"Look at the Handler with questions"
1, Write in front
At the beginning of the design, the Android system was designed as a single thread model. In fact, it is not only Android, but also Java Swing Historical reasons of Back to Android, we all know that the UI can only be updated in the UI thread, that is, the main thread, and it is stipulated that time-consuming operations (5S), such as network requests and I/O operations, cannot be performed in the UI thread. Otherwise, it will appear ANR , the program is not responding. As a developer, this is the last thing you want to see. In the actual development, there will certainly be scenarios where the UI needs to be updated in the sub thread. It can be said that the Handler is also to solve this contradiction - the UI can only be updated in the UI thread. The official notes also give two main functions of Handler:
1.To schedule messages and runnables to be executed at some point in the future;
2.To enqueue an action to be performed on a different thread than your own.
2, Look at it with questions
Android online source code reading tool( Android Code Search )It is very convenient to view the source code later than before. You can see the latest version of the source code information and also support the jump between calls; Almost the same as Android Studio. As shown in the figure, you can select the source code version you want to view according to your needs:
As far as I am concerned, I will sort out the directions or problems I want to know before I prepare to read the source code of Android system or other excellent open source libraries. In this way, I will look at the problems with priority to the content related to the problems. Personal understanding is still relatively efficient. After all, the details of the system source code design are too complex, and it is often unable to grasp the overall effect. So what are the common problems or internal use and details that should be mastered as an upper layer App development?
3, Frequently asked questions
1. How many handlers does a thread have?
2. How many loopers does a thread have? How to guarantee?
3. How many messagequeues can a thread have?
4. How to create a Message object?
5. What is the root cause of the handler memory leak? Do internal classes cause memory leaks?
6. How to instantiate a Handler object in the main thread and in the sub thread?
7. Why does looper loop not cause ANR application and consume resources?
8. Maintain Looper in the sub thread. How to handle when there is no message in the message queue? What's the usage?
9. Change of message queue after using Handler's postDelay?
10. How can multiple handlers ensure thread safety?
11. What is the synchronization barrier and what is its role? What are the specific usage scenarios of synchronization barrier and asynchronous message?
12.Android IdleHandler application scenario?
13. Can Looper objects be created multiple times?
14.MessageQueue function, data structure?
15. Implementation of delay message?
16.pipe/epoll mechanism?
It simply summarizes some problems that need to be mastered, and looks at the specific implementation of the source code with these problems. Of course, the focus should be on the specific implementation details of the mechanisms of Handler, Message and Looper. Android-12.0.0 based on source code_ r4.
1.Specific implementation of Handler
The message processing class is mainly responsible for sending messages to the "message queue" and processing messages.
- Constructor:
@Deprecated
public Handler() {
this(null, false);
}
@Deprecated
public Handler(@Nullable Callback callback) {
this(callback, fasle);
}
public Handler(@NonNull Looper looper) {
this(looper, null, false);
}
public Handler(@NonNull Looper looper, @Nullable Callback callback) {
this(looper, callback, false);
}
@UnsupportedAppUsage
public Handler(@NonNull Looper looper, @Nullable Callback callback, boolean async) {
mLooper = looper;
mQueue = looper.mQueue;
mCallback = callback;
mAsynchronous = async;
}
//.....
In the latest source code, the method without Looper parameter in the constructor has been labeled * * @ Deprecated. The official does not recommend instantiating a Handler * * object (implicitly specifying the Looper object). The explanation given in the source code is as follows:
Implicitly choosing a Looper during Handler construction can lead to bugs where operations are silently lost (if the Handler is not expecting new tasks and quits) crashes .
Without going into details, let's continue to look at other important methods of Handler.
- Method handles handleMessage()
//Subclasses must implement this to receive messages.
public void handleMessage(@NonNull Message msg) {
//Empty method, the implementation class needs to process to receive information
}
//Callback interface you can use when instantiating a Handler to avoid
//having to implement your own subclass of Handler.
public interface Callback {
boolean handleMessage(@NonNull Message msg);
}
Method processing is relatively simple. A Callback interface, of course, can be passed in as a parameter when instantiating the Handler, and contains an empty method of handleMessage. Subclasses need to implement specific message processing details themselves.
- Distribution of messages
//Handle system messages here.
public void dispatchMessage(@NonNull Message msg) {
if (msg.callback != null) {
handleCallback(msg);
} else {
if (mCallback != null) {
if (mCallback.handleMessage(msg)) {
return;
}
}
handleMessage(msg);
}
}
public final boolean post(@NonNull Runnable r) {
return sendMessageDelayed(getPostMessage(r), 0);
}
public final boolean postAtTime(@NonNull Runnable r, long uptimeMillis) {
return sendMessageAtTime(getPostMessage(r), uptimeMillis);
}
public final boolean postAtTime(@NonNull Runnable r, @Nullable Object token, long uptimeMillis) {
return sendMessageAtTime(getPostMessage(r, token), uptimeMillis);
}
public final boolean postDelayed(@NonNull Runnable r, long delayMillis) {
return sendMessageDelayed(getPostMessage(r), delayMillis);
}
//@hide
public final boolean postDelayed(Runnable r, int what, long delayMillis) {
return sendMessageDelayed(getPostMessage(r).setWhat(what), delayMillis);
}
public final boolean sendMessage(@NonNull Message msg) {
return sendMessageDelayed(msg, 0);
}
public final boolean sendEmptyMessage(int what) {
return sendEmptyMessageDelayed(what, 0);
}
public final boolean sendEmptyMessageDelayed(int what, long delayMillis) {
Message msg = Message.obtain();
msg.what = what;
return sendMessageDelayed(msg, delayMillis);
}
public final boolean sendEmptyMessageAtTime(int what, long uptimeMillis) {
Message msg = Message.obtain();
msg.what = what;
return sendMessageAtTime(msg, uptimeMillis);
}
public final boolean sendMessageDelayed(@NonNull Message msg, long delayMillis) {
if (delayMillis < 0) {
delayMillis = 0;
}
return sendMessageAtTime(msg, SystemClock.uptimeMillis() + delayMillis);
}
public boolean sendMessageAtTime(@NonNull Message msg, long uptimeMillis) {
MessageQueue queue = mQueue;
if (queue == null) {
RuntimeException e = new RuntimeException(
this + " sendMessageAtTime() called with no mQueue");
Log.w("Looper", e.getMessage(), e);
return false;
}
return enqueueMessage(queue, msg, uptimeMillis);
}
private boolean enqueueMessage(@NonNull MessageQueue queue, @NonNull Message msg,
long uptimeMillis) {
msg.target = this;
msg.workSourceUid = ThreadLocalWorkSource.getUid();
if (mAsynchronous) {
msg.setAsynchronous(true);
}
return queue.enqueueMessage(msg, uptimeMillis);
}
Whether it is postXX() or sendXX(), the distributed message will eventually be called back to the method enqueueMessage. The difference is the size of the delay time. Of course, the delay time is the sum of the system non dormant time node and the delay time according to the timestamp. When the time span given by the user is less than zero, it will be set to zero. The time value here also determines that if you want to achieve accurate time control, it is not enough to completely rely on delayMillis. See the code:
if(delayMillis < 0) {
delayMillis = 0;
}
return sendMessageAtTime(msg, SystemClock.uptimeMillis() + delayMillis);
//milliseconds since boot, not counting time spent in deep sleep.
native public static long uptimeMillis();
After further analysis, it is found that in addition to dispatchMessage(), other methods of distributing messages have finally reached queue Enqueuemessage (), which is added to the message queue, leads to another important member of the Handler mechanism - message queue. So why is the logic of this dispatchMessage() different, and the annotation information is relatively simple? Handle system messages here. Here I have a general understanding of Handler, which mainly has several functions:
1. When the handler is instantiated, implicitly specifying the Looper object is no longer recommended. The specific implementation depends on the internal implementation of Looper.
2. handleMessage() for message processing includes two methods: implementing internal interface Callback or implementing empty method handleMessage().
3. There are two main types of message distribution: dispatchMessage(), postXX(), sendXX(); Among them, dispatchMessage is special, while other messages are added to the message queue MessageQueue. The specific implementation details are in the interior.
Back to question 1 How many handlers does a thread have?, According to the source code, taking the main thread as an example, instantiating the Handler object is not limited. That is, a thread can have multiple Handler objects.

2.Implementation of MessageQueue
Low-level class holding the list of messages to be dispatched by a {@link Looper}. Messages are not added directly to a MessageQueue.
A group of messages are held and can be distributed through Looper. Secondly, messages are not directly added to the queue. Since it is "Message queue", let's see how it is implemented.
- Main member parameters
public final class MessageQueue {
@UnsupportedAppUsage
private final boolean mQuitAllowed;
@UnsupportedAppUsage
Message mMessages;
@UnsupportedAppUsage
private final ArrayList<IdleHandler> mIdleHandlers = new ArrayList<IdleHandler>();
private boolean mQuitting;
private boolean mBlocked;
private native static long nativeInit();
@UnsupportedAppUsage
private native void nativePollOnce(long ptr, int timeoutMillis); /*non-static for callbacks*/
//......
}
MessageQueue holds Message mMessages. Even if you don't look at the specific implementation of Message, you can guess that "Message queue" actually combines messages in the form of linked list. Why do you choose such a structure? Instead of arrays? In the Handler, when sending a Message, it is found that the delay time can be specified, and the Message is inserted into the Message queue. The nature of the linked list is reflected, and the insertion is fast. If the Message queue is implemented by an array, the expansion will involve the replication of the array content, which is not as efficient as the linked list. Secondly, the Message insertion operation is very frequent in the Handler. Using a linked list is more appropriate. Back to question 14 MessageQueue function, data structure?:
Message queue uses a linked list structure to deal with the frequent insertion of messages, which is conducive to the improvement of performance. The main function is to combine messages in a certain order and provide them to Looper for distribution.
- Key method - add message to queue enqueueMessage()
boolean enqueueMessage(Message msg, long when) {
if (msg.target == null) {
throw new IllegalArgumentException("Message must have a target.");
}
synchronized (this) {
if (msg.isInUse()) {
throw new IllegalStateException(msg + " This message is already in use.");
}
if (mQuitting) {
IllegalStateException e =
new IllegalStateException(
msg.target + " sending message to a Handler on a dead thread");
Log.w(TAG, e.getMessage(), e);
msg.recycle();
return false;
}
msg.markInUse();
msg.when = when;
Message p = mMessages;
boolean needWake;
if (p == null || when == 0 || when < p.when) {
// New head, wake up the event queue if blocked.
msg.next = p;
mMessages = msg;
needWake = mBlocked;
} else {
// Inserted within the middle of the queue. Usually we don't have to wake
// up the event queue unless there is a barrier at the head of the queue
// and the message is the earliest asynchronous message in the queue.
needWake = mBlocked && p.target == null && msg.isAsynchronous();
Message prev;
for (; ; ) {
prev = p;
p = p.next;
if (p == null || when < p.when) {
break;
}
if (needWake && p.isAsynchronous()) {
needWake = false;
}
}
msg.next = p; // invariant: p == prev.next
prev.next = msg;
}
// We can assume mPtr != 0 because mQuitting is false.
if (needWake) {
nativeWake(mPtr);
}
}
return true;
}
The method flow is not very complex, step by step analysis. For the Message to be added, first judge the Message Whether the target is empty. If it is empty, an exception will be thrown directly. Then enter the synchronization method to determine whether the Message is in use and whether the MessageQueue has exited. If you have exited, the Message will be recycled and returned. So what are the rules for inserting messages? Look at the code:
Message p = mMessages;
if (p == null || when == 0 || when < p.when) {
//New head, wake up the event queue if blocked.
msg.next = p;
mMessages = msg;
}
Assuming that the current Message queue mMessage is empty, naturally, the Message to be inserted will be used as the header of the queue, that is, MSG next = p(null); If P is not empty, look at the second condition when == 0. As the Handler knows, this when is actually the delayed time. But the delay time is not the sum of system time and delayMillis. Why is it 0? Return to the Handler:
public final boolean sendMessageAtFrontOfQueue(@NonNull Message msg) {
MessageQueue queue = mQueue;
if (queue == null) {
RuntimeException e = new RuntimeException(
this + " sendMessageAtTime() called with no mQueue");
Log.w("Looper", e.getMessage(), e);
return false;
}
//when can be equal to 0,
return enqueueMessage(queue, msg, 0);
}
However, in any case, when = = 0 | when < p.when, that is, whether the message can be used as a new message queue header is determined according to the delay time span. It is concluded that:
1. If the message queue is empty, the new message is directly used as the header.
2. The message queue is not empty, the delay interval is 0, and the new message is used as the header.
3. If the message queue is not empty, the delay interval is greater than 0, and the delay interval is less than the original queue p.when, the new message is used as the header.
Let's see else{} that is, the message is inserted into the middle of the queue:
Inserted within the middle of the queue. Usually we don't have to wake up the event queue unless there is a barrier at the head of the queue and the message is the earliest asynchronous message in the queue.
else {
needWake = mBlocked && p.target == null && msg.isAsynchronous();
Message prev;
for (;;) {
prev = p;
p = p.next;
if (p == null || when < p.when) {
break;
}
if (needWake && p.isAsynchronous()) {
needWake = false;
}
}
msg.next = p; // invariant: p == prev.next
prev.next = msg;
}
First find out several nodes, prev, current and next. The current message queue is mMessages. The added message msg traverses the message linked list through an endless loop. Note that the conditions for loop exit * * if (P = = null | when < p.when) * * are also discussed in two cases:
1. When the tail of the linked list is not traversed, i.e. P is not null, the delay time when is compared. If when < p.when, msg should be inserted before P.
2. When p = = null, it means that it has reached the end of the linked list. At this time, the loop jumps out of MSG next = p; prev. next = msg. Here MSG is actually placed at the end of the linked list.
3. Look at the assignment operation of needWake, * * needWake = mblocked & & p.target = = null & & MSG isAsynchronous();** This condition is relatively strict. When will the queue wake up? The queue is in sleep state, and the target of the first message in the queue is empty (Handler). The queue will wake up only when the msg to be inserted is an asynchronous message.
tips: this loop is actually a little windy. It should be understood that the prev value is updated before each traversal, and the head node is moved back by a p = p.next; Then start traversal. When the conditions meet the insertion position, the front and rear nodes of msg can correspond to each other. Generally speaking, this prev is actually the prev of msg. It should be understood that P and prev are constantly changing in the process of traversal.
msg message insertion diagram:

- Key method - get message Message next()
Message next() {
final long ptr = mPtr;
if (ptr == 0) {
return null;
}
int pendingIdleHandlerCount = -1; // -1 only during first iteration
int nextPollTimeoutMillis = 0;
for (; ; ) {
if (nextPollTimeoutMillis != 0) {
Binder.flushPendingCommands();
}
//method 1
nativePollOnce(ptr, nextPollTimeoutMillis);
synchronized (this) {
// Try to retrieve the next message. Return if found.
final long now = SystemClock.uptimeMillis();
Message prevMsg = null;
Message msg = mMessages;
//method 2
if (msg != null && msg.target == null) {
// Stalled by a barrier. Find the next asynchronous message in the queue.
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous());
}
//method 3
if (msg != null) {
if (now < msg.when) {
//method 4
// Next message is not ready. Set a timeout to wake up when it is ready.
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
//method 5
// Got a message.
mBlocked = false;
if (prevMsg != null) {
prevMsg.next = msg.next;
} else {
mMessages = msg.next;
}
msg.next = null;
msg.markInUse();
return msg;
}
} else {
//method 6
nextPollTimeoutMillis = -1;
}
if (mQuitting) {
dispose();
return null;
}
if (pendingIdleHandlerCount < 0 && (mMessages == null || now < mMessages.when)) {
pendingIdleHandlerCount = mIdleHandlers.size();
}
if (pendingIdleHandlerCount <= 0) {
mBlocked = true;
continue;
}
if (mPendingIdleHandlers == null) {
mPendingIdleHandlers = new IdleHandler[Math.max(pendingIdleHandlerCount, 4)];
}
mPendingIdleHandlers = mIdleHandlers.toArray(mPendingIdleHandlers);
}
for (int i = 0; i < pendingIdleHandlerCount; i++) {
final IdleHandler idler = mPendingIdleHandlers[i];
mPendingIdleHandlers[i] = null; // release the reference to the handler
boolean keep = false;
try {
keep = idler.queueIdle();
} catch (Throwable t) {
}
if (!keep) {
synchronized (this) {
mIdleHandlers.remove(idler);
}
}
}
pendingIdleHandlerCount = 0;
nextPollTimeoutMillis = 0;
}
}
The Message fetch operation code is very long. In addition, it is found that this fetch operation is an endless loop? So the problem is, this will not cause a waste of CPU resources, and there is no ANR. Why? Before understanding these, we need to understand a concept - pipe/epoll mechanism, which actually belongs to the knowledge of Linux pipeline. Generally speaking, when there is a Message, it will wake up the operation. If there is no Message, it will block and release CPU resources. See the official explanation for the specific description. epoll_wait() , the blocking mechanism and wake-up rules are explained as follows:
Note that the timeout interval will be rounded up to the system clock granularity, and kernel scheduling delays mean that the blocking interval may overrun by a small amount. Specifying a timeout of -1 causes epoll_wait() to block indefinitely, while specifying a timeout equal to zero cause epoll_wait() to return immediately, even if no events are available. //Note that the timeout interval is rounded to the system clock granularity, and the kernel scheduling delay means that the blocking interval may exceed a small amount. Specify a //-Timeout of 1 will cause epoll_wait() blocks indefinitely, and specifying a timeout equal to zero causes epoll_wait() returns immediately, even if no events are available.
Note several key points:
1. When the timeout time is - 1, it will be blocked all the time (that is, the reason why the dead loop in the next() method will be blocked all the time).
2. When it is equal to 0, the result will be returned immediately.
3. When it is greater than 0, the result is returned when the timeout time is reached, but this result is inaccurate. Due to the operation scheduled by the system and the execution time of some methods, this time may be rounded (this point that needs to be understood will be explained later).
From the step-by-step analysis of marked methods 1-7, the method nativePollOnce of method 1, as explained earlier, is a wake-up mechanism for pipes in Linux. When the wake-up timeout is 0, it means that the result is returned directly without blocking; nextPollTimeoutMillis = 0. The default is 0. In method 2, you can actually see the definition of synchronization barrier message, that is, msg is not empty, but msg Target (handler) is null. If the synchronization barrier is encountered, enter the do while loop to get the first asynchronous message in the queue. If there is no asynchronous message, msg is still the head of the queue when method 3 is reached. In short, if it is a synchronous barrier, the first asynchronous message in the queue is taken; otherwise, the queue header message is taken. It's easy to understand. According to the priority order, the acquisition of messages naturally starts from the header, but if there is a synchronization barrier, asynchronous messages will be executed first. method 4 compares the delay information with the current time interval to judge whether it has reached the execution time. If the execution time is not reached, update the value of nextPollTimeoutMillis. Conversely, go to method 5 to get the message and return it for processing. However, it should be noted here that it determines whether it is a synchronization barrier message prevmsg= Null is used to determine the next traversal order of the message header head. method 6 if no message is obtained, set nextPollTimeoutMillis = -1. If the pipeline mechanism mentioned above is - 1, it will enter blocking and wait to give up CPU resources (of course, assuming that the idle handler is not set). The whole is summarized as follows:
1. The acquisition of Message in messagequeue is an endless loop, but the pipe/epoll mechanism of Linux is available internally. This mechanism can control blocking and wake-up according to the timeout length. When it is * * - 1, it means blocking waiting for wake-up, and when it is 0, it will return the result immediately; When it is greater than 0 * *, it wakes up when the specified time interval is reached. However, due to the time-consuming scheduling of the kernel, the accuracy of this time is inaccurate and there is rounding.
2. If there is a synchronization barrier in the message queue, the first asynchronous message is obtained first for execution. If there is no asynchronous message, it is still obtained in sequence according to the queue message.
3. The obtained msg will match the current * * systemclock Uptimemillis() * * compare the timestamp to determine whether to execute immediately or delay to the specified time.
4. When the message in the queue is empty and IdleHandler is not set, reset the parameter nextPollTimeoutMillis to - 1 to block the resources of the CPU and wait for the message to wake up.
3.Implementation of Looper
Class used to run a message loop for a thread. Threads by default do not have a message loop associated with them.
The class used by a thread to open a message loop. By default, a thread has no message loop associated with it. The obtained message is handled by the Handler.
In the Handler mechanism, the loop is equivalent to a conveyor belt, which continuously takes messages from the MessageQueue and distributes them to the Handler for processing. The main parameters are:
@UnsupportedAppUsage //sThreadLocal.get() will return null unless you've called prepare(). static final ThreadLocal<Looper> sThreadLocal = new ThreadLocal<Looper>(); @UnsupportedAppUsage final MessageQueue mQueue; final Thread mThread; @UnsupportedAppUsage private static Looper sMainLooper; // guarded by Looper.class
There are not many parameters. It holds a message queue and uses TLS as the storage container of objects. There is no need to talk about the characteristics of TLS. It ensures the one-to-one correspondence with threads.
- Open Looper
public static void prepare() {
prepare(true);
}
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}
private Looper(boolean quitAllowed) {
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread();
}
When calling the prepare() method to instantiate a Looper object, pay attention to the details. First, judge whether there is an object contained in sThreadLocal. If so, throw an exception directly. If not, instantiate one and store it in TLS, using the current thread as the key. Back to the question mentioned earlier, how many loopers does a thread have? How to guarantee?, It can be explained here that a thread has only one Looper object, and the content uses TLS storage objects to ensure uniqueness. In Android, the Loop of the main thread has actually been instantiated for us. What should we do if a Loop loop Loop is opened in the sub thread? The official gave the template:
class LooperThread extends Thread {
public Handler mHandler;
public void run() {
Looper.prepare();
mHandler = new Handler() {
public void handleMessage(Message msg) {
// process incoming messages here
}
};
Looper.loop();
}
}
That is, if you want to use Loop in a child thread, you must manually open the Loop loop Loop prepare()->Looper. Loop().
- Loop message ()
public static void loop() {
final Looper me = myLooper();
if (me == null) {
throw new RuntimeException("No Looper; Looper.prepare() wasn't called on this thread.");
}
if (me.mInLoop) {
//code
}
me.mInLoop = true;
final MessageQueue queue = me.mQueue;
for (;;) {
Message msg = queue.next(); // might block
//....
try {
msg.target.dispatchMessage(msg);
} catch {}
}
}
The important method loop() is easy to implement, and it is also an endless loop. We have analyzed the whole process of obtaining messages through next() in MessageQueue. Here we mainly look at the operations after obtaining Message objects. The code is very simple - MSG target. dispatchMessage(msg). Distributed directly through targer. So what is the target? Look at the code in the Message class:
public final class Message implements Parcelable {
public int what;
public int arg1;
public int arg2;
public Object obj;
/*package*/ Bundle data;
/*package*/ Handler target;
/*package*/ Message next;
/*package*/ Runnable callback;
}
Now that we know that the target is actually an internally held Handler object, when is the target assigned? See the method of constructing Message:
public static Message obtain() {
synchronized (sPoolSync) {
if (sPool != null) {
Message m = sPool;
Pool = m.next;
m.next = null;
m.flags = 0; // clear in-use flag
sPoolSize--;
return m;
}
}
return new Message();
}
public static Message obtain(Handler h) {
Message m = obtain();
m.target = h;
return m;
}
public static Message obtain(Handler h, int what) {
Message m = obtain();
m.target = h;
m.what = what;
return m;
}
//.......
sPool is used inside the Message, and the recommended way to obtain the Message is through obtain, which uses the idea of pooling, and the continuous creation of objects consumes a lot of performance. Improve efficiency by reusing Message objects in the pool. Secondly, it is also known through the obtain parameter that this target is the Handler itself that sends the Message. From here, we can see that whoever sends the Message will process the Message. When the Handler is created in the UI thread, even if the Message is sent in the child thread, and MSG The target is still handled by the Handler itself, that is, by itself; The Message is forwarded from the child thread to the UI thread. Of course, you can update the UI. If the Handler is created in the child thread and sends messages from the main thread, the natural messages will be processed in the child thread, that is, the thread switching operation is completed. But the * * Handler mentioned earlier What happens when dispatchmessage() * * is used to send messages? Take a look at the test case:
/**
* Created by Sai
* on 2022/1/19 09:21.
* Description:
*/
public class HandlerThread extends Handler {
@Override
public void handleMessage(@NonNull Message msg) {
Log.d("HandlerThread", "Handler:" + Thread.currentThread().getId() + " & arg1=" + msg.arg1);
super.handleMessage(msg);
}
}
public class MainActivity extends AppCompatActivity {
private final HandlerThread handlerTest = new HandlerThread();
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
Log.d("HandlerThread", "Main:" + Thread.currentThread().getId());
Message msg3 = handlerTest.obtainMessage();
msg3.arg1 = 3;
handlerTest.dispatchMessage(msg3);
test();
}
private void test() {
new Thread(() -> {
Log.d("HandlerThread", "Thread:" + Thread.currentThread().getId());
Message msg = handlerTest.obtainMessage();
msg.arg1 = 1;
handlerTest.dispatchMessage(msg);
Message msg2 = handlerTest.obtainMessage();
msg2.arg1 = 2;
handlerTest.sendMessage(msg2);
}).start();
}
}
Log information printed:
com.handlerapp D/HandlerThread: Main:2 com.handlerapp D/HandlerThread: Handler:2 & arg1=3 com.handlerapp D/HandlerThread: Thread:422 com.handlerapp D/HandlerThread: Handler:422 & arg1=1 com.handlerapp D/HandlerThread: Handler:2 & arg1=2
Messages 1 and 2 are sent in the sub thread using dispatchMessage and sendMessage respectively, while message 3 is sent in the main thread using dispatchMessage. Looking at the printed information, it can be found that handlerTest is created in the main thread and the purpose of line switching is achieved through sendMessage (enqueueMessage is used internally, and there is a process of entering the queue). However, when using dispatchMessage, the message processing flow is directly followed.
public void dispatchMessage(@NonNull Message msg) {
if (msg.callback != null) {
handleCallback(msg);
} else {
if (mCallback != null) {
if (mCallback.handleMessage(msg)) {
return;
}
}
handleMessage(msg);
}
}
Now it is clear that the calling thread of dispatchMessage is its processing thread, and the processing thread of sendMessage message is the creation thread of handler. The whole process is as follows (pictures from the network):
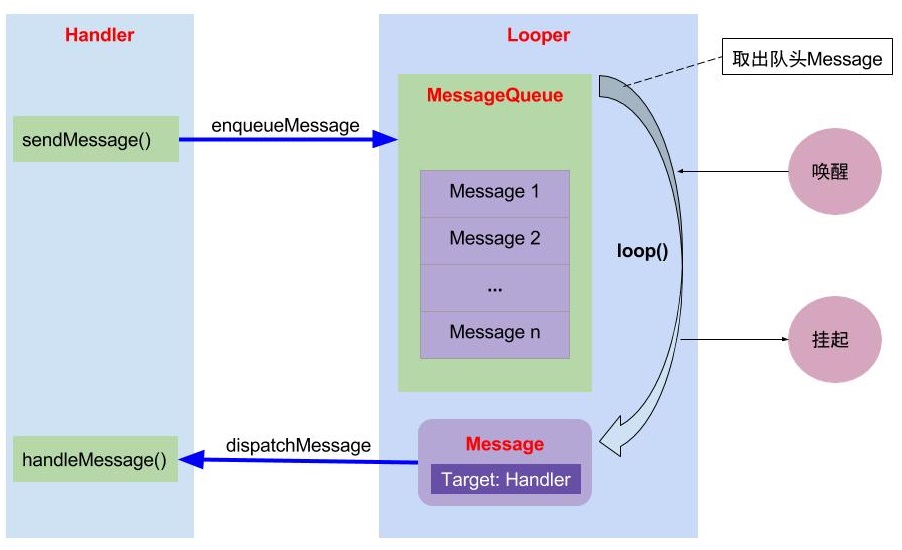
4, Solve problems
- How many handlers does a thread have? How many loopers does a thread have? How to guarantee? How many messagequeues can a thread have?
A Thread can have multiple Handler objects. The instantiation of Handler does not verify the Thread. A Thread can only have one Looper object, because TLS storage is used internally, and the current Thread is verified to ensure that there is only one object. Secondly, MessageQueue is created when the Looper is instantiated, so it corresponds to the Looper one by one.
private Looper(boolean quitAllowed) {
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread();
}
- How to create a Message object?
It is recommended to use obtain to obtain a Message object, so as to reuse the Message object in the Message pool (sPool).
- What is the root cause of the Handler memory leak? Do internal classes cause memory leaks?
The root cause of memory leak caused by handler is that the life cycle of handler is longer than that of Activity. When there are delayed messages in handler and they do not arrive (not processed). At this time, the Activity is destroyed, but the handler cannot be recycled? That is, a typical object with a short life cycle holds an object with a long life cycle. As we usually write, the click event of view is also in the form of internal class, but it will not cause memory leakage. The fundamental reason is that the life cycle of view is shorter than that of Activity.
- How to instantiate a Handler object in the main thread and in the child thread?
The main thread can be instantiated directly because the system has implemented the mloop object for us, but there is no looper object associated with it in the child thread by default. Looper. Needs to be called prepare() -> Looper. Loop() to start the message loop.
- Why does Looper loop not lead to ANR application and consume resources?
Looper loop will block in message In next (), the root cause is that the pipe/epoll mechanism in Linux is used internally. When the timeout parameter is 0, the result can be returned immediately, and when - 1, it will be blocked directly until it is awakened, but the CPU resources will be released during blocking. Therefore, it will not cause waste of resources. The ANR here is essentially different from the dead cycle. The main thread itself needs to loop all the time. If you exit, the App will exit
- Loop is maintained in the sub thread. How to handle when there is no message in the message queue? What's the usage?
You should exit this looper safely
public void quitSafely() {
mQueue.quit(true);
}
- How does the message queue change after using the Handler's postDelay?
The sending of delayed messages is mainly determined by the insertion of MessageQueue in the message queue
- How can multiple handlers ensure thread safety?
After analysis, it is known that no matter how many handlers are implemented, msg Target holds the handler itself, that is, who sends it and who processes it. Of course, whether enqueueMessage or message The synchronized synchronization lock mechanism is used in next.
- Implementation of delayed messages?
Delay messages only need to be sent with the delay interval, but it should be clear that due to the scheduling mechanism of the kernel, the wake-up time of pipe/epoll is not accurate enough, which is determined by the system. Therefore, it is not enough to rely only on the handler to achieve accurate delayed messages.