Tip: after the article is written, the directory can be generated automatically. Please refer to the help document on the right for how to generate it
1, The role of hadoop?
What is hadoop?
Hadoop is an open source framework that can write and run distributed applications to process large-scale data. It is designed for offline and large-scale data analysis. It is not suitable for the online transaction processing mode of random reading and writing of several records. Hadoop=HDFS (file system, related to data storage technology) + Mapreduce (data processing). The data source of Hadoop can be in any form. Compared with relational database, Hadoop has better performance and more flexible processing ability in processing semi-structured and unstructured data. No matter any data form will eventually be transformed into key/value, which is the basic data unit. Replace SQL with functional Mapreduce. SQL is a query statement, while Mapreduce uses scripts and code. For relational databases, Hadoop used to SQL has an open source tool hive instead.
What can hadoop do?
Hadoop is good at log analysis. facebook uses hive for log analysis. In 2009, 30% of facebook's non programmers used HiveQL for data analysis; Hive is also used for custom filtering in Taobao Search; Pig can also be used for advanced data processing, including discovering people you may know on Twitter and LinkedIn, and can achieve the recommendation effect of collaborative filtering similar to Amazon.com. Taobao's commodity recommendation is also! At Yahoo! 40% of Hadoop jobs are run with pig, including spam identification and filtering, and user feature modeling. (updated on August 25, 2012, tmall's recommendation system is hive. Try mahout a few times!)
Build Hadoop ha high availability cluster
1 General cluster configuration file
-
hdfs-site.xml
<configuration> <!-- <property> <name>dfs.replication</name> <value>1</value> </property>--> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop-3:50090</value> </property> </configuration> -
core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop-1:8020</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/data/tmp</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file://${hadoop.tmp.dir}/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file://${hadoop.tmp.dir}/dfs/data</value> </property> </configuration> -
slaves
hadoop-1 hadoop-2 hadoop-3
-
yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop-2</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>106800</value> </property> </configuration> -
mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop-1:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop-1:19888</value> </property> </configuration>
2. High availability cluster configuration
-
hdfs-site.xml
<configuration> <property> <!-- by namenode Cluster definition services name --> <name>dfs.nameservices</name> <value>ns1</value> </property> <property> <!-- nameservice What does it contain namenode,For each namenode Name --> <name>dfs.ha.namenodes.ns1</name> <value>nn1,nn2</value> </property> <property> <!-- be known as nn1 of namenode of rpc Address and port number, rpc Used with datanode communication --> <name>dfs.namenode.rpc-address.ns1.nn1</name> <value>hadoop-1:8020</value> </property> <property> <!-- be known as nn2 of namenode of rpc Address and port number, rpc Used with datanode communication --> <name>dfs.namenode.rpc-address.ns1.nn2</name> <value>hadoop-2:8020</value> </property> <property> <!--be known as nn1 of namenode of http Address and port number, web client --> <name>dfs.namenode.http-address.ns1.nn1</name> <value>hadoop-1:50070</value> </property> <property> <!--be known as nn2 of namenode of http Address and port number, web client --> <name>dfs.namenode.http-address.ns1.nn2</name> <value>hadoop-2:50070</value> </property> <property> <!-- namenode For sharing editing logs between journal Node list --> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop-1:8485;hadoop-2:8485;hadoop-3:8485/ns1</value> </property> <property> <!-- journalnode Upper for storage edits Directory of logs --> <name>dfs.journalnode.edits.dir</name> <value>/opt/data/tmp/dfs/jn</value> </property> <property> <!-- Status of client connection availability NameNode Proxy class used --> <name>dfs.client.failover.proxy.provider.ns1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <!-- --> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <property> <!-- Configure automatic failover --> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>dfs.replication.max</name> <value>32767</value> </property> </configuration> -
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/tmp</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop-1:2181,hadoop-2:2181,hadoop-3:2181</value>
</property>
</configuration>
-
slaves
hadoop-1 hadoop-2 hadoop-3
-
yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>106800</value> </property> <property> <!-- Enable resourcemanager of ha function --> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <!-- by resourcemanage ha Cluster start id --> <name>yarn.resourcemanager.cluster-id</name> <value>yarn-cluster</value> </property> <property> <!-- appoint resourcemanger ha What are the node names --> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm12,rm13</value> </property> <property> <!-- Specify the machine where the first node is located --> <name>yarn.resourcemanager.hostname.rm12</name> <value>hadoop-2</value> </property> <property> <!-- Specify the machine where the second node is located --> <name>yarn.resourcemanager.hostname.rm13</name> <value>hadoop-3</value> </property> <property> <!-- appoint resourcemanger ha Used zookeeper node --> <name>yarn.resourcemanager.zk-address</name> <value>hadoop-1:2181,hadoop-2:2181,hadoop-3:2181</value> </property> <property> <!-- --> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <!-- --> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> </configuration> -
mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop-1:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop-1:19888</value> </property> </configuration>
Sort out and record the commands used to build hadoop HA high availability cluster
1. Upload file to file server
#Create file directory [root@hadoop-1 hadoop]$ bin/hdfs dfs -mkdir /input #Upload file [root@hadoop-1 hadoop]$ bin/hdfs dfs -put /opt/data/wc.input /input/wc.input #Run program [root@hadoop-1 hadoop]$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /input/wc.input /output #View HDFS root [root@hadoop-1 hadoop]$ hadoop fs -ls / or bin/hdfs fs -ls / #Create a directory test in the root directory [root@hadoop-1 hadoop]$ hadoop fs -mkdir /test or bin/hdfs fs -mkdir /test
2. Check whether files have been uploaded under the specified directory of the file server
[root@hadoop-1 hadoop]$ bin/hdfs dfs -ls /input
As shown in the figure: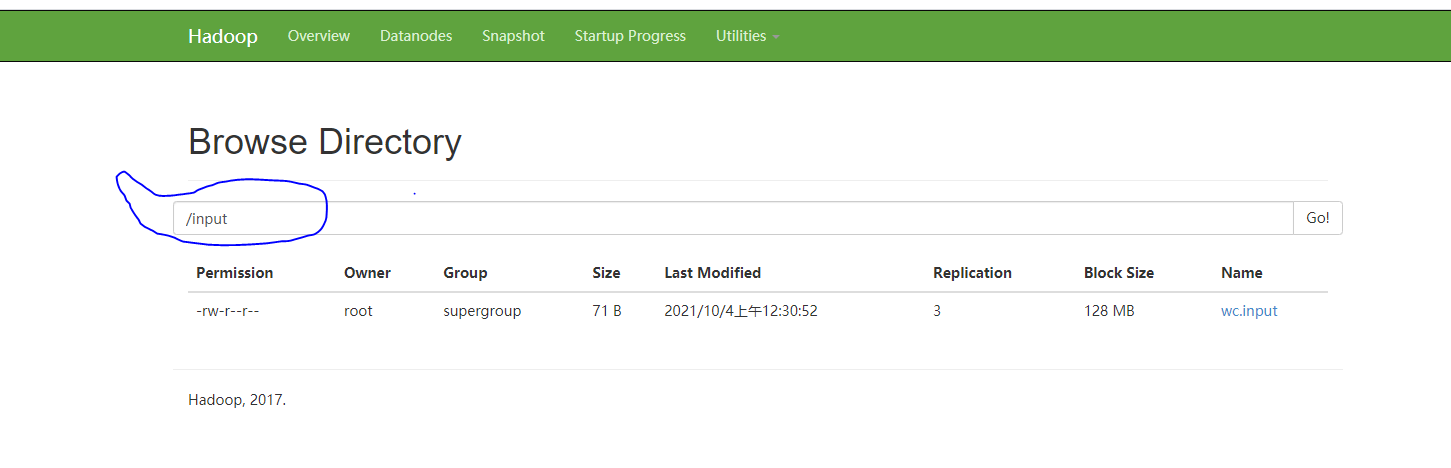
3. How the namenode service is formatted
-
Direct formatting
[root@hadoop-1 hadoop]$ bin/hdfs namenode -format
-
Cluster node format - keep all nodes (including namenode, datanode and journalnode's clusterId consistent)
[root@hadoop-1 hadoop]$ bin/hdfs namenode -format -clusterId hadoop-federation-clusterId
-
Start namenode in the standby state. In this state, namenode does not process requests`
[root@hadoop-1 hadoop]$ bin/hdfs namenode -bootstrapStandby
4. Check whether the namenode is in use or Active
[root@hadoop-1 hadoop]# hdfs dfsadmin -report
5. Check whether the service is started
-
Use jps to see if there is a namenode
-
Use without
[root@hadoop-1 hadoop]$ sbin/hadoop-daemon.sh start namenode
-
Or use to start namenode
[hadoop@bigdata-senior02 hadoop-2.5.0]$ sbin/start-dfs.sh
-
If the startup fails, it may be caused by the format of namenode for many times. You need to clean up the data, name and jn (journalnode) files generated under the hadoop.tmp.dir path configured under core-site.xml
<property> <name>hadoop.tmp.dir</name> <value>/opt/data/tmp</value> </property>Start again using method 3-2
-
If it still fails, you need to view the error log
[root@hadoop-1 hadoop]cd logs [root@hadoop-1 logs]tail -fn 300 hadoop-root-namenode-hadoop-1.log
Then according to the error report log, baidu finds the problem
6. datanode startup failed
-
Check whether the DataNode starts the input command jps
-
If no datanode is found, do the following
[root@hadoop-1 hadoop]# sbin/hadoop-daemon.sh start datanode
-
It is found that the startup is still unsuccessful after execution. Check whether core-site.xml configures the environment path of datanode
<property> <name>hadoop.tmp.dir</name> <value>/opt/data/tmp</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file://${hadoop.tmp.dir}/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file://${hadoop.tmp.dir}/dfs/data</value> </property> -
If the configuration does not take effect (if it is not configured, just restart the command of service 5-3), enter the path to check whether the current file is generated
[root@hadoop-1 hadoop]# cd /opt/data/tmp/dfs/data/current/
If the VERSION file comes out, that is, it has been started, check whether the VERSION of namenode is consistent with that of datanode
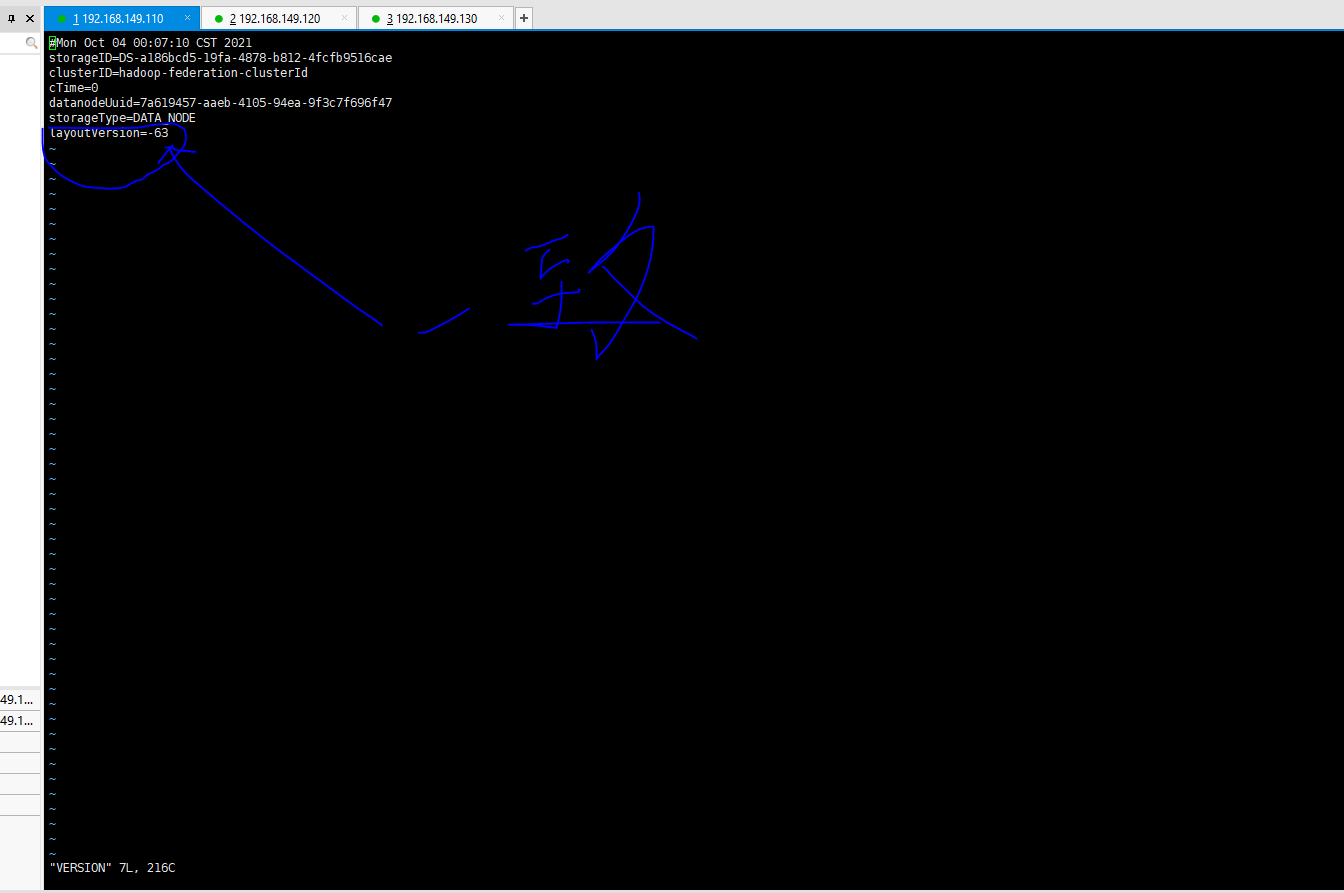
If not, change the version number of datanode to be consistent with namnode. If it still fails, there may be too much metadata space, and some log files need to be deleted to ensure the normal operation of datanode. Such as share/doc and logs / Hadoop root*#Delete hadoop function document file [root@hadoop-1 hadoop]# cd share/doc [root@hadoop-1 doc]# rm -rf * #Delete hadoop log files [root@hadoop-1 hadoop]# cd logs/ [root@hadoop-1 doc]# rm -rf hadoop-root*
-
Start datanode again
[root@hadoop-1 hadoop]# sbin/hadoop-daemon.sh start datanode
At this stage, most people may restart the datanode successfully, but some people may fail to start because of the configuration file. It is recommended to restart the configuration file. The configuration file of the great God is written in great detail, which is very suitable for developers who are just learning to build hadoop clusters https://blog.csdn.net/hliq5399/article/details/78193113/
6. Check whether linux servers can access each other
-
Use ping to see if Ip can be accessed to each other
[root@hadoop-1 hadoop]ping hadoop-2
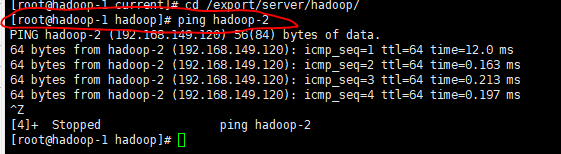
- Since most configurations are configured through the server IP alias, you need to configure domain name conversion on the DNS domain name service to ensure that your hostname has been changed and not changed. The following operations are invalid, https://blog.csdn.net/qq_22310551/article/details/84966044 The great God explained the configuration of hostname in a more comprehensive way, and the configuration has been resolved
[root@hadoop-1 hadoop]# cat /etc/hosts #127.0.0.1 localhost #::1 localhost #192.168.149.110 hadoop-1 #127.0.0.1 localhost 192.168.149.110 hadoop-1 192.168.149.120 hadoop-2 192.168.149.130 hadoop-3
The code is as follows (example):
1. Configure virtual machine hostname;
vi /etc/sysconfig/network #Set it like this NETWORKING=yes HOSTNAME=hadoop-1 #Close -- view the effect of changes more /etc/sysconfig/network hostname more /proc/sys/kernel/hostname #Then restart the virtual machine and permanently change it reboot #Remember that / etc/hosts has nothing to do with hostname, just a dns domain name converter
2. Configure the domain name of the window, and you can directly access the IP server corresponding to linux through the domain name
C:\Windows\System32\drivers\etc #Open hosts to add configuration, such as 192.168.149.110 hadoop-1 192.168.149.120 hadoop-2 192.168.149.130 hadoop-3
In the future, hadoop-1 can be directly used instead of 192.168.149.110.
Quick configuration scp -r /opt/data/tmp/dfs/jn/ hadoop-2:/opt/data/tmp/dfs/
The url used here is the data requested by the network.
-
Check whether the service is started. Generally speaking, port 8020 is the port after the namenode is started. Failure to access indicates that the namenode cannot be used. Port 8485 is the port after the journalnode is started
#Check whether the port is started [root@hadoop-1 hadoop]# netstat -tpnl
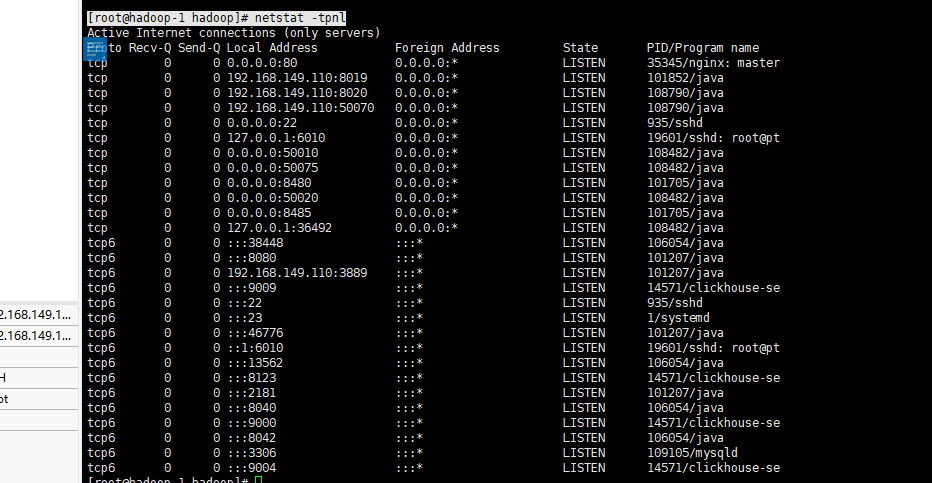
-
Description of the port with IP 0.0.0.0. The service can support remote access in many ways:
For example, 127.0.0.1:80 or service IP:80 or DNS domain name conversion: 80 can be used for 0.0.0.0:80#Domain name conversion [root@hadoop-1 hadoop]# curl hadoop-1:80
Or access the hadoop-1 port on node hadoop-2
[root@hadoop-2 hadoop]# curl hadoop-1:80
The description with IP 127.0.0.1 can only be accessed locally. For example, hadoop-1 services cannot be accessed through curl 127.0.0.1 6010 on hadoop-2 nodes.
The IP address is 192.168.149.110, indicating that other servers can access the port remotely -
Use telnet to check whether you can access the services you have started, such as
[root@hadoop-1 hadoop]# telnet hadoop-1 8020 Trying 192.168.149.110... Connected to hadoop-1. Escape character is '^]'.
If the connection is successful, telnet needs to download it through Baidu yum install -y telnet *
-
If you can't access it, it's also possible that you didn't enter your access account and password (provided that the firewall is closed). You can access it without secret by setting ssh
#To generate a key, you need to enter all the way [root@hadoop-1 hadoop]$ ssh-keygen -t rsa #Issue key [root@hadoop-1 hadoop]$ ssh-copy-id hadoop-1 [root@hadoop-1 hadoop]$ ssh-copy-id hadoop-2 [root@hadoop-1 hadoop]# $ ssh-copy-id hadoop-3
In this way, hadoop-2 and hadoop-3 can access hadoop-1 services without secret
7. Start the resource management resourceManager. If the service is not started, hadoop will not be able to upload files
-
Startup mode: start all services at once (including resourceManager)
[root@hadoop-1 hadoop]# sbin/start-all.sh
-
Single start
#Start yarn [root@hadoop-1 hadoop]$ sbin/start-yarn.sh #Start resourcemanager and start on the specified server [root@hadoop-2 hadoop]$ sbin/yarn-daemon.sh start resourcemanager [root@hadoop-3 hadoop]$ sbin/yarn-daemon.sh start resourcemanager
8. Web site after service startup http://hadoop-1:50070/dfshealth.html#tab-overview Add link description The namenode in is in standby and can be activated by force
#nn1 is the path in the configuration file
[root@hadoop-1 hadoop]$ bin/hdfs haadmin -transitionToActive -forcemanual nn1
[root@hadoop-1 hadoop]$ vi etc/hadoop/hdfs-site.xml
<property>
<!--be known as nn1 of namenode of http Address and port number, web client -->
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>hadoop-1:50070</value>
</property>
9. How to start the task node journalnode
[root@hadoop-1 hadoop]# sbin/hadoop-daemon.sh start journalnode
10. Create a zNode in hadoop
[root@hadoop-1 hadoop]$ bin/hdfs zkfc -formatZK
11. Start namenode, datanode, journalnode, zkfc
[root@hadoop-1 hadoop]$ sbin/start-dfs.sh
summary
Tip: This article is just some problems encountered by the author in the development process. It doesn't list too many problems. Most of them are caused by too many namenode formatting. Only those who are willing to spend energy have a good ending