent records with different values are also marked with the previous serial number plus 1, that is, the sorted serial number is always continuous
Example: now it is necessary to calculate the ranking of the number of commodity categories purchased by users in January 2019
select
user_name,
count(distinct goods_category),
row_number() over(order by count(distinct goods_category)),
rank() over(order by count(distinct goods_category)),
dense_rank() over(order by count(distinct goods_category))
from
user_trade
where substr(dt,1,7)='2019-01'
group by user_name;

For example, select the users whose payment amount ranks 10th, 20th and 30th in 2019
select
a.user_name,
a.pay_amount,
a.rank
from
(
select
user_name,
sum(pay_amount) pay_amount,
rank() over(order by sum(pay_amount) desc) rank
from
user_trade
where year(dt)=2019
group user_name
)a where a.rank in (10,20,30);

3, Group sort window function
ntile(n) over(partition by ...A... order by ...B...)
n: Number of slices divided
A: Field name of the group
B: Sorted field name
be careful:
1. ntile(n): used to divide the packet data into n slices in order and return the current slice value
2. ntile does not support rows between
3. If the slices are not uniform, the distribution of the first slice is increased by default
For example, the payment users in January 2019 are divided into 5 groups according to the payment amount
select
user_name,
sum(pay_amount) pay_amount,
ntile(5) over(order by sum(pay_amount) desc) level
from
user_trade
where substr(dt,1,7)='2019-01'
group by user_name;

For example, select the top 10% users of refund amount in 2019
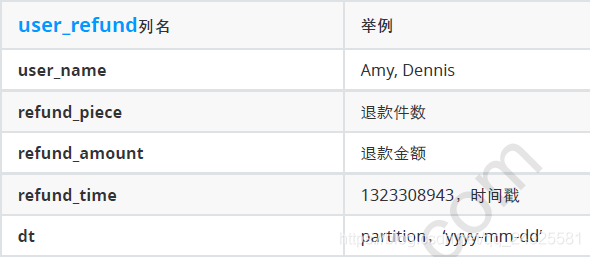
select
a.user_name,
a.refund_amount,
a.level
from
(
select
user_name,
sum(refund_amount) refund_amount,
ntile(10) over(order by sum(refund_amount) desc) level
from
user_refund
where year(dt)=2019
group by user_name
)a
where a.level=1;
4, Offset analysis window function
1,lag(...) over(...)
2,lead(...) over(...)
The Lag and Lead analysis functions can take the data (Lag) of the first N rows and the data (Lead) of the last N rows of the same field as independent columns in the same query.
In practical applications, the application of Lag and Lead functions is particularly important if you want to take the difference between a field today and yesterday.
lag(exp_str,offset,defval) over(partiton by ... order by ...)
lead(exp_str,offset,defval) over(partition by ... order by ...)
1,exp_str is the field name
2. Offset is the offset. When lag is used, if the current row is in row 5 in the table and offset is 3, it means that the data row we are looking for is row 2 in the table (i.e. 5-3 = 2). The default value is 1.
3. Defval is the default. When the two functions take the upper n or lower N values, when the number of N rows from the current row in the table has exceeded the range of the table, defval is used as the return value of the function. If no return value is specified, NULL is returned.
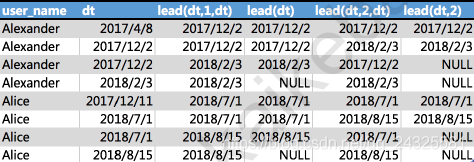
For example, various time offsets of users Alice and Alexander
1,lag()
select
user_name,
dt,
lag(dt,1,dt) over(partition by user_name order by dt),
lag(dt) over(partition by user_name order by dt),
lag(dt,2,dt) over(partition by user_name order by dt),
lag(dt,2) over(partition by user_name order by dt)
from
user_trade
where dt>'0' and user_name in ('Alice','Alexander');

2,lead()
select
user_name,
dt,
lead(dt,1,dt) over(partition by user_name order by dt),
lead(dt) over(partition by user_name order by dt),
lead(dt,2,dt) over(partition by user_name order by dt),
lead(dt,2) over(partition by user_name order by dt)
from
user_trade
where dt>'0' and user_name in ('Alice','Alexander');
Example: number of users whose payment interval exceeds 100 days
select
count(distinct user_name)
from
(
select
user_name,
dt,
lead(dt) over(partition by user_name order by dt) lead_dt
from
user_trade
where dt>'0'
)a
where a.lead_dt is not null
and datediff(a.lead_dt,a.dt)>100;
3, Practice
4, Reference articles
Some of the above data and sql refer to the video of the class bar, and the video link is lost
Hive window function