I don't know if it's good or not. I'll try my best to tell it
Data synchronization
The previous article talked about using Sqoop to export the data of Mysql and Hdfs to each other.
This is the second chapter of offline warehouse. It is about the processing of business data.
The basic business data of offline data warehouse are stored in Mysql, and then the data in Mysql is transmitted to Hdfs through Sqoop.
Create a corresponding table in Hive and load the data of the corresponding directory into Hive table.
This is only the operation of ODS layer.
The data in ODS layer is basically the source data, which is the data closest to the business without modification and screening. About the ODS layer, I will write a blog about the ODS layer tomorrow. Never put it bad, always write it.
Different operations triggered by data synchronization
The key to data synchronization is that the data properties of each table are different. Each table is different.
First of all, the so-called e-commerce project stores the business in the Mysql table, but the table stored in Mysql is not a table, because one table cannot express all the e-commerce.
For example.
SPU is the smallest unit of commodity aggregation. An IPhone is a SPU
SKU, a silver Iphone with 256G memory, is SKU
Take Apple mobile phone for example. If you design an e-commerce table with apple mobile phone, one table is not enough.
First of all, apple mobile phones will be in the product list, which records the information of each mobile phone. That is, SKU.

The figure above is a simple example. There are various models behind an Apple phone. Manufacturer, delivery time. These are the attributes of Apple mobile phone, which are stored in the product information table.
Mobile phones are not only apple phones, but also other kinds of mobile phones, so Apple phones will still exist in the brand list.
E-commerce, e-commerce, every time you buy an Apple phone, that is, the so-called order, it will appear in the order form.
If the iPhone participates in the 618 discount, the iPhone will also appear in the activity information table
When the user receives the coupon, the money of the Apple phone the user finally buys is not the money that really goes to the e-commerce (the money refers to the profit). The original profit is 2000 yuan, because the coupon is used, another 400 yuan is less. The final profit is 1600 yuan.
How to import many tables into HDFS smoothly
An Apple phone involves so many tables. How to synchronize the data in Mysql to HDFS
Adopt different strategies.
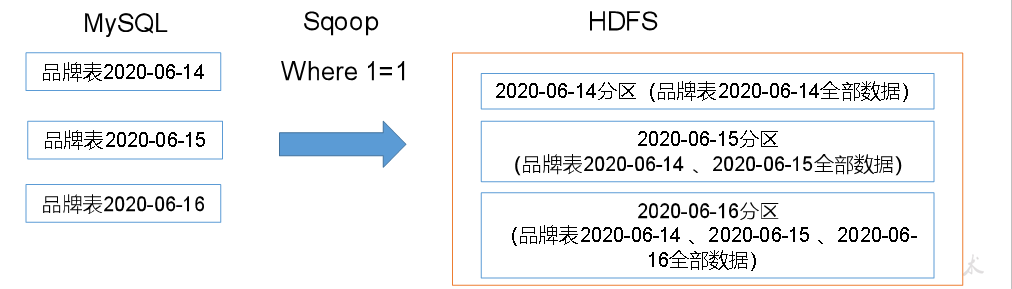
1. Daily full synchronization
Using this synchronization strategy is to synchronize all tables in Mysql every day.
The table with this strategy generally has a small amount of data, and the data will be added and reduced every day. We need to compare it all the time.
If Xiaomi's mobile phone participates in the activity of 500 discount for newcomers on January 27, 2022, Xiaomi has only one day and won't participate the next day. If Xiaomi mobile phone participates in this activity today, the data of Xiaomi mobile phone should be in the commodity activity table today, and the data of Xiaomi mobile phone should not be in the commodity activity table the next day.
This situation. The commodity activity table needs to be synchronized every day to determine which commodity participates in the activity on that day.
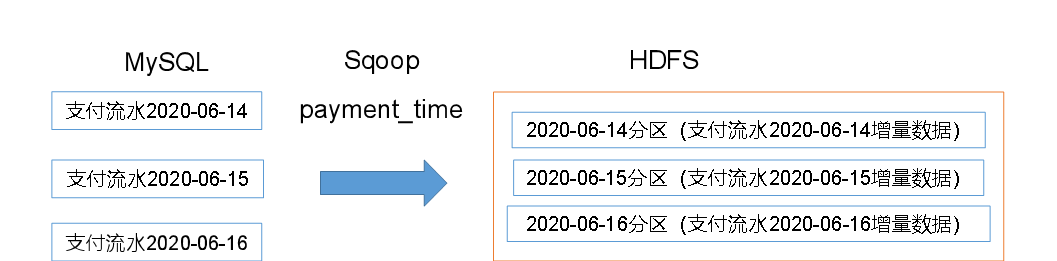
2. Incremental synchronization
Incremental synchronization is very simple. The newly added data is stored in the source table every day,
3. Store only once
This kind of table only needs to be synchronized once, and it will never need to be synchronized again.
List of provinces. This is an established fact and will not change
First synchronization of business data
The first time you synchronize data, you need to synchronize all business data.
Because there are many tables, we can't write one Sqoop statement at a time to synchronize one table, which is invalidation.
You can synchronize all business data or individual data by writing Shell scripts
#! /bin/bash
APP=gmall
sqoop=/opt/module/sqoop/bin/sqoop
if [ -n "$2" ] ;then do_date=$2
else
echo "Please pass in the date parameter"
exit
fi
import_data(){
$sqoop import \
--connect jdbc:mysql://hadoop102:3306/$APP \
--username root \
--password 000000 \
--target-dir /origin_data/$APP/db/$1/$do_date \
--delete-target-dir \ --query "$2 where \$CONDITIONS" \
--num-mappers 1 \ --fields-terminated-by '\t' \
--compress \ --compression-codec lzop \
--null-string '\\N' \ --null-non-string '\\N'
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /origin_data/$APP/db/$1/$do_date import_order_info(){ import_data order_info "select id, total_amount, order_status, user_id, payment_way, delivery_address, out_trade_no, create_time, operate_time, expire_time, tracking_no, province_id, activity_reduce_amount, coupon_reduce_amount, original_total_amount, feight_fee, feight_fee_reduce from order_info" }
case $1 in "order_info")
import_order_info ;;If you need to synchronize users_ Information in info table.
mysql_to_hdfs_init.sh user_info 2022-01-27
User in Mysql_ Synchronize info table to target dir / origin_ Data / $app / db / / 2022-01-07. The corresponding ods will be created in this directory later_ E-commerce_ user_info table
Daily synchronization of business data
Daily synchronization of business data is also script writing
After writing the script, you can synchronize the data.
The specific script can be read in the information of shangsilicon valley.
Summary:
This blog just explains the strategy of synchronizing tables from Mysql to hdfs.
Tomorrow, we will explain how to import the ods layer into the corresponding table, and filter and connect the tables. Put the required data into the dw layer.
Be sure to write a good article tomorrow