How to improve the classification accuracy of cifar-10 data set
1, Problem description
When dealing with image recognition or image classification or other machine learning tasks, we are always confused about what improvements can improve the performance of the model (recognition rate, classification accuracy)... Or what parameters are we adjusting in the long and painful process of adjusting parameters... Therefore, I spent part of my time exploring the public data set CIFAR-10 [1] to summarize a set of methods that can carry out network training and parameter adjustment quickly, efficiently and purposefully.
CIFAR-10 data set has 60000 pictures, and each picture is a color picture with a resolution of 32 * 32 (divided into RGB3 channels). The classification task of CIFAR-10 is to divide each picture into one of 10 categories, such as frog, truck and aircraft. This paper mainly uses the method based on convolutional neural network (codec) (CNN) to design the model and complete the classification task.
Firstly, in order to test the performance of the network while training the network, I divide the data set into training set / test set. The training set is mainly used for model training, and the test set is mainly used for model performance evaluation. Therefore, I divided the data set of 60000 samples into 50000 samples as the training set and 10000 samples as the test set. Next, we analyze step by step how to design and improve the model.
2, Build the most basic self encoder model
The self encoder structure is shown as follows: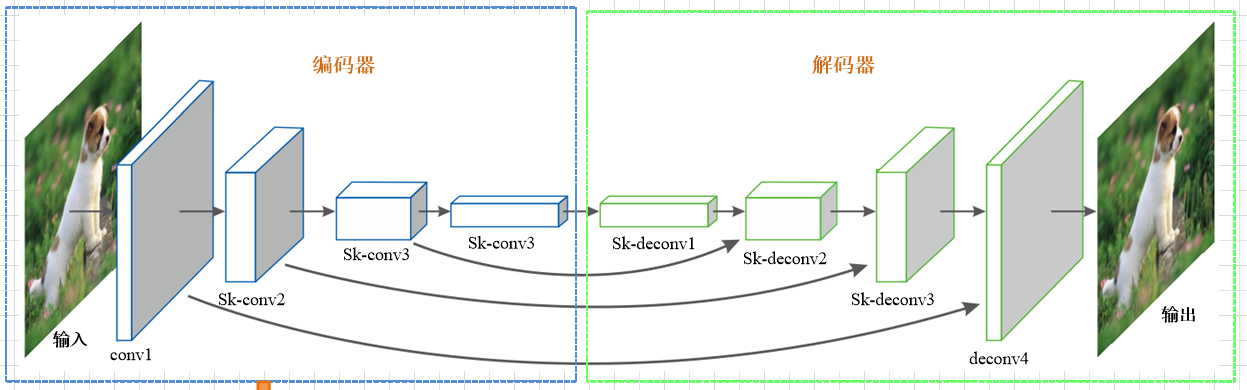
Detailed explanation of self encoder
For the model of deep learning, we must adopt the simplest model. On the one hand, we can quickly run a model to understand the difficulty of this task. On the other hand, we can have a baseline version of the model, which is conducive to comparative experiments. Therefore, I designed the following model according to my previous experience and the recommendation of netizens.
The input data of the model is the input of the network. It is a 4-dimensional tensor with the size of (batch_size, 32, 32, 3), which represents the number of pictures, the number of wide pixels 32, the number of high pixels 32 and the number of channels 3 respectively. Firstly, multiple convolution neural network layers are used for image feature extraction. The calculation process of convolution neural network layer is as follows:
Coding part **Convolution layer 1**: Convolution kernel size 3*3,The moving step of convolution kernel is 1, the number of convolution cores is 64, and the pool size is 2*2,Pool step 2, pool type is maximum pool, activate function ReLU. **Convolution layer 2**: Convolution kernel size 3*3,The moving step of convolution kernel is 1, the number of convolution cores is 128, and the pool size is 2*2,Pool step 2, pool type is maximum pool, activate function ReLU. **Convolution layer 3**: Convolution kernel size 3*3,The moving step of convolution kernel is 1, the number of convolution cores is 256, and the pool size is 2*2,Pool step 2, pool type is maximum pool, activate function ReLU. Coded output encoded(One dimensional): number of hidden layer units 1024, activation function ReLU. Decode input decoded:Dimension: 4*4*32,Activation function ReLU. Decoding part **Deconvolution layer 1**: Convolution kernel size 5*5,The moving step of convolution kernel is 1, the number of convolution cores is 32, and the pool size is 2*2,Pool step 2, pool type is maximum pool, activate function sigmoid. **Deconvolution layer 2**: Convolution kernel size 5*5,The moving step of convolution kernel is 1, the number of convolution cores is 16, and the pool size is 2*2,Pool step 2, pool type is maximum pool, activate function sigmoid. **Deconvolution layer 3**: Convolution kernel size 5*5,The moving step of convolution kernel is 1, the number of convolution kernels is 33, and the pool size is 2*2,Pool step 2, pool type is maximum pool, activate function sigmoid. Full connection layer: 512 neurons, activation function ReLU Classification layer: number of hidden layer units: 10, activation function softmax.
Parameter initialization, all weight matrices use tf.truncated_normal,All offset vectors use tf.constant(0.01, shape = shape). Loss function usage loss = tf.losses.sparse_softmax_cross_entropy(labels=y,logits=y_), use Adam The gradient descent method is used to update the parameters, and the learning rate is set to a fixed value of 0.001.
The network is a neural network with three-layer convolution layer and three-layer deconvolution layer. The convolution layer can quickly complete the feature extraction of the image. Deconvolution can effectively restore the image. The full connection layer is used to integrate the image features into classification features, and the classification layer is used for classification. In this way, our most basic version of CNN model has been built. Next, we will train and test to observe the results.
After 20000 rounds of training, the training accuracy, loss value and test accuracy are as follows:

Result analysis: the loss value decreased from 1.54 at the beginning to 0.11. In the whole training process, the loss value fluctuated back and forth, indicating that the model is unstable. Looking at the training accuracy and test accuracy, the training accuracy is 94%, while the test accuracy is only seventy-two.8%, which is obviously an over fitting phenomenon. The model is unstable and there is over fitting phenomenon, which shows that our model needs great improvement. Next, let's go on our parameter adjustment journey
3, Data enhancement can alleviate over fitting
Summary of data enhancement methods
Sometimes there are not enough training sets, or there are few data of a certain type, or in order to prevent over fitting and make the model more robust, in order to enrich the image training set, better extract image features and generalize the model (prevent model over fitting), the data image will generally be enhanced,
The commonly used methods of data enhancement are rotating the image, cutting the image, changing the color difference of the image, distorting the image features, changing the size of the image, enhancing the image noise (generally using Gaussian noise, salt pepper noise), etc
The image methods I use are:
1.**Then reverse**: Flip the image left and right. 2.**Adjust lighting**: Adjust the brightness of the picture 3.**Change contrast**: White picture(At its brightest)Brightness under divided by black picture(Darkest hour)The brightness of the; 4.**Image standardization**: Standardize images(Albino)Operation, that is, normalize the image itself to Gaussian(0,1) Distribution.
I add these four image enhancement methods into it and observe their loss value, training accuracy and test accuracy. The training results are as follows:

Result analysis: we found that the value of loss is still large, but it is relatively stable compared with the basic model, which is also a great progress. Looking at the training accuracy and test accuracy, the gap between training accuracy and test accuracy is relatively reduced, indicating that image enhancement can effectively alleviate over fitting, and the test accuracy has increased to nearly 78%, an increase of 5%, But we are still not satisfied, so we continue to optimize the model.
4, Improved model
Detailed explanation of various methods of improving the model to alleviate over fitting
Some optimization improvements are made from the perspective of the model. Due to the ever-changing improvement of a model for a specific problem, there is no way to try all of them
1,Attention mechanism: the so-called Attention Mechanism is the mechanism focusing on local information, Let the model focus more on this local information for training, for example, an image region in the image. As the task changes, the attention area often changes. 2,Dropout:The most commonly used regularization technique in deep learning is dropout,Let some neurons not participate in training, In short, it is to lose some neurons at random. This can prevent over fitting and improve the generalization ability of the model. 3,LRN: That is, the local response normalization layer, LRN Similar function Dropout And data enhancement as relu After activating the function A processing method to prevent over fitting of data. This function is rarely used and is basically similar Dropout In this way Method substitution. 4,Regularization: for the objective function, the regularization term is added to limit the number of weight parameters, which is a way to prevent over fitting Method, this method is actually in machine learning l2 Regularization method
In order to compare the experiment, only dropout was added in Experiment 1, dropout and LRN were added in Experiment 2, and all of them were added in Experiment 3.
The training accuracy and test accuracy results are as follows:
Experiment 1: dropout was added

Experiment 2: dropout and LRN were added
Experiment 3: add them all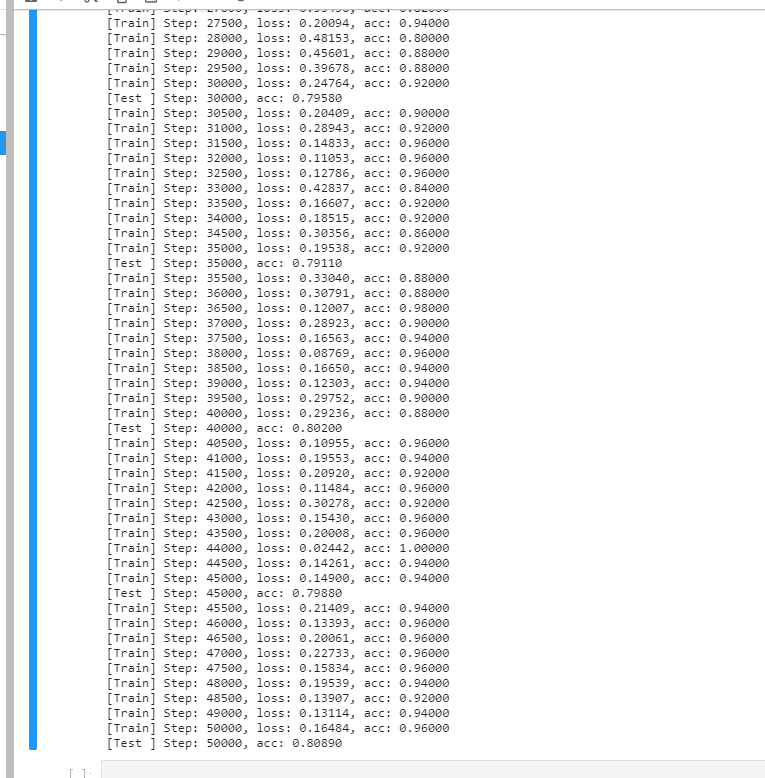
Result analysis: we observe the training accuracy and test accuracy. With the improvement of each model, the training set will be wrong The accuracy of difference and verification set has been improved Experiment one joined dropout Compared with the last test, the accuracy is improved by 1%,But the training accuracy and loss The value of has fluctuated up and down Large, indicating that the model is not stable enough. Experiment 2 was added again lrn,The test accuracy reached 80%Increased by 2%,Although the training is fine Some degrees can reach 1, but loss The value of fluctuates greatly up and down and is not very stable. Looking at Experiment 3, the test accuracy is slightly higher than that of Experiment 3 Points, but the training accuracy and loss The value of is relatively stable, indicating that the attention mechanism can strengthen the model training And can greatly improve the generalization ability of the model ***[notes]Because the attention mechanism is added, the model can reach the optimum when there are few rounds of training Increase the number of training rounds and observe whether the accuracy continues to improve***
5, Increase network depth
Therefore, in the case of sufficient computing resources, the most common idea to improve the performance of the model is to increase the depth of the network and let the deep neural network solve the problem. However, simple network stacking may not achieve good results. With the idea of deep learning, I did the next experiment.
Experiment 1: I expanded the number of convolution layers to 9 Experiment 2: Based on the 9-layer convolution, the deconvolution part was expanded to 6 layers Experiment 3: then I deepened the deconvolution to 7 layers and added an attention mechanism to the deconvolution part
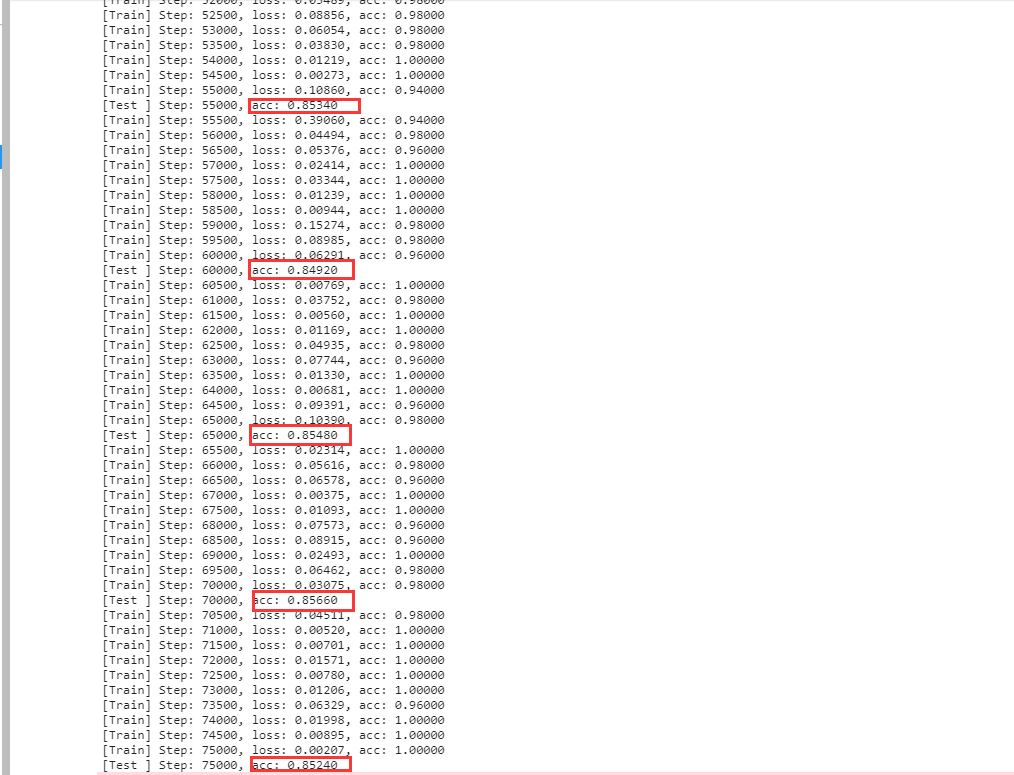
Experiment 1: 9-layer convolution + 3-layer deconvolution
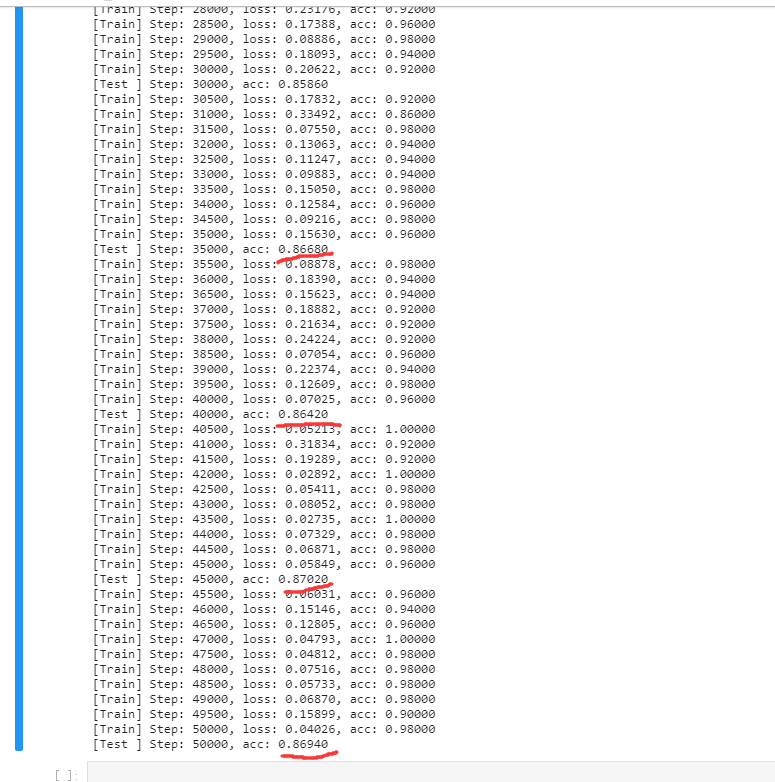
Experiment 2: 9-layer convolution + 6-layer deconvolution
Experiment 3: 9-layer convolution + 7-layer deconvolution + attention mechanism

Analysis results: In Experiment 2, after deepening the number of network layers, it is obvious that the test accuracy has reached 87%,Accuracy increased by 7%,In it In the experiment of deepening the number of network layers, the performance of the model does not increase but decreases, and the test accuracy decreases, which shows that if The number of network layers is too large, which leads to the decline of network performance due to gradient attenuation. Therefore, other methods need to be used Solve the gradient attenuation problem, so that the depth neural network can work normally work
6, Feature fusion (residual network)
Residual network is the ultimate weapon to improve accuracy. In 2015, Microsoft won ImageNet with residual network. This residual network solves the problem of gradient attenuation and enables the deep neural network to work normally. Due to the deepening of the number of network layers, the gradient will be continuously attenuated in the process of error back propagation. Through the direct edge across layers, the attenuation of error can be reduced in the process of back propagation, so that the deep-seated network can be successfully trained.
Here I use the Resnet50 network encapsulated in the keras module to splice and fuse the features trained by Resnet50 with the features trained by the existing model. There are two main fusion methods (1.concat,2.add)
I mainly use concat method here
The experimental results are as follows:

Result analysis: It can be seen from the figure that the test accuracy is increased by 1%
7, Summary
For CIFAR-10 image classification, we start with the simplest convolutional neural network, and the classification accuracy can only reach about 73%. By continuously increasing the methods to improve the model performance, the classification accuracy is finally improved to about 87.5%. The improvement of accuracy comes from the improvement of data, model and training process, The specific improvement of each item is shown in the table below.
Improvement method Test accuracy promote Basic model 72.8% 0 +Data enhancement 77.8% +5% +Model improvement 80.8% +3% +Model depth 86.7% +5.9% +Feature fusion 87.5% +0.9%
Among them, the data enhancement technology uses the methods of flipping image, cutting image and whitening image to increase the amount of data and the fitting ability of the model. Model improvement techniques include LRN, l2 regularization and dropout to prevent over fitting and increase the generalization ability of the model. Deepening the number of network layers and residual network technology can increase the fitting ability of the model by deepening the number of model layers and solving the problem of gradient attenuation. These improved methods stack step by step, step by step, making the fitting ability and generalization ability of the network stronger and stronger, and finally obtain higher classification accuracy.