How to rent AutoDL graphics card running project
Use steps
-
1. Rent new instance reference AutoDL-GPU rental platform tutorial,AutoDL quick start
-
2. Install the personal version of XShell 7 + xftp7. Be careful to download XShell first and then xftp, otherwise - 1603 fatal error will be reported during xftp download. reference resources XShell installation
-
3. Use XShell to connect to the server and xftp to upload the code to / root / Auto TMP, because the root directory is the system disk (20G) and auto TMP is the mount disk (100G)
-
4. Create and activate the virtual environment: (it is not recommended to install the environment directly under root)
conda create -n fire_environment python=3.7 # Build a virtual environment called fire_environment conda init bash && source /root/.bashrc # Update environment variables in bashrc conda activate fire_environment # Switch to the virtual environment you created: fire_environment conda info -e #View existing environment
reference resources Creating a virtual environment in anaconda,Notebook environment switching
-
5. Using Conda virtual environment in JupyterLab's notebook
# Add the new Conda virtual environment to jupyterab conda activate fire_environment # Switch to the virtual environment you created: fire_environment conda install ipykernel ipython kernel install --user --name=fire_environment # Set kernel, - user indicates the current user, fire_environment is the name of the virtual environment
reference resources Notebook environment switching
-
6. Tips for saving money
-
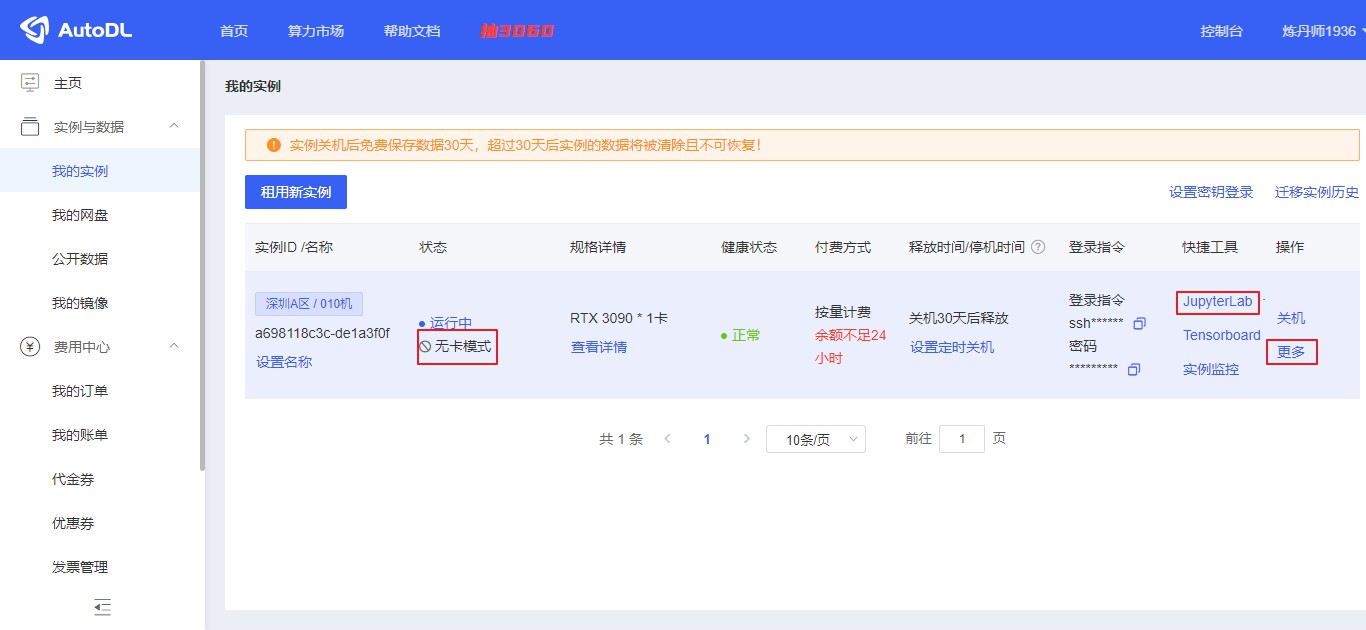
When configuring the project environment (the bandwidth is not enough and the download is time-consuming), you can start the project in card free mode at a cost of 0.1 yuan / hour (fortunately, there are vouchers at the beginning, otherwise you will die of regret)
-
Remember to turn off when you don't have to run the project, otherwise you will be charged on time.
-
It's best not to use it to run small projects before going to bed. The boot in card mode will deduct fees normally. It is recommended not to charge too much money at one time (just like forgetting to pull out the water card and deducting fees constantly).
-
-
7. TensorBoard usage: save the event file under the log folder in the project to / root / TF logs
Or switch the default log file path, refer to AutoDL uses Tensorboard
Trample pit
1. GPU 3090 is not suitable for cu101 version torch
-
Note that GPU 3090 does not adapt to the torch of cu101 version, and an error will be reported:
/root/miniconda3/envs/fire_environment/lib/python3.7/site-packages/torch/cuda/__init__.py:143: UserWarning: NVIDIA GeForce RTX 3090 with CUDA capability sm_86 is not compatible with the current PyTorch installation. The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_61 sm_70 sm_75 compute_37. If you want to use the NVIDIA GeForce RTX 3090 GPU with PyTorch, please check the instructions at https://pytorch.org/get-started/locally/ warnings.warn(incompatible_device_warn.format(device_name, capability, " ".join(arch_list), device_name))
-
Solution: install cuda11 Version 0 pytorch:
#Uninstall cuda (pytorch I installed with conda) conda uninstall pytorch conda uninstall libtorch pip install torch==1.7.0+cu110 torchvision==0.8.1+cu110 torchaudio===0.7.0 -f https://download.pytorch.org/whl/torch_stable.html
reference resources Adaptation between pytorch and gpu,cuda ubuntu installation_ 3090 graphics card + pytorch1 7 +cuda11. 0 + anconda installation
2. Opencv Python can support blend only after installing a lower version_ truth_ Mosaic function
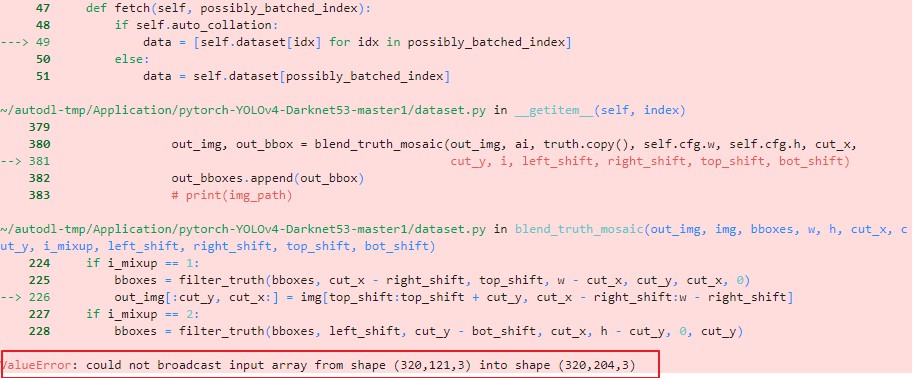
1. No matter on the virtual machine of GPU 3090 or the virtual machine of GPU 2080TI, running yolov4 project with CPU will report an error; However, in Colab's virtual environment, using CPU is no problem.
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
/tmp/ipykernel_21071/3778713862.py in <module>
626 config=cfg,
627 epochs=cfg.TRAIN_EPOCHS,
--> 628 device=device, )
629 except KeyboardInterrupt:
630 torch.save(model.state_dict(), 'INTERRUPTED.pth')
/tmp/ipykernel_21071/3778713862.py in train(model, device, config, epochs, batch_size, save_cp, log_step, img_scale)
370
371 with tqdm(total=n_train, desc=f'Epoch {epoch + 1}/{epochs}', unit='img', ncols=50) as pbar:
--> 372 for i, batch in enumerate(train_loader):
373 global_step += 1
374 epoch_step += 1
~/miniconda3/envs/fire_environment/lib/python3.7/site-packages/torch/utils/data/dataloader.py in __next__(self)
519 if self._sampler_iter is None:
520 self._reset()
--> 521 data = self._next_data()
522 self._num_yielded += 1
523 if self._dataset_kind == _DatasetKind.Iterable and \
~/miniconda3/envs/fire_environment/lib/python3.7/site-packages/torch/utils/data/dataloader.py in _next_data(self)
559 def _next_data(self):
560 index = self._next_index() # may raise StopIteration
--> 561 data = self._dataset_fetcher.fetch(index) # may raise StopIteration
562 if self._pin_memory:
563 data = _utils.pin_memory.pin_memory(data)
~/miniconda3/envs/fire_environment/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py in fetch(self, possibly_batched_index)
47 def fetch(self, possibly_batched_index):
48 if self.auto_collation:
---> 49 data = [self.dataset[idx] for idx in possibly_batched_index]
50 else:
51 data = self.dataset[possibly_batched_index]
~/miniconda3/envs/fire_environment/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py in <listcomp>(.0)
47 def fetch(self, possibly_batched_index):
48 if self.auto_collation:
---> 49 data = [self.dataset[idx] for idx in possibly_batched_index]
50 else:
51 data = self.dataset[possibly_batched_index]
~/autodl-tmp/Application/pytorch-YOLOv4-Darknet53-master1/dataset.py in __getitem__(self, index)
379
380 out_img, out_bbox = blend_truth_mosaic(out_img, ai, truth.copy(), self.cfg.w, self.cfg.h, cut_x,
--> 381 cut_y, i, left_shift, right_shift, top_shift, bot_shift)
382 out_bboxes.append(out_bbox)
383 # print(img_path)
~/autodl-tmp/Application/pytorch-YOLOv4-Darknet53-master1/dataset.py in blend_truth_mosaic(out_img, img, bboxes, w, h, cut_x, cut_y, i_mixup, left_shift, right_shift, top_shift, bot_shift)
224 if i_mixup == 1:
225 bboxes = filter_truth(bboxes, cut_x - right_shift, top_shift, w - cut_x, cut_y, cut_x, 0)
--> 226 out_img[:cut_y, cut_x:] = img[top_shift:top_shift + cut_y, cut_x - right_shift:w - right_shift]
227 if i_mixup == 2:
228 bboxes = filter_truth(bboxes, left_shift, cut_y - bot_shift, cut_x, h - cut_y, 0, cut_y)
ValueError: could not broadcast input array from shape (320,121,3) into shape (320,204,3)
Mainly the former is in blend_truth_mosaic function reports: opencv can't fragment image: XXX error. Check that the opencv Python version of colab is 4.1.2, while the opencv Python manually installed in the autodl virtual environment is 4.5.5. After modifying the cv2 in autodl to 4.1.2, you can run the yolov4 project and the project code( https://github.com/Tianxiaomo/pytorch-YOLOv4 ).
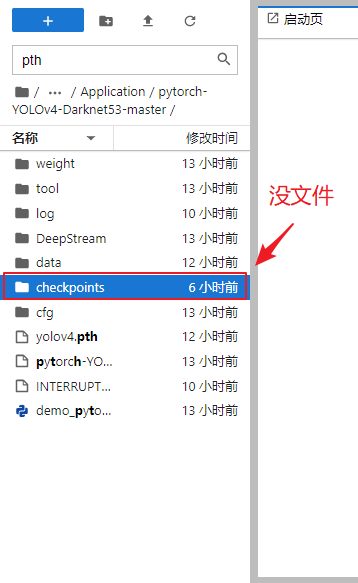
3. The weight file after training is not saved
The model trained last night (it cost me 10 RMB). When I got up in the morning, I found that the weight file (Yolo-v4.pth) of the model could not be found in the checkpoint folder. I guess the main reason is that only the same file was modified when saving the model weight file:
save_path = os.path.join(config.checkpoints, f'{save_prefix}.pth')
Instead of creating a new file (add an epoch before the file prefix)
save_path = os.path.join(config.checkpoints, f'{save_prefix + str(epoch)}.pth')
But I didn't have this problem on colab before. The weight file will be automatically saved in the mounted network disk.
save_path = os.path.join(config.checkpoints, f'{save_prefix}.pth')
if save_cp:
try:
# os.mkdir(config.checkpoints)
os.makedirs(config.checkpoints, exist_ok=True)
logging.info('Created checkpoint directory')
except OSError:
pass
# save_path = os.path.join(config.checkpoints, f'{save_prefix}.pth')
torch.save(model.state_dict(), save_path)
logging.info(f'Checkpoint {epoch + 1} saved !')
saved_models.append(save_path)
if len(saved_models) > config.keep_checkpoint_max > 0:
model_to_remove = saved_models.popleft()
try:
os.remove(model_to_remove)
except:
logging.info(f'failed to remove {model_to_remove}')
The background output result also shows that the weight file is saved successfully
IoU metric: bbox Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.079 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.173 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.061 Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.037 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.093 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.086 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.164 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.251 Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.256 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.283 2022-03-06 01:37:28,656 2316355449.py[line:449] INFO: Created checkpoint directory 2022-03-06 01:37:28,656 2316355449.py[line:449] INFO: Created checkpoint directory 2022-03-06 01:37:29,101 2316355449.py[line:454] INFO: Checkpoint 151 saved ! 2022-03-06 01:37:29,101 2316355449.py[line:454] INFO: Checkpoint 151 saved !
Verify assumptions:
1) Write the parameters of model training under each epoch into a new pth file (run 300 epochs here, each weight file 224M, and generate all files, accounting for about 300 x 224 / 1024 = 71.48GB), and then cd them to checkpoints through the console, You can view the weight file and write it successfully (note that you can't open the checkpoints folder under jupyterLab to view the file, which is told by AutoDL customer service and needs to be done after the console cd).
(base) root@container-a698118c3c-de1a3f0f:~/autodl-tmp/Application/pytorch-YOLOv4-Darknet53-master# cd checkpoints/ (base) root@container-a698118c3c-de1a3f0f:~/autodl-tmp/Application/pytorch-YOLOv4-Darknet53-master/checkpoints# ls Yolov4_epoch.pth Yolov4_epoch0.pth Yolov4_epoch1.pth (base) root@container-a698118c3c-de1a3f0f:~/autodl-tmp/Application/pytorch-YOLOv4-Darknet53-master/checkpoints#
2) Write the parameters of model training under each epoch into an original pth file (Yolov4.pth), and then cd to checkpoints through the console to check that the weight file is written successfully without loss. And after the shutdown, the weight file is still there.
(base) root@container-a698118c3c-de1a3f0f:~# cd /root/autodl-tmp/Application/pytorch-YOLOv4-Darknet53-master/ (base) root@container-a698118c3c-de1a3f0f:~/autodl-tmp/Application/pytorch-YOLOv4-Darknet53-master# cd checkpoints/ (base) root@container-a698118c3c-de1a3f0f:~/autodl-tmp/Application/pytorch-YOLOv4-Darknet53-master/checkpoints# ls Yolov4_epoch0.pth Yolov4_epoch1.pth Yolov4_epoch2.pth Yolov4_epoch3.pth Yolov4_epoch4.pth Yolov4_epoch5.pth Yolov4_epoch.pth
Now I can only make two guesses:
- Is it because my platform owes fees (0.31 yuan), which leads to the failure of weight file persistence;
- Or AutoDL has bugs in distributed storage and virtualization processing, which can not achieve high availability.
I won't verify the following two guesses. Anyway, this experience is careless.