2021SC@SDUSC
1. Store domain data files (. fdt and. fdx)
Solr4. The format of fdt and fdx used in 8.0 is Lucene 4.0 1. In order to improve the compression ratio, StoredFieldsFormat compresses documents in 16KB units. The compression algorithm used is LZ4. Because it focuses more on speed than compression ratio, it can compress and decompress quickly.
1.1 storage domain data file (. fdt)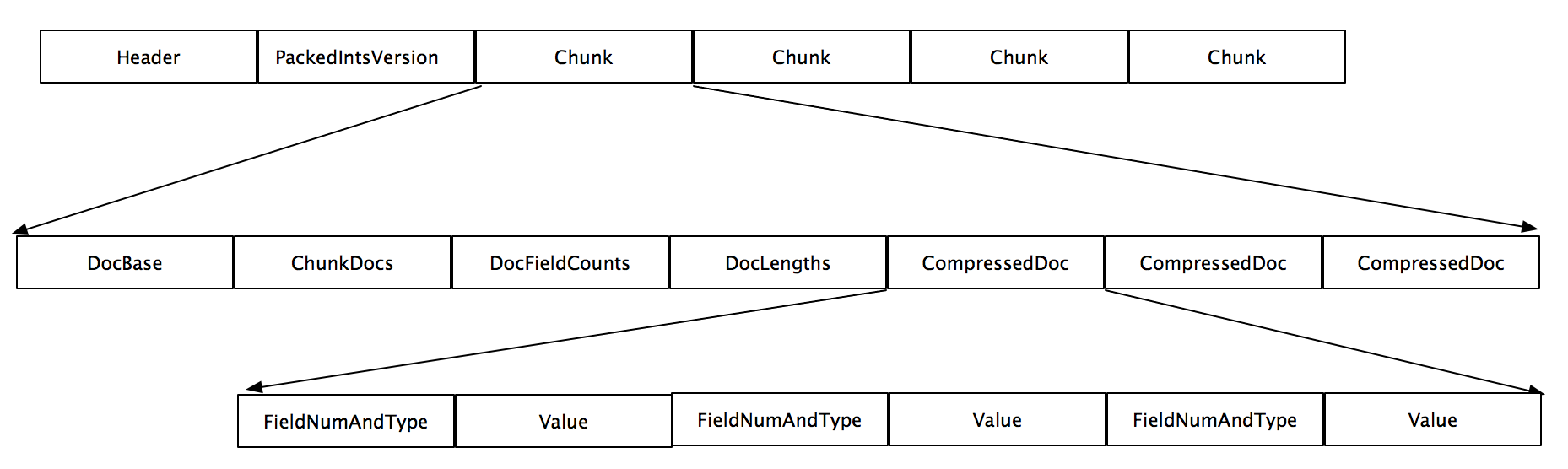
-
The stored field information is actually saved in the fdt file, which stores the compressed document and is compressed in units of 16kb or larger module size. When the segment is to be written, the documents will be stored in the memory buffer first. When the buffer size is greater than 16kb or more, these documents will be brushed into the disk and compressed in LZ4 format.
-
The fdt file is mainly composed of three parts: Header information, PacjedIntsVersion information, and multiple block chunk s.
-
fdt is compressed and decompressed in chunks. A chunk contains one or more document s
-
The chunk contains the number of the first document, namely DocBase, the number of documents in the block, namely ChunkDocs, the number of fields stored in each document, namely DocFieldCounts, the length of all documents in the block, namely DocLengths, and multiple compressed documents.
-
CompressedDoc consists of FieldNumAndType and Value. FieldNumAndType is a Vlong Type. Its lowest three digits represent Type, and other digits represent FieldNum, that is, field number.
-
Value corresponds to Type,
- 0: Value is String
- 1: Value is BinaryValue
- 2: Value is Int
- 3: Value is Float
- 4: Value is Long
- 5: Value is Double
- 6,: unused
-
If the document is larger than 16KB, only one document will exist in chunk. Because all fields of a document must be in the same chunk
-
If multiple documents in the chunk block are large and the chunk is larger than 32kb, the chunk will be compressed into multiple LZ4 blocks of 16KB size.
-
The structure does not support single documents larger than (231 - 214) bytes
StoredFieldsFormat inherits compressioningstoredfieldsformat, so learn how to solve Solr by learning compressioningstoredfieldsreader fdx and fdt
public CompressingStoredFieldsReader(Directory d, SegmentInfo si, String segmentSuffix, FieldInfos fn,
IOContext context, String formatName, CompressionMode compressionMode) throws IOException {
this.compressionMode = compressionMode;
final String segment = si.name;
boolean success = false;
fieldInfos = fn;
numDocs = si.getDocCount();
ChecksumIndexInput indexStream = null;
try {
//Open fdx name
final String indexStreamFN = IndexFileNames.segmentFileName(segment, segmentSuffix, FIELDS_INDEX_EXTENSION);
//Open fdt name
final String fieldsStreamFN = IndexFileNames.segmentFileName(segment, segmentSuffix, FIELDS_EXTENSION);
// Load the index into memory
//Analysis fdx file
indexStream = d.openChecksumInput(indexStreamFN, context);
//Get header
final String codecNameIdx = formatName + CODEC_SFX_IDX;
version = CodecUtil.checkHeader(indexStream, codecNameIdx, VERSION_START, VERSION_CURRENT);
assert CodecUtil.headerLength(codecNameIdx) == indexStream.getFilePointer();
//Start parsing blocks
indexReader = new CompressingStoredFieldsIndexReader(indexStream, si);
long maxPointer = -1;
if (version >= VERSION_CHECKSUM) {
maxPointer = indexStream.readVLong();
CodecUtil.checkFooter(indexStream);
} else {
CodecUtil.checkEOF(indexStream);
}
indexStream.close();
indexStream = null;
// Open the data file and read metadata
//Analysis fdt file
fieldsStream = d.openInput(fieldsStreamFN, context);
if (version >= VERSION_CHECKSUM) {
if (maxPointer + CodecUtil.footerLength() != fieldsStream.length()) {
throw new CorruptIndexException("Invalid fieldsStream maxPointer (file truncated?): maxPointer=" + maxPointer + ", length=" + fieldsStream.length());
}
} else {
maxPointer = fieldsStream.length();
}
this.maxPointer = maxPointer;
final String codecNameDat = formatName + CODEC_SFX_DAT;
final int fieldsVersion = CodecUtil.checkHeader(fieldsStream, codecNameDat, VERSION_START, VERSION_CURRENT);
if (version != fieldsVersion) {
throw new CorruptIndexException("Version mismatch between stored fields index and data: " + version + " != " + fieldsVersion);
}
assert CodecUtil.headerLength(codecNameDat) == fieldsStream.getFilePointer();
if (version >= VERSION_BIG_CHUNKS) {
chunkSize = fieldsStream.readVInt();
} else {
chunkSize = -1;
}
packedIntsVersion = fieldsStream.readVInt();
//Start parsing chunks
decompressor = compressionMode.newDecompressor();
this.bytes = new BytesRef();
success = true;
} finally {
if (!success) {
IOUtils.closeWhileHandlingException(this, indexStream);
}
}
}
1.2 storage domain index file (. fdx)
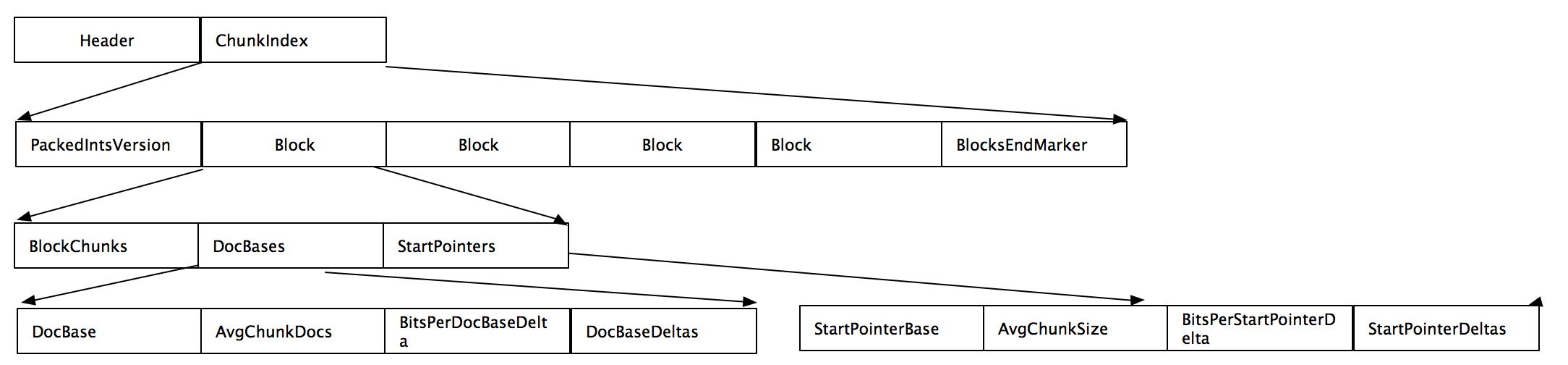
- BlockEndMarker: the value is 0, which means there is no Block followed. Because Block doesn't start with 0
- A Block here contains multiple chunks, and chunks correspond to each other The chunk of fdt. So it can be passed fdx quickly locates the The chunk of fdt.
- A block consists of three parts. BlockChunks represents the number of chunks contained in the block. DocBases represents the ID of the first document in the block and can be used to obtain the docbase of any chunk in the block. Similarly, StartPointer represents the number of chunks in the block Location information in fdt file.
- DocBases are composed of DocBase, AvgChunkDocs, BitsPerDocBaseDelta and docbasedelta. DocBase is the first document ID in the Block, AvgChunkDocs is the average number of documents in the Chunk, BitsPerDocBaseDelta is the difference with AvgChunkDocs, and docbasedelta is an array of BlockChunks, representing the difference of the average doc base.
- StartPointers consists of startpointerbase (the first pointer of the block, which corresponds to docbase), avgchunksize (the average size of chunks, which corresponds to AvgChunkDocs), BitPerStartPointerDelta and StartPointerDeltas
- The starting docbase of the nth chunk can be calculated with the following formula: DocBase + AvgChunkDocs * n + DocBaseDeltas[n]
- The starting point of the nth chunk can be calculated with the following formula: StartPointerBase + AvgChunkSize * n + StartPointerDeltas[n]
- . Compressioningstoredfieldsformat is mainly used for fdx file parsing. Take compressioningstoredfieldsindexreader as an example to see how to read fdx file:
// It is the responsibility of the caller to close fieldsIndexIn after this constructor
// has been called
CompressingStoredFieldsIndexReader(IndexInput fieldsIndexIn, SegmentInfo si) throws IOException {
maxDoc = si.getDocCount();
int[] docBases = new int[16];
long[] startPointers = new long[16];
int[] avgChunkDocs = new int[16];
long[] avgChunkSizes = new long[16];
PackedInts.Reader[] docBasesDeltas = new PackedInts.Reader[16];
PackedInts.Reader[] startPointersDeltas = new PackedInts.Reader[16];
//Read packedIntsVersion
final int packedIntsVersion = fieldsIndexIn.readVInt();
int blockCount = 0;
//Start traversing and reading all block s
for (;;) {
//numChunks is regarded as BlockChunks, indicating the number of Chunks in a Block; When the Block is read, a value of 0 will be read, that is, BlocksEndMarker,
//Indicates that all block s have been read.
final int numChunks = fieldsIndexIn.readVInt();
if (numChunks == 0) {
break;
}
//During initialization, the array docBases, startPointers, avgChunkDocs and avgchunksize with a size of 16 are defined to represent 16 modules.
//When the Block is greater than 16, a new size array will be generated and the original data will be copied.
if (blockCount == docBases.length) {
final int newSize = ArrayUtil.oversize(blockCount + 1, 8);
docBases = Arrays.copyOf(docBases, newSize);
startPointers = Arrays.copyOf(startPointers, newSize);
avgChunkDocs = Arrays.copyOf(avgChunkDocs, newSize);
avgChunkSizes = Arrays.copyOf(avgChunkSizes, newSize);
docBasesDeltas = Arrays.copyOf(docBasesDeltas, newSize);
startPointersDeltas = Arrays.copyOf(startPointersDeltas, newSize);
}
// doc bases
//Read docBase of block
docBases[blockCount] = fieldsIndexIn.readVInt();
//Read avgChunkDocs. The average number of document s in the chunk in the block
avgChunkDocs[blockCount] = fieldsIndexIn.readVInt();
//Read the number of bits of delta in bitsPerDocBase, block and avgChunkDocs, and obtain the specific Delta in docBasesDeltas array according to this number
final int bitsPerDocBase = fieldsIndexIn.readVInt();
if (bitsPerDocBase > 32) {
throw new CorruptIndexException("Corrupted bitsPerDocBase (resource=" + fieldsIndexIn + ")");
}
//Get the docBasesDeltas value. docBasesDeltas is an array with the size of numChunks, which stores the difference between the docbase at the beginning of each chunk and avgChunkDocs
docBasesDeltas[blockCount] = PackedInts.getReaderNoHeader(fieldsIndexIn, PackedInts.Format.PACKED, packedIntsVersion, numChunks, bitsPerDocBase);
// start pointers
//Read startPointers of block
startPointers[blockCount] = fieldsIndexIn.readVLong();
//Read the average size of startPointers and chunk s
avgChunkSizes[blockCount] = fieldsIndexIn.readVLong();
//Read the number of bits in bitsPerStartPointer, block and delta of avgChunkSizes, and obtain the specific Delta in startPointersDeltas array according to this number
final int bitsPerStartPointer = fieldsIndexIn.readVInt();
if (bitsPerStartPointer > 64) {
throw new CorruptIndexException("Corrupted bitsPerStartPointer (resource=" + fieldsIndexIn + ")");
}
//Get the value of startPointersDeltas, which is an array of numChunks,
//Store the difference between the startPointer at the beginning of each chunk and avgchunksize.
startPointersDeltas[blockCount] = PackedInts.getReaderNoHeader(fieldsIndexIn, PackedInts.Format.PACKED, packedIntsVersion, numChunks, bitsPerStartPointer);
//Next block
++blockCount;
}
//Put the traversed data into the global variable
this.docBases = Arrays.copyOf(docBases, blockCount);
this.startPointers = Arrays.copyOf(startPointers, blockCount);
this.avgChunkDocs = Arrays.copyOf(avgChunkDocs, blockCount);
this.avgChunkSizes = Arrays.copyOf(avgChunkSizes, blockCount);
this.docBasesDeltas = Arrays.copyOf(docBasesDeltas, blockCount);
this.startPointersDeltas = Arrays.copyOf(startPointersDeltas, blockCount);
}