Preface
This blog mainly solves the dynamic generation of word (docx format) in java background, and converts word into pdf and adds watermarking.
Reflection
The requirement of the project is to export pdf with watermarking. The form style is still a bit complicated. It was considered that itextpdf was used to generate pdf based on html, but the framework used foreground and background points.
Separately, the front desk uses react, and in the absence of a table, so it is impossible to get html code blocks generated through the front desk, and then splice them manually.
html, but the code is too large, difficult to maintain, and the style is not very good. So I decided to use the freemarker template to generate word and convert it to pdf. Look through a lot of information on the Internet to give
There are many schemes to convert word to pdf, useful poi, useful third-party tools and so on. Writing with POI is too complicated, jar quotes a lot, and the prospects of using third-party tools
Limited, not suitable for exaggerating platform, need to install services. So we decided to use docx4j, but docx4j only supports word to pdf in docx format, so we need freemarker
Generate docx word.
Start with
1. pom Introduces Dependency
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
<version>5.4.3</version>
</dependency>
<dependency>
<groupId>freemarker</groupId>
<artifactId>freemarker</artifactId>
<version>2.3.23</version>
</dependency>
<dependency>
<groupId>org.docx4j</groupId>
<artifactId>docx4j</artifactId>
<version>6.1.2</version>
</dependency>
<dependency>
<groupId>org.docx4j</groupId>
<artifactId>docx4j-export-fo</artifactId>
<version>6.0.0</version>
</dependency>
2. freemarker generates word (docx)
Previously, when freemarker was used to generate word, doc format was generated. The document template file was saved as XML format and regenerated into word, which was actually an XML file.
But the file suffix name is doc, even if the file suffix name is changed to docx at the time of generation, the generated file can not be opened. Actually, docx is essentially a compression package.
It contains document.xml file, resource definition file document.xml.rels, header and footer file, image resources and so on. The solution is to replace them.
Change the document.xml file in the content area.
1) Prepare docx template file, edit and insert placeholder.
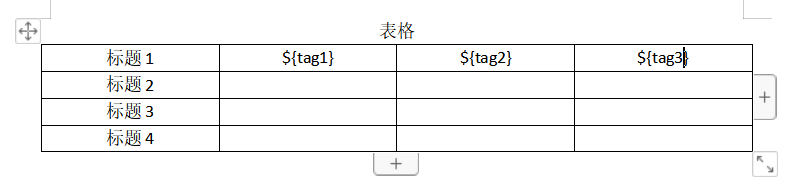
2) Copy a docx file and change the suffix name of the copied file to zip
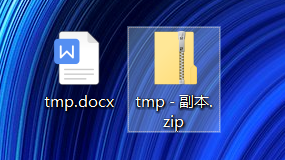
3) Copy out the document.xml file under word path in zip package, which is the main content file of word. The previous tmp.docx and the copied document.xml
These two files are the two template files we need to copy into the project.
4) Tool class code
1 package com.eazytec.zqtong.common.utils; 2 3 import com.itextpdf.text.*; 4 import com.itextpdf.text.pdf.*; 5 import org.docx4j.Docx4J; 6 import org.docx4j.convert.out.FOSettings; 7 import org.docx4j.fonts.IdentityPlusMapper; 8 import org.docx4j.fonts.Mapper; 9 import org.docx4j.fonts.PhysicalFonts; 10 import org.docx4j.openpackaging.packages.WordprocessingMLPackage; 11 import org.springframework.core.io.ClassPathResource; 12 13 import java.io.*; 14 import java.util.*; 15 import java.util.zip.ZipEntry; 16 import java.util.zip.ZipFile; 17 import java.util.zip.ZipOutputStream; 18 19 public class PdfUtil { 20 private static String separator = File.separator;//Folder path delimiter 21 22 //=========================================Generate application form pdf=================================== 23 24 /** 25 * freemark Generate word - docx format 26 * @param dataMap data source 27 * @param documentXmlName document.xml File name of template 28 * @param docxTempName docx File name of template 29 * @return Generated file path 30 */ 31 public static String createApplyPdf(Map<String,Object> dataMap,String documentXmlName,String docxTempName) { 32 ZipOutputStream zipout = null;//word output stream 33 File tempPath = null;//docx Format word File path 34 try { 35 //freemark Generate content from templates xml 36 //================================Obtain document.xml Input stream================================ 37 ByteArrayInputStream documentInput = FreeMarkUtils.getFreemarkerContentInputStream(dataMap, documentXmlName, separator + "template" + separator + "downLoad" + separator); 38 //================================Obtain document.xml Input stream================================ 39 //Get the master template docx 40 ClassPathResource resource = new ClassPathResource("template" + File.separator + "downLoad" + File.separator + docxTempName); 41 File docxFile = resource.getFile(); 42 43 ZipFile zipFile = new ZipFile(docxFile); 44 Enumeration<? extends ZipEntry> zipEntrys = zipFile.entries(); 45 46 //output word File path and name 47 String fileName = "applyWord_" + System.currentTimeMillis() + ".docx"; 48 String outPutWordPath = System.getProperty("java.io.tmpdir").replaceAll(separator + "$", "") + separator + fileName; 49 50 tempPath = new File(outPutWordPath); 51 //If the output target folder does not exist, create 52 if (!tempPath.getParentFile().exists()) { 53 tempPath.mkdirs(); 54 } 55 //docx File Output Stream 56 zipout = new ZipOutputStream(new FileOutputStream(tempPath)); 57 58 //Cyclic traversal of master template docx file,Replace the main content area, which is obtained above. document.xml Contents 59 //------------------Overlay documents------------------ 60 int len = -1; 61 byte[] buffer = new byte[1024]; 62 while (zipEntrys.hasMoreElements()) { 63 ZipEntry next = zipEntrys.nextElement(); 64 InputStream is = zipFile.getInputStream(next); 65 if (next.toString().indexOf("media") < 0) { 66 zipout.putNextEntry(new ZipEntry(next.getName())); 67 if ("word/document.xml".equals(next.getName())) { 68 //Write master data information after filling data 69 if (documentInput != null) { 70 while ((len = documentInput.read(buffer)) != -1) { 71 zipout.write(buffer, 0, len); 72 } 73 documentInput.close(); 74 } 75 }else {//Not all master data areas use master templates 76 while ((len = is.read(buffer)) != -1) { 77 zipout.write(buffer, 0, len); 78 } 79 is.close(); 80 } 81 } 82 } 83 //------------------Overlay documents------------------ 84 zipout.close();//Close 85 86 //----------------word turn pdf-------------- 87 return convertDocx2Pdf(outPutWordPath); 88 89 } catch (Exception e) { 90 e.printStackTrace(); 91 try { 92 if(zipout!=null){ 93 zipout.close(); 94 } 95 }catch (Exception ex){ 96 ex.printStackTrace(); 97 } 98 } 99 return ""; 100 } 101 102 /** 103 * word(docx)Transfer to pdf 104 * @param wordPath docx File path 105 * @return Generated watermarked pdf path 106 */ 107 public static String convertDocx2Pdf(String wordPath) { 108 OutputStream os = null; 109 InputStream is = null; 110 try { 111 is = new FileInputStream(new File(wordPath)); 112 WordprocessingMLPackage mlPackage = WordprocessingMLPackage.load(is); 113 Mapper fontMapper = new IdentityPlusMapper(); 114 fontMapper.put("Official script", PhysicalFonts.get("LiSu")); 115 fontMapper.put("Song Style", PhysicalFonts.get("SimSun")); 116 fontMapper.put("Microsoft YaHei", PhysicalFonts.get("Microsoft Yahei")); 117 fontMapper.put("Blackbody", PhysicalFonts.get("SimHei")); 118 fontMapper.put("Italics", PhysicalFonts.get("KaiTi")); 119 fontMapper.put("NSimSun", PhysicalFonts.get("NSimSun")); 120 fontMapper.put("STXingkai", PhysicalFonts.get("STXingkai")); 121 fontMapper.put("stfangsong", PhysicalFonts.get("STFangsong")); 122 fontMapper.put("The Expansion of Song Style", PhysicalFonts.get("simsun-extB")); 123 fontMapper.put("Imitating Song Dynasty", PhysicalFonts.get("FangSong")); 124 fontMapper.put("Imitating Song Dynasty_GB2312", PhysicalFonts.get("FangSong_GB2312")); 125 fontMapper.put("Juvenile circle", PhysicalFonts.get("YouYuan")); 126 fontMapper.put("stsong", PhysicalFonts.get("STSong")); 127 fontMapper.put("stzhongsong", PhysicalFonts.get("STZhongsong")); 128 129 mlPackage.setFontMapper(fontMapper); 130 131 //output pdf File path and name 132 String fileName = "pdfNoMark_" + System.currentTimeMillis() + ".pdf"; 133 String pdfNoMarkPath = System.getProperty("java.io.tmpdir").replaceAll(separator + "$", "") + separator + fileName; 134 135 os = new java.io.FileOutputStream(pdfNoMarkPath); 136 137 //docx4j docx turn pdf 138 FOSettings foSettings = Docx4J.createFOSettings(); 139 foSettings.setWmlPackage(mlPackage); 140 Docx4J.toFO(foSettings, os, Docx4J.FLAG_EXPORT_PREFER_XSL); 141 142 is.close();//Close the input stream 143 os.close();//Close the output stream 144 145 //Watermarking 146 return addTextMark(pdfNoMarkPath); 147 } catch (Exception e) { 148 e.printStackTrace(); 149 try { 150 if(is != null){ 151 is.close(); 152 } 153 if(os != null){ 154 os.close(); 155 } 156 }catch (Exception ex){ 157 ex.printStackTrace(); 158 } 159 }finally { 160 File file = new File(wordPath); 161 if(file!=null&&file.isFile()&&file.exists()){ 162 file.delete(); 163 } 164 } 165 return ""; 166 } 167 168 /** 169 * Adding Watermark Pictures 170 * @param inPdfPath Waterless pdf path 171 * @return Generated watermarked pdf path 172 */ 173 private static String addTextMark(String inPdfPath) { 174 PdfStamper stamp = null; 175 PdfReader reader = null; 176 try { 177 //output pdf Watermarked File Path and Name 178 String fileName = "pdfMark_" + System.currentTimeMillis() + ".pdf"; 179 String outPdfMarkPath = System.getProperty("java.io.tmpdir").replaceAll(separator + "$", "") + separator + fileName; 180 181 //Watermarking 182 reader = new PdfReader(inPdfPath, "PDF".getBytes()); 183 stamp = new PdfStamper(reader, new FileOutputStream(new File(outPdfMarkPath))); 184 PdfContentByte under; 185 int pageSize = reader.getNumberOfPages();// primary pdf Total Pages of Documents 186 //Watermarking Pictures 187 ClassPathResource resource = new ClassPathResource("template" + File.separator + "downLoad" + File.separator + "mark.png"); 188 File file = resource.getFile(); 189 Image image = Image.getInstance(file.getPath()); 190 for (int i = 1; i <= pageSize; i++) { 191 under = stamp.getUnderContent(i);// Watermarking under previous text 192 image.setAbsolutePosition(100, 210);//Watermark Location 193 under.addImage(image); 194 } 195 stamp.close();// Close 196 reader.close();//Close 197 198 return outPdfMarkPath; 199 } catch (Exception e) { 200 e.printStackTrace(); 201 try { 202 if (stamp != null) { 203 stamp.close(); 204 } 205 if (reader != null) { 206 reader.close();//Close 207 } 208 } catch (Exception ex) { 209 ex.printStackTrace(); 210 } 211 } finally { 212 //Delete the generated watermarkless pdf 213 File file = new File(inPdfPath); 214 if (file != null && file.exists() && file.isFile()) { 215 file.delete(); 216 } 217 } 218 return ""; 219 } 220 221 public static void main(String[] args) { 222 // createApplyPdf(); 223 // convert(); 224 // addTextMark("D:\\test\\test.pdf", "D:\\test\\test2.pdf"); 225 } 226 227 }
problem
When generating files to download, it feels a little slower. In fact, the files are not big. There will be a download box in 8 or 9 seconds. I don't know if it is the reason why the front and back are separated.