Yunzhisheng Atlas team began to contact and follow up JuiceFS storage in early 2021, and has accumulated rich experience in Fluid use in the early stage. Recently, the cloud voice team and the jucedata team have jointly developed the Fluid jucedas acceleration engine, enabling users to better use the jucedas cache management capability in the Kubernetes environment. This article explains how to play Fluid + JuiceFS in the Kubernetes cluster.
Background introduction
Introduction to Fluid
CNCF Fluid is an open source Kubernetes native distributed dataset orchestration and acceleration engine, which mainly serves data intensive applications in cloud native scenarios, such as big data applications and AI applications. For more information about Fluid, you can Reference address.
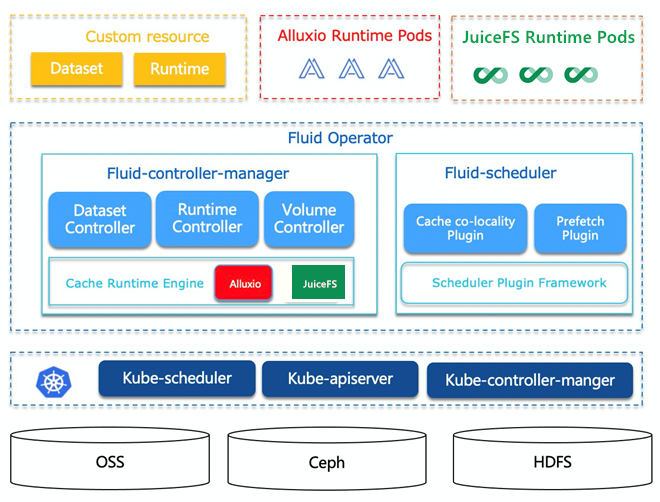
Fluid is not full storage acceleration and management, but data set acceleration and management used by applications. Fluid provides a more cloud native way to manage data sets. It caches the data of the underlying storage system in the memory or hard disk of the computing node through the cache acceleration engine, which solves the problem of low IO efficiency due to the limitation of data transmission bandwidth and the limitation of underlying storage bandwidth and IOPS capacity in the separation of computing and storage architecture. Fluid provides cache data scheduling capability. The cache is incorporated into kubernetes extended resources. Kubernetes can refer to the cache for scheduling policy allocation when scheduling tasks.
Fluid has two important concepts: Dataset and Runtime
- Dataset: a dataset is a set of logically related data. Consistent file characteristics will be used by the same operation engine.
- Runtime: the interface of the execution engine that implements the capabilities of dataset security, version management and data acceleration, and defines a series of life cycle methods.
Fluid's Runtime defines standardized interfaces. The Cache Runtime Engine can interface with a variety of cache engines, providing users with more flexible choices. Users can make full use of the cache engine to accelerate corresponding scenario applications according to different scenarios and requirements.
Introduction to JuiceFS
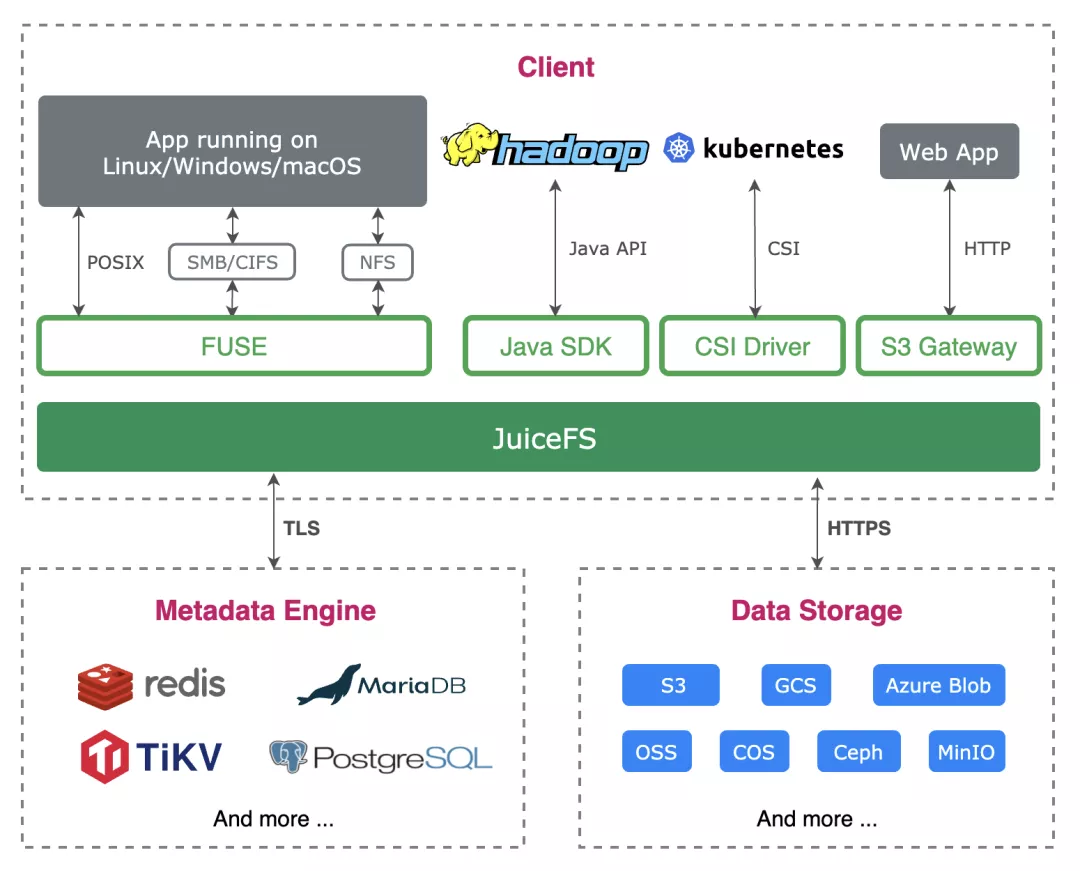
JuiceFS is a high-performance open source distributed file system designed for cloud environment. It is fully compatible with POSIX, HDFS and S3 interfaces. It is suitable for big data, AI model training, Kubernetes shared storage, massive data archiving management and other scenarios.
When JuiceFS is used to store data, the data itself will be persisted in object storage (for example, Amazon S3), and the metadata corresponding to the data can be persisted in Redis, MySQL, TiKV and other database engines according to the needs of the scenario. The JuiceFS client has data caching capability. When reading data through the JuiceFS client, these data will be intelligently cached to the local cache path configured by the application (either memory or disk), and the metadata will also be cached to the local memory of the client node.
For AI model training scenarios, after the first epoch is completed, subsequent calculations can directly obtain training data from the cache, which greatly improves the training efficiency. JuiceFS also has the ability of pre reading and concurrent data reading. In the AI training scenario, it can ensure the generation efficiency of each mini batch and prepare the data in advance. Data preheating can change the data on the public cloud to the local node in advance. For AI training scenarios, it can ensure that there is preheated data for operation after applying for GPU resources, saving time for valuable GPU use.
Why use the JuiceFSRuntime
As the underlying infrastructure, yunzhisheng Atlas supercomputing platform supports the company's model training and reasoning services in various fields of AI. Yunzhisheng has long begun to lay out and build the industry-leading GPU/CPU heterogeneous Atlas computing platform and distributed file storage system. The computing cluster can provide AI computing with high-performance computing and massive data storage and access capabilities. Yunzhisheng Atlas team began to contact and follow up JuiceFS storage in early 2021 and conducted a series of POC tests to meet our current needs in the adaptation of data reliability and business scenarios.
In the training scenario, we make full use of the caching capacity of the JuiceFS client to speed up the AI model training, but some problems are found in the use process:
- The training Pod is mounted through the hostpath. The JuiceFS client needs to be mounted on each computing node. The mounting needs to be operated by the administrator. The mounting parameters are fixed and not flexible enough.
- The user cannot manage the cache of the computing node client, and the cache cannot be cleaned and expanded manually.
- Cache datasets cannot be scheduled by kubernetes like kubernetes custom resources.
Since we have accumulated some experience in using Fluid in the production environment, we have worked with the jucedata team to design and develop the JuiceFSRuntime, which combines the data arrangement and management capabilities of Fluid with the caching capabilities of JuiceFS.
What is Fluid + JuiceFS (JuiceFSRuntime)
JuiceFSRuntime is a Runtime customized by Fluid, in which you can specify the worker, fuse image and corresponding cache parameters of JuiceFS. The construction method is consistent with other runtimes of Fluid, that is, it is built through CRD. The JuiceFSRuntime Controller monitors JuiceFSRuntime resources to realize cache Pod management.
JuiceFSRuntime supports nodeAffinity scheduling, selects appropriate cache nodes, supports lazy startup of Fuse pod, and supports users to access data through POSIX interface. At present, it only supports one mount point.
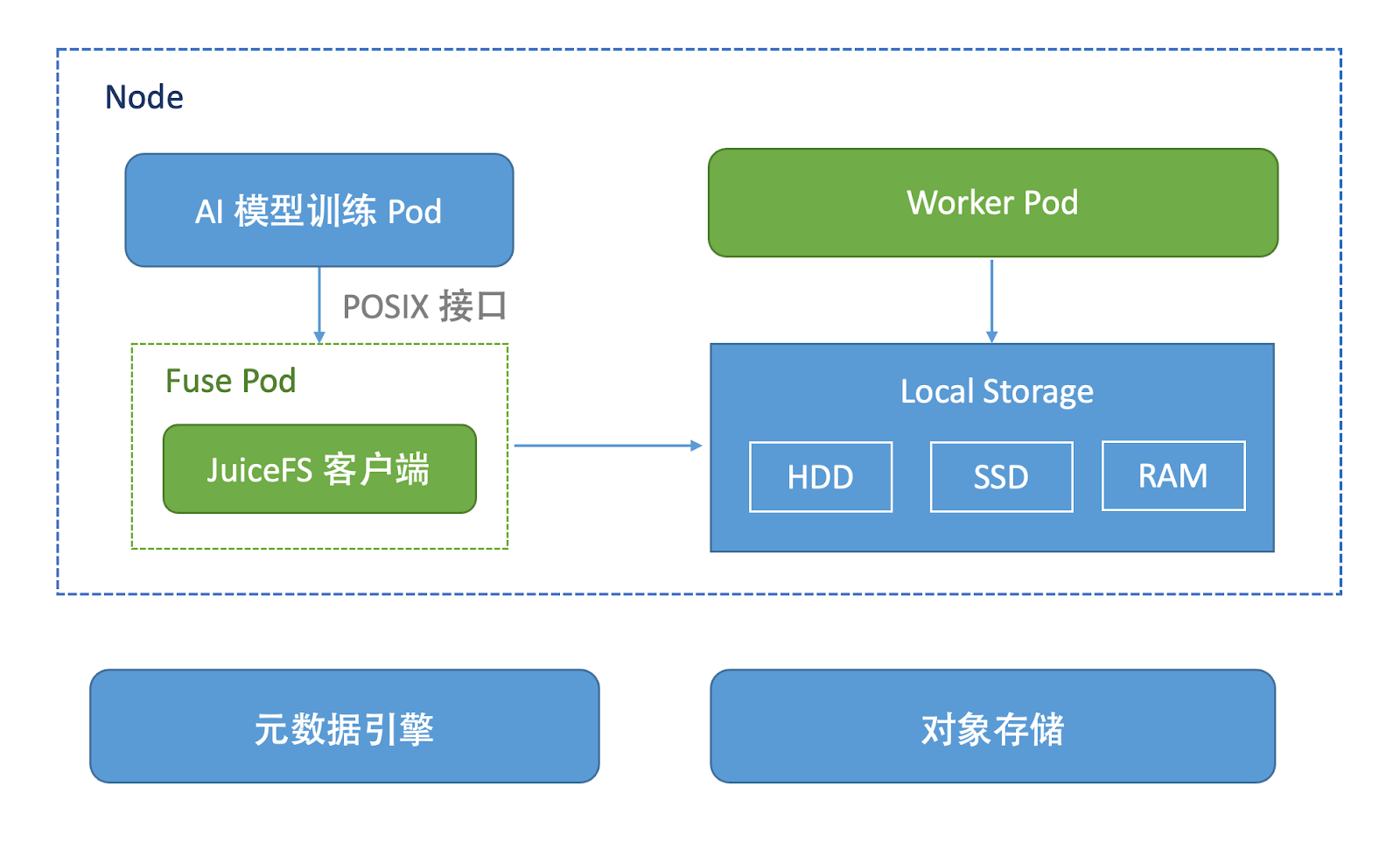
The frame composition is shown in the figure above. JuiceFSRuntime is composed of Fuse pod and Worker pod. Worker pod mainly implements cache management, such as cache cleaning when Runtime exits; Fuse pod is mainly responsible for parameter setting and mounting of JuiceFS client.
How to use juicefsruntime
Let's take a look at how to use the JuiceFSRuntime for cache acceleration.
preparation in advance
To use the juicefs runtime, you first need to prepare the metadata engine and object store.
Build metadata engine
Users can easily purchase cloud Redis databases with various configurations on the cloud computing platform. If it is used for evaluation and test, you can quickly run a Redis database instance on the server using Docker:
$ sudo docker run -d --name redis \ -v redis-data:/data \ -p 6379:6379 \ --restart unless-stopped \ redis redis-server --appendonly yes
Prepare object store
Like Redis database, almost all public cloud computing platforms provide object storage services. Because JuiceFS supports object storage services on almost all mainstream platforms, users can deploy them according to their own situations.
Here is the minio instance run by Dokcer that should be used for the evaluation test:
$ $ sudo docker run -d --name minio \
-p 9000:9000 \
-p 9900:9900 \
-v $PWD/minio-data:/data \
--restart unless-stopped \
minio/minio server /data --console-address ":9900"
The initial Access Key and Secret Key of the object store are minioadmin.
Download and install Fluid
according to file To install Fluid, set runtime.juicefs.enable to true in the installation chart values.yaml of Fluid, and install Fluid. Ensure that the Fluid cluster is running properly:
kubectl get po -n fluid-system NAME READY STATUS RESTARTS AGE csi-nodeplugin-fluid-ctc4l 2/2 Running 0 113s csi-nodeplugin-fluid-k7cqt 2/2 Running 0 113s csi-nodeplugin-fluid-x9dfd 2/2 Running 0 113s dataset-controller-57ddd56b54-9vd86 1/1 Running 0 113s fluid-webhook-84467465f8-t65mr 1/1 Running 0 113s juicefsruntime-controller-56df96b75f-qzq8x 1/1 Running 0 113s
Ensure that the juicefsruntime controller, dataset controller, pod of fluid webhook and several CSI nodeplug pods are running properly.
Create Dataset
Before using JuiceFS, you need to provide the parameters of metadata services (such as redis) and object storage services (such as minio), and create the corresponding secret:
kubectl create secret generic jfs-secret \
--from-literal=metaurl=redis://$IP: 6379 / 1 \ # the IP address of redis is the IP address of the node where redis is located
--from-literal=access-key=minioadmin \ # Object stored ak
--from-literal=secret-key=minioadmin #Object stored sk
Create Dataset yaml file
cat<<EOF >dataset.yaml
apiVersion: data.fluid.io/v1alpha1
kind: Dataset
metadata:
name: jfsdemo
spec:
mounts:
- name: minio
mountPoint: "juicefs:///demo"
options:
bucket: "<bucket>"
storage: "minio"
encryptOptions:
- name: metaurl
valueFrom:
secretKeyRef:
name: jfs-secret
key: metaurl
- name: access-key
valueFrom:
secretKeyRef:
name: jfs-secret
key: access-key
- name: secret-key
valueFrom:
secretKeyRef:
name: jfs-secret
key: secret-key
EOF
Because juicefs adopts local cache, the corresponding Dataset only supports one mount, and juicefs does not have UFS, the subdirectory to be mounted can be specified in the mountpoint ("juicefs: / /" is the root path) and will be mounted in the container as the root directory.
Create a Dataset and view the Dataset status
$ kubectl create -f dataset.yaml dataset.data.fluid.io/jfsdemo created $ kubectl get dataset jfsdemo NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE jfsdemo NotBound 44s
As shown above, the phase attribute value in status is NotBound, which means that the Dataset resource object has not been bound to any JuiceFSRuntime resource object. Next, we will create a JuiceFSRuntime resource object.
Create JuiceFSRuntime
Create a yaml file for the JuiceFSRuntime
$ cat<<EOF >runtime.yaml
apiVersion: data.fluid.io/v1alpha1
kind: JuiceFSRuntime
metadata:
name: jfsdemo
spec:
replicas: 1
tieredstore:
levels:
- mediumtype: SSD
path: /cache
quota: 40960 # The smallest unit of quota in JuiceFS is MiB, so here is 40GiB
low: "0.1"
EOF
Create and view the JuiceFSRuntime
$ $ kubectl create -f runtime.yaml juicefsruntime.data.fluid.io/jfsdemo created $ kubectl get juicefsruntime NAME WORKER PHASE FUSE PHASE AGE jfsdemo Ready Ready 72s
View the status of the related components Pod of JuiceFS
$$ kubectl get po |grep jfs jfsdemo-worker-mjplw 1/1 Running 0 4m2s
The JuiceFSRuntime does not have a master component, while the Fuse component implements lazy startup and will be created when the pod is used.
Create cache acceleration job
Create an application that needs to be accelerated. Pod uses the Dataset created above to specify a PVC with the same name
$ cat<<EOF >sample.yaml
apiVersion: v1
kind: Pod
metadata:
name: demo-app
spec:
containers:
- name: demo
image: nginx
volumeMounts:
- mountPath: /data
name: demo
volumes:
- name: demo
persistentVolumeClaim:
claimName: jfsdemo
EOF
Create Pod
$ kubectl create -f sample.yaml pod/demo-app created
View pod status
$ kubectl get po |grep demo demo-app 1/1 Running 0 31s jfsdemo-fuse-fx7np 1/1 Running 0 31s jfsdemo-worker-mjplw 1/1 Running 0 10m
You can see that the pod has been created successfully and the Fuse component of JuiceFS has been started successfully.
Enter the Pod and execute df -hT to check whether the cache directory is mounted:
$ kubectl exec -it demo-app bash -- df -h Filesystem Size Used Avail Use% Mounted on overlay 20G 14G 5.9G 71% / tmpfs 64M 0 64M 0% /dev tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup JuiceFS:minio 1.0P 7.9M 1.0P 1% /data
You can see that the cache directory has been successfully mounted.
Next, let's test the write function in the demo app pod:
$ kubectl exec -it demo-app bash [root@demo-app /]# df Filesystem 1K-blocks Used Available Use% Mounted on overlay 20751360 14585944 6165416 71% / tmpfs 65536 0 65536 0% /dev tmpfs 3995028 0 3995028 0% /sys/fs/cgroup JuiceFS:minio 1099511627776 8000 1099511619776 1% /data /dev/sda2 20751360 14585944 6165416 71% /etc/hosts shm 65536 0 65536 0% /dev/shm tmpfs 3995028 12 3995016 1% /run/secrets/kubernetes.io/serviceaccount tmpfs 3995028 0 3995028 0% /proc/acpi tmpfs 3995028 0 3995028 0% /proc/scsi tmpfs 3995028 0 3995028 0% /sys/firmware [root@demo-app /]# [root@demo-app /]# cd /data [root@demo-app data]# echo "hello fluid" > hello.txt [root@demo-app data]# cat hello.txt hello fluid
Finally, let's take a look at the caching function. Create a 1G file in the mount directory / data in the demo app pod, and then cp come out:
$ kubectl exec -it demo-app bash root@demo-app:~# dd if=/dev/zero of=/data/test.txt count=1024 bs=1M 1024+0 records in 1024+0 records out 1073741824 bytes (1.1 GB, 1.0 GiB) copied, 6.55431 s, 164 MB/s root@demo-app:~# time cp /data/test.txt ./test.txt real 0m5.014s user 0m0.003s sys 0m0.702s root@demo-app:~# time cp /data/test.txt ./test.txt real 0m0.602s user 0m0.004s sys 0m0.584s
From the execution results, it took 5s for the first cp and only 0.6s for the second cp because the cache already exists. The powerful caching capability provided by JuiceFS makes that as long as a file is accessed once, the file will be cached in the local cache path, and all subsequent repeated accesses will directly obtain data from JuiceFS.
Follow up planning
At present, JuiceFSRuntime does not support many functions, and we will continue to improve them in the future, such as Fuse Pod running in Nonroot mode and Dataload data preheating function.
Recommended reading: Zhihu x JuiceFS: use JuiceFS to start and accelerate the Flink container
If you are helpful, please pay attention to us Juicedata/JuiceFS Yo! (0ᴗ0✿)