1 function overview
Like the standard SQL syntax in RDBMS, Hive SQL also has many built-in functions to meet the data analysis needs of users on different occasions and improve the efficiency of developing SQL data analysis.
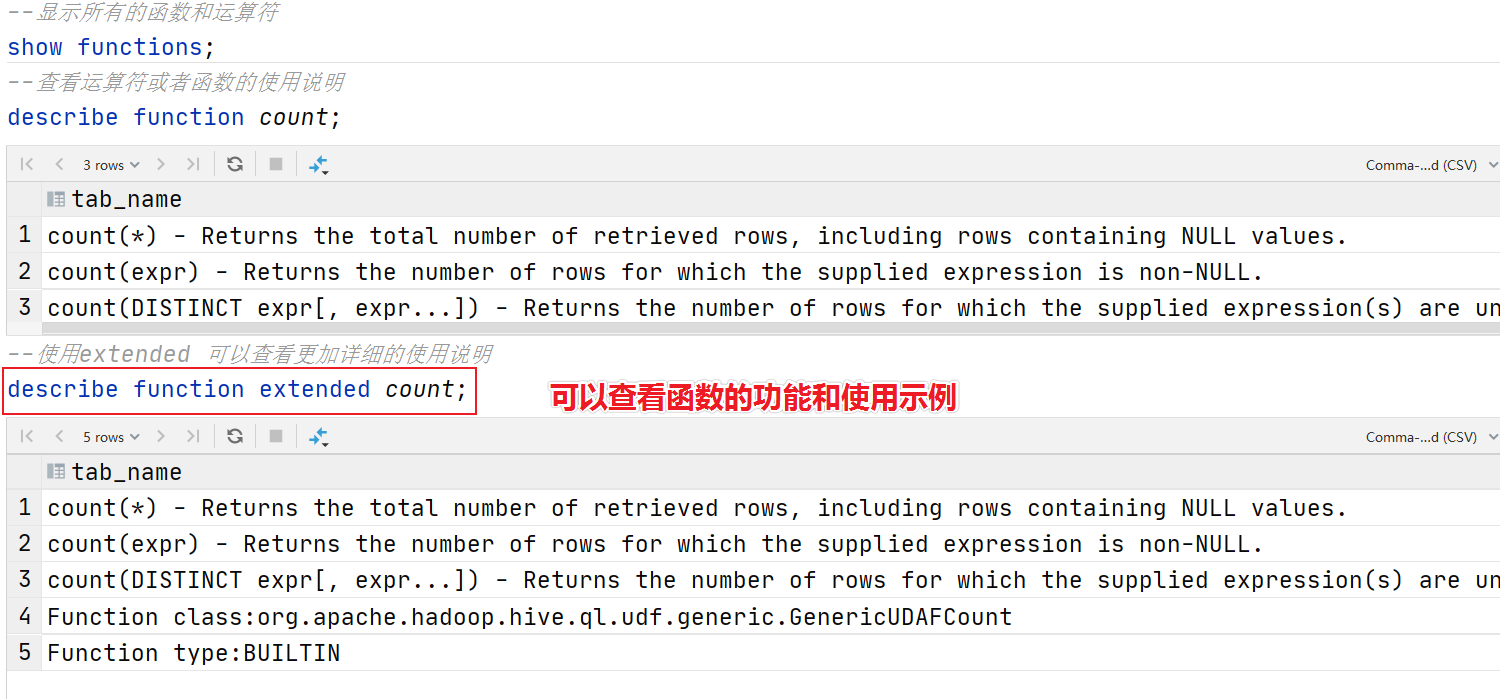
You can use show functions to view the functions supported by the current version, and you can use describe function extended funcname to view the use methods and methods of functions.
2 function classification
Hive has many functions. In addition to its built-in supported functions, it also supports users to define and develop functions themselves.
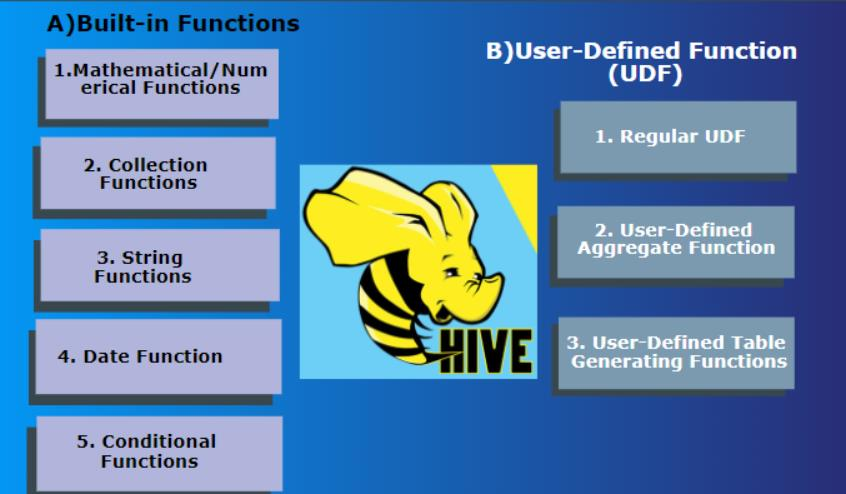
Built in functions can be summarized and classified according to their application types, such as numeric type functions, date type functions, string type functions, set functions, condition functions, etc;
User defined functions can be classified according to the number of input and output lines of the function, such as UDF, UDAF and UDTF.
2.1 built in function classification
The so-called built-in function refers to the function that Hive has developed and implemented and can be used directly, which is also called built-in function.
Official document address: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
The built-in functions can be divided into the following 8 types according to the application. We will explain in detail the use of important and frequently used functions.
2.1.1 String Functions
It mainly operates on string data types, such as the following:
•String length function: length •String inversion function: reverse •String concatenation function: concat •Delimited string concatenation function: concat_ws •String interception function: substr,substring •String to uppercase function: upper,ucase •String to lowercase function: lower,lcase •De whitespace function: trim •Function to remove space on the left: ltrim •Function to remove space on the right: rtrim •Regular expression replacement function: regexp_replace •Regular expression parsing function: regexp_extract •URL Parse function: parse_url •json Parse function: get_json_object •Space string function: space •Duplicate string function: repeat •First character ascii Function: ascii •Left complement function: lpad •Right complement function: rpad •Split string function: split •Collection lookup function: find_in_set
------------String Functions String function------------
describe function extended find_in_set;
--String length function: length(str | binary)
select length("angelababy");
--String inversion function: reverse
select reverse("angelababy");
--String concatenation function: concat(str1, str2, ... strN)
select concat("angela","baby");
--Delimited string concatenation function: concat_ws(separator, [string | array(string)]+)
select concat_ws('.', 'www', array('itcast', 'cn'));
--String interception function: substr(str, pos[, len]) perhaps substring(str, pos[, len])
select substr("angelababy",-2); --pos Is the index starting from 1. If it is negative, it is inverted
select substr("angelababy",2,2);
--String to uppercase function: upper,ucase
select upper("angelababy");
select ucase("angelababy");
--String to lowercase function: lower,lcase
select lower("ANGELABABY");
select lcase("ANGELABABY");
--De whitespace function: trim Remove the left and right spaces
select trim(" angelababy ");
--Function to remove space on the left: ltrim
select ltrim(" angelababy ");
--Function to remove space on the right: rtrim
select rtrim(" angelababy ");
--Regular expression replacement function: regexp_replace(str, regexp, rep)
select regexp_replace('100-200', '(\\d+)', 'num');
--Regular expression parsing function: regexp_extract(str, regexp[, idx]) Extract the content of the specified group matched by the regular
select regexp_extract('100-200', '(\\d+)-(\\d+)', 2);
--URL Parse function: parse_url Note that if you want to parse multiple at a time, you can use parse_url_tuple this UDTF function
select parse_url('http://www.itcast.cn/path/p1.php?query=1', 'HOST');
--json Parse function: get_json_object
--Space string function: space(n) Returns the specified number of spaces
select space(4);
--Duplicate string function: repeat(str, n) repeat str character string n second
select repeat("angela",2);
--First character ascii Function: ascii
select ascii("angela"); --a corresponding ASCII 97
--Left complement function: lpad
select lpad('hi', 5, '??'); --???hi
select lpad('hi', 1, '??'); --h
--Right complement function: rpad
select rpad('hi', 5, '??');
--Split string function: split(str, regex)
select split('apache hive', '\\s+');
--Collection lookup function: find_in_set(str,str_array)
select find_in_set('a','abc,b,ab,c,def');
2.1.2 Date Functions
It mainly operates on time and date data types, such as the following:
•Get current date: current_date •Get current timestamp: current_timestamp •UNIX Timestamp to date function: from_unixtime •Get current UNIX Timestamp function: unix_timestamp •Date transfer UNIX Timestamp function: unix_timestamp •Specify format date UNIX Timestamp function: unix_timestamp •Extract date function: to_date •Date to year function: year •Date to month function: month •Date conversion function: day •Date to hour function: hour •Date to minute function: minute •Date to second function: second •Date to week function: weekofyear •Date comparison function: datediff •Date addition function: date_add •Date reduction function: date_sub
--Get current date: current_date
select current_date();
--Get current timestamp: current_timestamp
--Pair in the same query current_timestamp All calls to return the same value.
select current_timestamp();
--Get current UNIX Timestamp function: unix_timestamp
select unix_timestamp();
--UNIX Timestamp to date function: from_unixtime
select from_unixtime(1618238391);
select from_unixtime(0, 'yyyy-MM-dd HH:mm:ss');
--Date transfer UNIX Timestamp function: unix_timestamp
select unix_timestamp("2011-12-07 13:01:03");
--Specify format date UNIX Timestamp function: unix_timestamp
select unix_timestamp('20111207 13:01:03','yyyyMMdd HH:mm:ss');
--Extract date function: to_date
select to_date('2009-07-30 04:17:52');
--Date to year function: year
select year('2009-07-30 04:17:52');
--Date to month function: month
select month('2009-07-30 04:17:52');
--Date conversion function: day
select day('2009-07-30 04:17:52');
--Date to hour function: hour
select hour('2009-07-30 04:17:52');
--Date to minute function: minute
select minute('2009-07-30 04:17:52');
--Date to second function: second
select second('2009-07-30 04:17:52');
--Date to week function: weekofyear Returns the week ordinal of the year indicated by the specified date
select weekofyear('2009-07-30 04:17:52');
--Date comparison function: datediff Date format requirements'yyyy-MM-dd HH:mm:ss' or 'yyyy-MM-dd'
select datediff('2012-12-08','2012-05-09');
--Date addition function: date_add
select date_add('2012-02-28',10);
--Date reduction function: date_sub
select date_sub('2012-01-1',10);
3.2.1.3 Mathematical Functions
Mathematical calculation is mainly carried out for numerical data, such as the following:
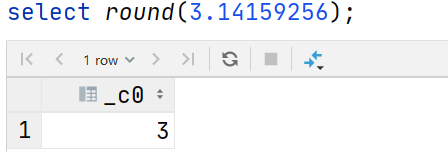
•Rounding function: round •Specify precision rounding function: round •Rounding down function: floor •Rounding up function: ceil •Take random number function: rand •Binary function: bin •Binary conversion function: conv •Absolute value function: abs
--Rounding function: round return double Integer value part of type (follow rounding) select round(3.1415926); --Specify precision rounding function: round(double a, int d) Returns the specified precision d of double type select round(3.1415926,4); --Rounding down function: floor select floor(3.1415926); select floor(-3.1415926); --Rounding up function: ceil select ceil(3.1415926); select ceil(-3.1415926); --Take random number function: rand Each execution is different, and a random number in the range of 0 to 1 is returned select rand(); --Specifies the seed random number function: rand(int seed) A stable sequence of random numbers is obtained select rand(2); --Binary function: bin(BIGINT a) select bin(18); --Binary conversion function: conv(BIGINT num, int from_base, int to_base) select conv(17,10,16); --Absolute value function: abs select abs(-3.9);
2.1.4 Collection Functions
It mainly operates on complex data types such as collections, such as the following:
•Collection element size function: size(Map<K.V>) size(Array<T>) •take map aggregate keys function: map_keys(Map<K.V>) •take map aggregate values function: map_values(Map<K.V>) •Determines whether the array contains the specified element: array_contains(Array<T>, value) •Array sort function:sort_array(Array<T>)
--Collection element size function: size(Map<K.V>) size(Array<T>)
select size(`array`(11,22,33));
select size(`map`("id",10086,"name","zhangsan","age",18));
--take map aggregate keys function: map_keys(Map<K.V>)
select map_keys(`map`("id",10086,"name","zhangsan","age",18));
--take map aggregate values function: map_values(Map<K.V>)
select map_values(`map`("id",10086,"name","zhangsan","age",18));
--Determines whether the array contains the specified element: array_contains(Array<T>, value)
select array_contains(`array`(11,22,33),11);
select array_contains(`array`(11,22,33),66);
--Array sort function:sort_array(Array<T>)
select sort_array(`array`(12,2,32));
2.1.5 Conditional Functions
It is mainly used in situations such as conditional judgment and logical judgment conversion, such as:
•if Conditional judgment: if(boolean testCondition, T valueTrue, T valueFalseOrNull) •Null judgment function: isnull( a ) •Non empty judgment function: isnotnull ( a ) •Null conversion function: nvl(T value, T default_value) •Non null lookup function: COALESCE(T v1, T v2, ...) •Conditional conversion function: CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END •nullif( a, b ): If a = b,Then return NULL;Otherwise return NULL. Otherwise, return a •assert_true: If'condition'If it is not true, an exception is thrown, otherwise it returns null
--Use the created by the previous course student Table data
select * from student limit 3;
--if Conditional judgment: if(boolean testCondition, T valueTrue, T valueFalseOrNull)
select if(1=2,100,200);
select if(sex ='male','M','W') from student limit 3;
--Null judgment function: isnull( a )
select isnull("allen");
select isnull(null);
--Non empty judgment function: isnotnull ( a )
select isnotnull("allen");
select isnotnull(null);
--Null conversion function: nvl(T value, T default_value)
select nvl("allen","itcast");
select nvl(null,"itcast");
--Non null lookup function: COALESCE(T v1, T v2, ...)
--Returns the first non null value in the parameter; If all values are NULL,Then return NULL
select COALESCE(null,11,22,33);
select COALESCE(null,null,null,33);
select COALESCE(null,null,null);
--Conditional conversion function: CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END
select case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end;
select case sex when 'male' then 'man' else 'women' end from student limit 3;
--nullif( a, b ):
-- fruit a = b,Then return NULL;Otherwise return NULL. Otherwise, return a
select nullif(11,11);
select nullif(11,12);
--assert_true(condition)
--If'condition'If it is not true, an exception is thrown, otherwise it returns null
SELECT assert_true(11 >= 0);
SELECT assert_true(-1 >= 0);
2.1.6 Type Conversion Functions
It is mainly used for explicit data type conversion. There are two functions:
•Conversion between any data type:cast
--Conversion between any data type:cast select cast(12.14 as bigint); select cast(12.14 as string);
2.1.7 Data Masking Functions
It mainly completes the data desensitization conversion function and shields the original data, mainly as follows:
•mask •mask_first_n(string str[, int n] •mask_last_n(string str[, int n]) •mask_show_first_n(string str[, int n]) •mask_show_last_n(string str[, int n]) •mask_hash(string|char|varchar str)
--mask
--Convert the queried data into uppercase letters X,Convert lowercase letters to x,Convert numbers to n.
select mask("abc123DEF");
select mask("abc123DEF",'-','.','^'); --Custom replacement letters
--mask_first_n(string str[, int n]
--Right front n Desensitization replacement
select mask_first_n("abc123DEF",4);
--mask_last_n(string str[, int n])
select mask_last_n("abc123DEF",4);
--mask_show_first_n(string str[, int n])
--Except before n Characters, the rest are masked
select mask_show_first_n("abc123DEF",4);
--mask_show_last_n(string str[, int n])
select mask_show_last_n("abc123DEF",4);
--mask_hash(string|char|varchar str)
--Returns the of a string hash code.
select mask_hash("abc123DEF");
2.1.8 Misc. Functions other miscellaneous functions
•hive call java method: java_method(class, method[, arg1[, arg2..]]) •Reflection function: reflect(class, method[, arg1[, arg2..]]) •Hash function:hash •current_user(),logged_in_user(),current_database(),version() •SHA-1 encryption: sha1(string/binary) •SHA-2 Family algorithm encryption: sha2(string/binary, int) (SHA-224, SHA-256, SHA-384, SHA-512) •crc32 encryption: •MD5 encryption: md5(string/binary)
--hive call java method: java_method(class, method[, arg1[, arg2..]])
select java_method("java.lang.Math","max",11,22);
--Reflection function: reflect(class, method[, arg1[, arg2..]])
select reflect("java.lang.Math","max",11,22);
--Hash function:hash
select hash("allen");
--current_user(),logged_in_user(),current_database(),version()
--SHA-1 encryption: sha1(string/binary)
select sha1("allen");
--SHA-2 Family algorithm encryption: sha2(string/binary, int) (SHA-224, SHA-256, SHA-384, SHA-512)
select sha2("allen",224);
select sha2("allen",512);
--crc32 encryption:
select crc32("allen");
--MD5 encryption: md5(string/binary)
select md5("allen");
2.2 user defined function classification
Although Hive has many built-in functions, it may not be able to meet the various analysis needs of users. In order to solve this problem, Hive pushes out the user-defined function function, allowing users to realize the function they want to realize.
User defined function (UDF for short) is derived from English user-defined function. There are three types of user-defined functions, which are distinguished according to the number of lines of function input and output, namely:
UDF(User-Defined-Function)Ordinary function, one in and one out UDAF(User-Defined Aggregation Function)Aggregate function, one more in and one out UDTF(User-Defined Table-Generating Functions)Table generation function, one in, many out
2.2.1 UDF classification standard expansion
Although UDF is called user-defined function, its classification standard is mainly aimed at the functions written and developed by users.
However, this set of UDF classification criteria can be extended to all Hive functions: including built-in functions and User-Defined functions. Because no matter what type of lines, they must meet the requirements of input and output, there is no problem in dividing them from input lines and output lines. Don't be confused by the two letters UD (user defined) and make your vision narrow.
For example, in Hive's official documents, the standard for aggregate functions is the built-in UDAF type.

2.2.2 UDF general functions
UDF functions are usually called ordinary functions. The biggest feature is one in one out, that is, one input line and one output line. For example, a rounding function such as round receives a row of data and outputs a row of data.
3.2.2.3 UDAF aggregate function
UDAF function is usually called Aggregation function. The word represented by A means Aggregation. The biggest feature is multiple input and one output, that is, multiple input lines and one output line. Functions such as count and sum.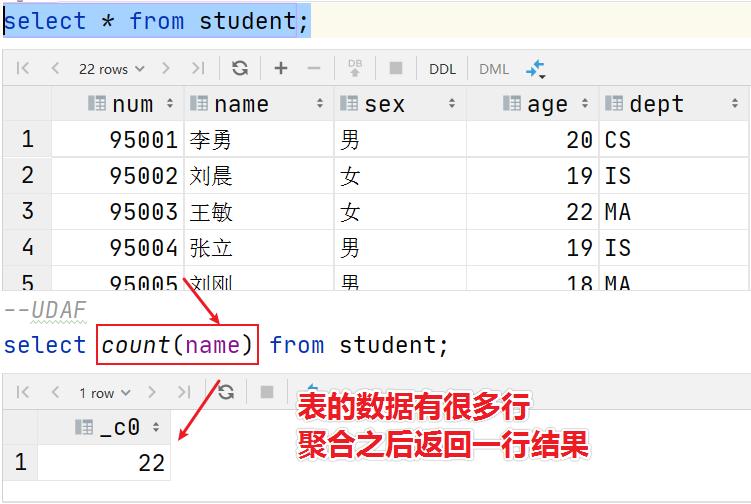
•count:Count the total number of rows retrieved. •sum:Sum •avg:Average •min:minimum value •max:Maximum •Data collection function (de duplication): collect_set(col) •Data collection function (no duplication): collect_list(col)
select sex from student; select collect_set(sex) from student; select collect_list(sex) from student;
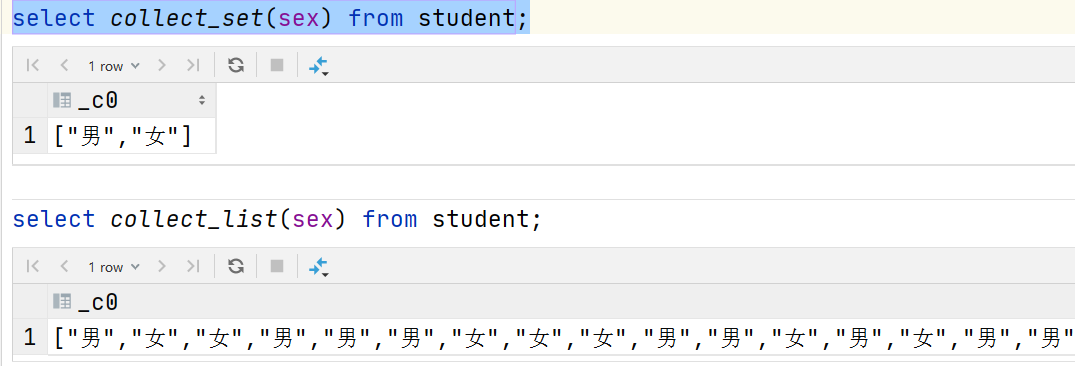
2.2.4 UDTF table generation function
UDTF function is usually called table generating function. The word represented by T means table generating. The biggest feature is one in and many out, that is, one line of input and multiple lines of output.
The reason why it is called a table generation function is that the results returned by this type of function are similar to tables (multi row data). At the same time, UDTF function is also a function we have little contact with, which is strange. For example, the expand function.
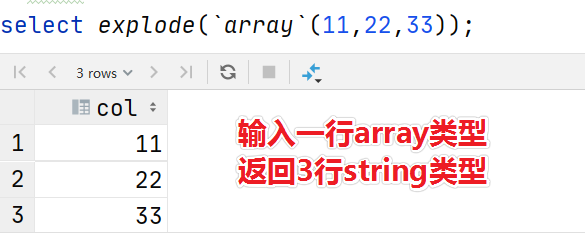
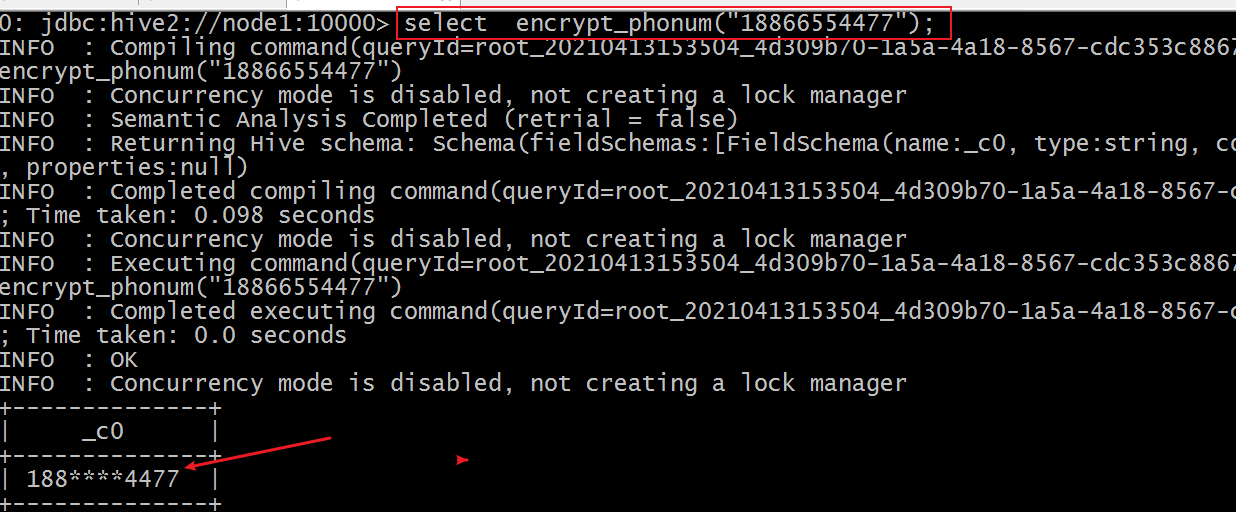
Case 3: user defined UDF
3.1 requirements description
When processing data in an enterprise, it is often necessary to desensitize sensitive data. Like a cell phone number. Our common processing method is to process the middle 4 digits of the mobile phone number.
There is no such function in Hive that can directly realize the function. Although it can be realized through the nested call of various functions, the efficiency is not high. Now it is required to develop and implement Hive function to meet the above requirements.
1. It can judge the non null and digit of the input data
2. It can verify the format of mobile phone number and process those that meet the rules
3. The data that does not comply with the mobile phone number rules will not be processed intact
3.2 implementation steps
Through business analysis, we can find that the function we need to implement is a function with input line and output line, that is, the so-called UDF ordinary function.
According to the UDF development specification in Hive, the implementation steps are as follows:
1. Write a java class, inherit UDF, and overload the evaluate method;
2. The program is made into a jar package, uploaded to the server and added to hive's classpath;
hive>add JAR /home/hadoop/udf.jar;
3. Register as a temporary function (name UDF);
create temporary function name as' UDF class full path ';
4. Use function
3.3 code implementation
3.3.1 development environment preparation
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.4</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.2</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
3.3.2 business code
package cn.itcast.hive.udf;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.hive.ql.exec.UDF;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @description: hive The user-defined function UDF implements * * * * encryption of the middle 4 digits of the mobile phone number
* @author: Itcast
*/
public class EncryptPhoneNumber extends UDF {
/**
* Overload the evaluate method to implement the business logic of the function
* @param phoNum Input parameter: unencrypted mobile phone number
* @return Return: encrypted mobile phone number string
*/
public String evaluate(String phoNum){
String encryptPhoNum = null;
//The mobile phone number is not empty and is 11 digits
if (StringUtils.isNotEmpty(phoNum) && phoNum.trim().length() == 11 ) {
//Determine whether data meets Chinese mainland mobile phone number specification
String regex = "^(1[3-9]\\d{9}$)";
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(phoNum);
if (m.matches()) {//Entering here is in line with the mobile phone number rules
//Use regular substitution to return encrypted data
encryptPhoNum = phoNum.trim().replaceAll("()\\d{4}(\\d{4})","$1****$2");
}else{
//The data that does not comply with the mobile phone number rules is returned directly intact
encryptPhoNum = phoNum;
}
}else{
//Non conforming 11 bit data is returned directly intact
encryptPhoNum = phoNum;
}
return encryptPhoNum;
}
}
3.4 deployment measurement
3.4.1 upload the jar package to the server
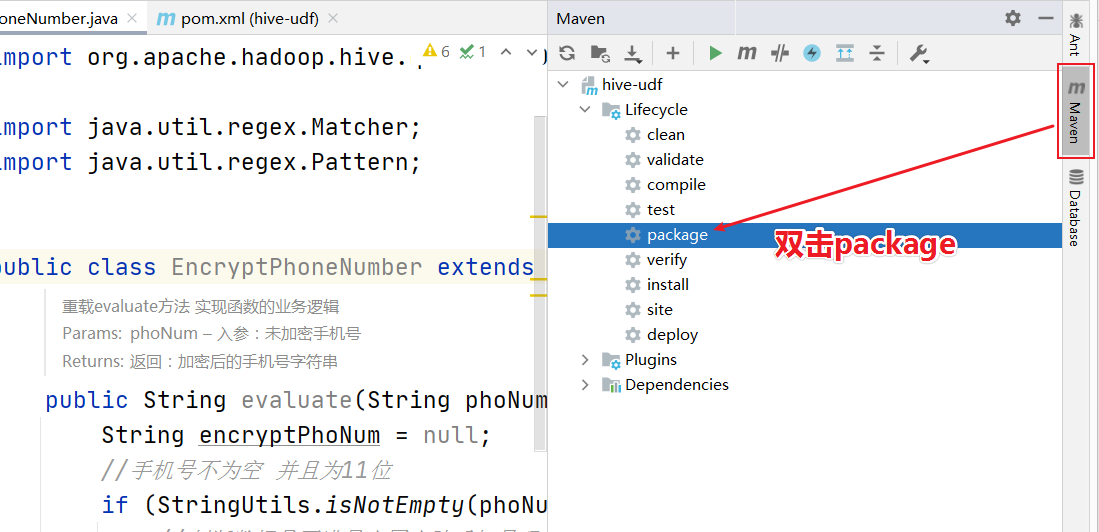
Upload the jar package to the linux system or HDFS file system of the machine where the Hiveserver2 service runs.
3.4.2 add to Hive Classpath
Add the jar package to the classpath using the command from the client.
3.4.3 register temporary functions
3.4.4 function effect demonstration