What problems does the Android collaboration solve?
- Handle time-consuming tasks that often block the main thread
- Ensure that the main thread is safe and that any suspend function is safely called from the main thread
Example (asynchronous task)
Implement an example of requesting network data: there is a button, a loading and a textview on the page to display the results. Click button to display loading, send a request to the server, get the data, display the result on the textview, and hide loading.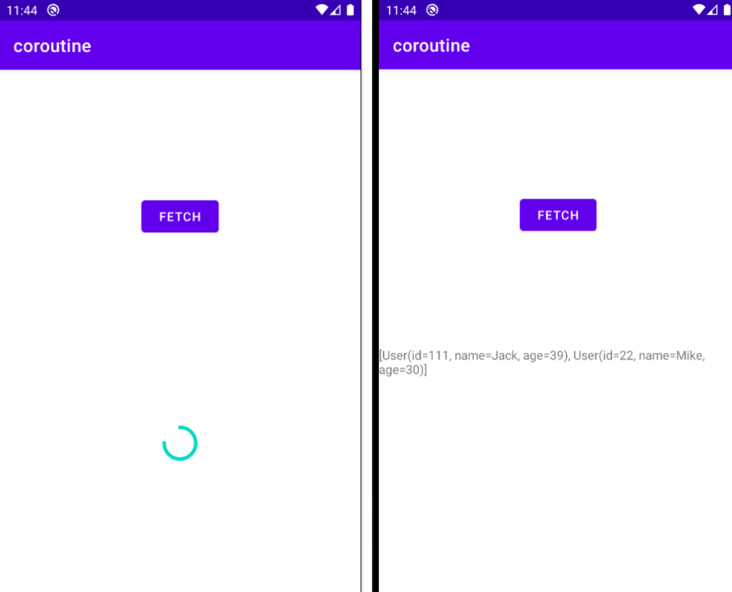
The interface is as follows
Service and Retrofit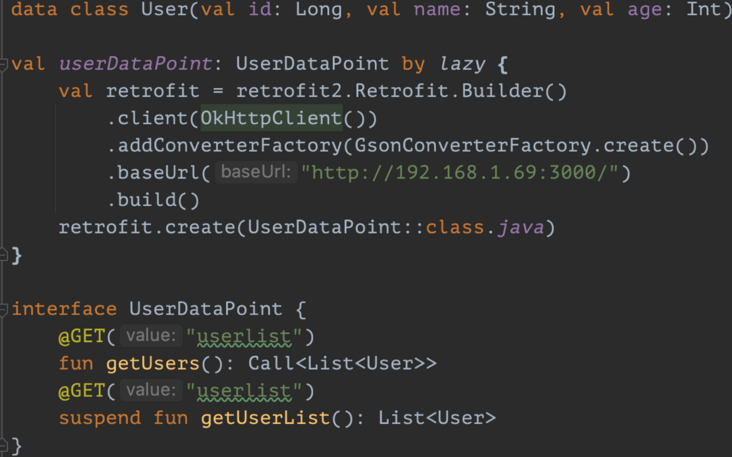
getUsers() is called by AsyncTask, and getUserList() is a suspend method called by coroutine.
How to use AsyncTask
private fun doWithAsyncTask() { val task = object : AsyncTask<Void, Void, List<User>>() { override fun onPreExecute() { super.onPreExecute() showLoading() } override fun doInBackground(vararg p0: Void?): List<User>? { return userDataPoint.getUsers().execute().body() } override fun onPostExecute(result: List<User>?) { super.onPostExecute(result) Log.d(TAG, "onPostExecute: done.") showData(result) } } task.execute() }
Using a coroutine, call the suspend function suspend
private fun doWithCoroutine() {
GlobalScope.launch(Dispatchers.Main) {
showLoading()
val users = withContext(Dispatchers.IO) {
userDataPoint.getUserList()
}
showData(users)
}
}Let's learn more about the collaborative process and its benefits.
What is a collaborative process?
Coprocessing synchronizes asynchronous logic and eliminates callback hell.
The core of a coroutine is that a function or a program can be suspended and restored at the suspended position later.
Suspension and recovery of collaboration
The basic operations of regular functions include invoke (or call) and return. suspend and resume are added to the coroutine
- Suspend, also known as suspend or suspend, is used to suspend the execution of the current coroutine and save all local variables.
- Resume is used to resume the execution of a suspended process from its suspended position.
Suspend function
- A function decorated with the suspend keyword is called a suspend function
Suspended functions can only be called within a coroutine body or other suspended functions
Difference between hang and block
Case comparison: delay(5000) in the coroutine is a suspend function, and thread in Java Sleep (5000) is a blocking function.
For example, in the click event, calling the delay function in the association will not block the main thread and what the main thread should do. However, using sleep will block the main thread. The main thread is stuck there and waits for 5 seconds to continue.Two parts of the collaborative process
- The infrastructure layer, the standard library's collaboration API, mainly provides the most basic conceptual and semantic support for collaboration.
The business framework layer is supported by the upper framework of the collaboration process. GlobalScope and delay functions all belong to this layer.
Using the infrastructure layer to create a collaboration process will be a lot of trouble, so the business framework layer is mostly used in development.
For example, the relationship between NIO and Netty. NIO is the basic API and Netty is the business framework based on NIO. Take a look at a collaboration created using the infrastructure layer and its implementation.// Create a process body val continuation = suspend { userDataPoint.getUserList() }.createCoroutine(object: Continuation<List<User>>{ override val context: CoroutineContext = EmptyCoroutineContext override fun resumeWith(result: Result<List<User>>) { Log.d(TAG, "resumeWith: ${result.getOrNull()}") } }) // Start process continuation.resume(Unit)In fact, it's still callback...
In the above example, the basic framework uses kotlin The API under the coroutines package, and the business framework layer uses kotlinx API under coroutines packageScheduler
All coroutines must run in the scheduler, even if they run on the main thread.
Dispatchers.Main, the main thread on Android, handles UI interaction and some lightweight tasks
- Call suspend function
- Call UI function
- Update LiveData
Dispatchers.IO, disk and network IO
- database
- File reading and writing
- network processing
Dispatchers.Default, non main thread, CPU intensive task
- Array sorting
- JSON parsing
- Processing difference judgment
Task disclosure
When a collaborative task is lost and cannot be tracked, it will waste resources such as memory, CPU and disk, and even send a useless network request. This situation is called task leakage.
- For example, click the button to send a request to the server. Before the server has finished processing, press the return key to exit the application. The Activity has been destroyed. At this time, the network request is still in progress. The network request object still occupies memory, and task leakage will occur.
In order to avoid the disclosure of collaborative tasks, Kotlin introduces a structured concurrency mechanism.
Structured concurrency
This can be done using structured concurrency
- Cancel a task. Cancel a task when it is no longer needed.
- Track a task. When a task is executing, track it.
Send an error signal. When the collaboration fails, send an error signal to indicate that an error has occurred.
Coroutine scope
Defining a collaboration must specify its CoroutineScope, which will track all collaborations and cancel all collaborations started by it.
Common API s are:- For GlobalScope, the life cycle is process level. Even if the Activity/Fragment is destroyed, the collaboration process is still executing.
- MainScope, used in Activity, can cancel a collaboration in onDestroy.
- viewModelScope, which can only be used in ViewModel, binds the lifecycle of ViewModel.
- lifecycleScope, which can only be used in Activity/Fragment, binds the life cycle of Activity/Fragment.
MainScope:
private val mainScope = MainScope()
private fun doWithMainScope() {
mainScope.launch {
try {
showLoading()
val users = userDataPoint.getUserList()
showData(users)
} catch (e: CancellationException) {
Log.d(TAG, "CancellationException: $e")
showData(emptyList())
}
}
}
override fun onDestroy() {
super.onDestroy()
mainScope.cancel()
}In the callback of Activity destruction, canceling mainScope will cancel the tasks inside and throw a cancelationexception. You can handle the cancelled operation in catch.
In addition, MainScope is CoroutineScope. CoroutineScope is an interface that allows an activity to implement the interface and use MainScope as the delegate object by default. In this way, you can directly use launch and cancel in the activity.
class MainActivity : AppCompatActivity(), CoroutineScope by MainScope()
//private val mainScope = MainScope()
private fun doWithMainScope() {
launch {
showLoading()
try {
val users = userDataPoint.getUserList()
showData(users)
} catch (e: CancellationException) {
Log.d(TAG, "CancellationException: $e")
showData(emptyList())
}
}
}
override fun onDestroy() {
super.onDestroy()
cancel()
}Startup and cancellation of collaboration
Start process
- Start builder
- Startup mode
- Scope builder
- Job lifecycle
Cancel collaboration
- Cancellation of collaboration
- CPU intensive task cancellation
- Side effects of collaborative process cancellation
- Timeout task
Collaborative process builder
Both the launch and async builders are used to start new processes
- launch, which returns a Job without any results
- async returns a Deferred, which is also a Job and can be used await() gets its final result on a Deferred value.
Waiting for a job - join and await. Both are suspended functions and do not block the main thread.
Combination development
Example 1: launch and async start the process
GlobalScope is a top-level collaboration and is not recommended. runBlocking can wrap the test method into a co process, and the test method runs on the main thread. In a collaboration, you can start the collaboration with launch and async.
@Test fun test_coroutine_builder() = runBlocking { val job1 = launch { delay(2000) println("job1 finished.") } val job2 = async { delay(2000) println("job2 finished") "job2 result" } println("job1: $job1") println("job2: $job2") println("job2: ${job2.await()}") }Output results
job1: "coroutine#2":StandaloneCoroutine{Active}@71b1176b job2: "coroutine#3":DeferredCoroutine{Active}@6193932a job1 finished. job2 finished job2: job2 resultBoth builders can start the co process. As above, await can get the result returned by the async builder. job1 and job2 are sub processes in the main process of runBlocking packaging. After the two sub processes are executed, the main process will exit.
Coordination execution sequence
@Test fun test_join() = runBlocking { val start = System.currentTimeMillis() println("start: ${System.currentTimeMillis() - start}") val job1 = launch { delay(2000) println("job1, ${System.currentTimeMillis() - start}") } val job2 = launch { delay(1000) println("job2, ${System.currentTimeMillis() - start}") } val job3 = launch { delay(5000) println("job3, ${System.currentTimeMillis() - start}") } println("end: ${System.currentTimeMillis() - start}") }Start three cooperative processes with launch, delaying 2 seconds in job1, 1 second in job2 and 5 seconds in job3. Execution result output
start: 0 end: 8 job2, 1018 job1, 2017 job3, 5018
Start and end swish and finish printing in the main cooperative process. In the middle, start three cooperative processes with the launch starter for 8 milliseconds. job2 prints after 1 second, job1 prints after 2 seconds, and job3 prints after 5 seconds.
Example 2: join
If you want to control their order, use the join function:
@Test fun test_join() = runBlocking { val start = System.currentTimeMillis() println("start: ${System.currentTimeMillis() - start}") val job1 = launch { delay(2000) println("job1, ${System.currentTimeMillis() - start}") } job1.join() val job2 = launch { delay(1000) println("job2, ${System.currentTimeMillis() - start}") } job2.join() val job3 = launch { delay(5000) println("job3, ${System.currentTimeMillis() - start}") } println("end: ${System.currentTimeMillis() - start}") }The results are as follows:
start: 0 job1, 2016 job2, 3022 end: 3024 job3, 8025
start, then execute job1 and print job1. At this time, 2016ms has passed because the task in job1 has been delay ed for 2s.
Then execute job2 and print job2. Because the task in job2 is delay ed for 1s, the time at this time passes about 3s.
The join function is not used for job3, so end is printed directly. After another 5 seconds, job3 delay is completed, and job3 is printed.
If you call the join() function on job3 before end, the result is as follows:start: 0 job1, 2014 job2, 3018 job3, 8019 end: 8019
end prints after job3 is executed.
Example 3: await
Test await:
fun test_await() = runBlocking { val start = System.currentTimeMillis() println("start: ${System.currentTimeMillis() - start}") val job1 = async { delay(2000) println("job1, ${System.currentTimeMillis() - start}") "result 1" } println(job1.await()) val job2 = async { delay(1000) println("job2, ${System.currentTimeMillis() - start}") "result 2" } println(job2.await()) val job3 = async { delay(5000) println("job3, ${System.currentTimeMillis() - start}") "result 3" } println(job3.await()) println("end: ${System.currentTimeMillis() - start}") }Output results
start: 0 job1, 2018 result 1 job2, 3027 result 2 job3, 8032 result 3 end: 8033
await also allows the sub processes to execute in order and returns the results after the process is executed.
combination
@Test fun test_sync() = runBlocking { val time = measureTimeMillis { val one = firstTask() val two = secondTask() println("result: ${one + two}") } println("total time: $time ms") } private suspend fun firstTask(): Int { delay(2000) return 3 } private suspend fun secondTask(): Int { delay(2000) return 6 }Two tasks, each delayed for 2 seconds, and then returned a value; In the test function, use measureTimeMillis in the main collaboration to calculate the time consumption of the code block, then print it, get the return values of the two tasks, and then add and output the results
result: 9 total time: 4010 ms
It takes more than 4 seconds in total. The second task takes 2 seconds after the first task is executed.
Example 4: using async
Use async to execute two tasks at the same time, and use await to obtain the returned results. See an example:
@Test fun test_combine_async() = runBlocking { val time = measureTimeMillis { val one = async { firstTask() } val two = async { secondTask() } println("result: ${one.await() + two.await()}") } println("total time: $time ms") }give the result as follows
result: 9 total time: 2025 ms
It takes about 2 seconds in total, and the two tasks are executed at the same time.
Use the above example to sort out the process again. runBlocking ensures that it is the main collaboration started in the main thread. Then, in line 4, it starts the collaboration one in the main collaboration to execute the task firstTask. In line 5, it starts the collaboration two in the main collaboration to execute the task secondTask. The total tasks of the two subprocesses, one and two, are executed concurrently. In line 6, wait for both one and two to return results, Add the two and output the result.
Look at the following wording:@Test fun test_combine_async_case2() = runBlocking { val time = measureTimeMillis { val one = async { firstTask() }.await() val two = async { secondTask() }.await() println("result: ${one + two}") } println("total time: $time ms") }In line 4, start the co process one and wait for the result, which takes about 2 seconds; Then start the co process two in line 5 and wait for the result. It takes about 2 seconds. Calculate in line 6 and output the result. It took more than four seconds. If you want parallel effects, this is wrong.
result: 9 total time: 4018 ms
Startup mode of collaborative process
public fun CoroutineScope.launch( //Context fetcher context: CoroutineContext = EmptyCoroutineContext, //Startup mode start: CoroutineStart = CoroutineStart.DEFAULT, //Co process method block: suspend CoroutineScope.() -> Unit ): Job { val newContext = newCoroutineContext(context) val coroutine = if (start.isLazy) LazyStandaloneCoroutine(newContext, block) else StandaloneCoroutine(newContext, active = true) coroutine.start(start, coroutine, block) return coroutine }In the construction method, the second parameter is the startup mode, which defaults to DEFAULT. There are four modes.
- DEFAULT: start scheduling immediately after the collaboration is created. If the collaboration is cancelled before scheduling, it will directly enter the status of cancellation response.
- ATOMIC: scheduling starts immediately after the collaboration is created. The collaboration will not respond to cancellation until it reaches the first hanging point.
- LAZY: scheduling will be started only when the collaboration is needed, including actively calling the start, join or await functions of the collaboration. If the scheduling is cancelled before scheduling, the collaboration will directly enter the abnormal end state.
UNDISPATCHED: the coroutine is executed in the current function call stack immediately after it is created until the first real hang point is encountered.
Note: scheduling does not represent execution.
It can be understood that there is a queue. Scheduling is to add the tasks of the collaboration process to the queue, which does not mean execution.
There is a time interval from scheduling to execution; A collaboration can be cancelled.public enum class CoroutineStart { //After the collaboration is created. Start scheduling now. If the collaboration is cancelled before scheduling. Directly enter the state of canceling the response DEFAULT, //When we need him to execute, we will execute, otherwise we won't execute. LAZY, //Start scheduling immediately. The cancellation will not be responded to before the first hang point ATOMIC, //After creating a coroutine, it is executed in the call stack of the current function. Until the first hanging point is encountered. UNDISPATCHED }DEFAULT
Start scheduling immediately after the collaboration is created. If it is cancelled before scheduling, it will directly enter the state of cancellation response.
Start scheduling immediately after a collaboration is created: it means that after a collaboration is created, it is added to the scheduler, that is, the queue mentioned above. The task will trigger itself without start() or join(). The following test code shows that start () has no effect on the test results.
If it is cancelled before scheduling, it will directly enter the cancellation response state: This is more interesting. As mentioned earlier, creating a collaboration will be added to the queue and the task will trigger itself. It is difficult to control the time of canceling. Is it before or after the task is executed? Even if you cancel immediately after the collaboration is created, it is possible that the scheduler is already executing the code block of the collaboration.
@Test
fun test_fib_time() {
val time = measureTimeMillis {
println("result: ${fib(45)}")
}
println("time used: $time")
}
private fun fib(n: Int): Long {
if (n == 1 || n == 2) return 1L
return fib(n - 1) + fib(n - 2)
}This is a code for calculating Fibonacci sequence. It takes about 3 seconds to calculate 45.
result: 1134903170 time used: 3132
Let's look at the test code. Use DEFAULT to start the process. fib(46) is calculated in the process. This is a time-consuming operation > 3S:
@Test
fun test_default() {
val start = System.currentTimeMillis()
val job = GlobalScope.launch(start = CoroutineStart.DEFAULT) {
println("Job started. ${System.currentTimeMillis() - start}")
val res = fib(46)
println("result: $res")
println("Job finished. ${System.currentTimeMillis() - start}")
}
job.cancel()
println("end.")
}Two results can be obtained by running several more times.
Result 1 is as follows:
end. Job started. 124
Result 2 is as follows:
end.
Result 1: after the job was created, it started scheduling immediately and was added to the queue. Without calling the start() or join() methods, the task triggered itself and was cancel led when executing time-consuming operations.
Result 2: after the job was created, it started scheduling immediately and was added to the queue. It was cancel led before it could be triggered by itself.
Therefore, it is difficult to grasp the time of cancel. Cancel immediately after creation, and the scheduler may or may not have time to execute the task. And calling start(),join(), has no effect. You can call start() before cancel, and the effect is the same.
LAZY
Only execute when collaborative process execution is required, otherwise it will not be executed. If it is cancelled before scheduling, it will directly enter the abnormal end state.
It can only be executed when it needs to be executed, that is, it can only be started when start() or join() is executed. Whether to execute the co process depends on whether to start().
If it is cancelled before scheduling, it will directly enter the abnormal end state, that is, add the collaboration task to the scheduler and wait for execution. If the collaboration is cancelled at this time, it will not be executed.
@Test
fun test_lazy() {
val start = System.currentTimeMillis()
val job = GlobalScope.launch(start = CoroutineStart.LAZY) {
println("Job started. ${System.currentTimeMillis() - start}")
val res = fib(46)
println("result: $res")
println("Job finished. ${System.currentTimeMillis() - start}")
}
job.cancel()
println("end.")
}Using LAZY to start the process, the test results will always be output
end.
Because without start, it will never be executed.
However, adding start() does not guarantee that it will be executed. for example
@Test
fun test_lazy() {
val start = System.currentTimeMillis()
val job = GlobalScope.launch(start = CoroutineStart.LAZY) {
println("Job started. ${System.currentTimeMillis() - start}")
val res = fib(46)
println("result: $res")
println("Job finished. ${System.currentTimeMillis() - start}")
}
job.start()
job.cancel()
println("end.")
}Line 10 adds start(), but the result may be execution or it may end before execution.
Change the position of lines 10 and 11 and cancel first. At start, you can never enter execution.
ATOMIC
After the collaboration process is created, it starts scheduling immediately. The collaboration process will not respond to cancellation until it reaches the first hanging point.
@Test
fun test_atomic() = runBlocking {
val start = System.currentTimeMillis()
val job = launch(start = CoroutineStart.ATOMIC) {
println("Job started. ${System.currentTimeMillis() - start}")
val result = fib(46)
println("result $result")
delay(1000)
println("Job finished. ${System.currentTimeMillis() - start}")
}
job.cancel()
println("end.")
}result:
end. Job started. 9 result 1836311903 Process finished with exit code 0
The first hanging point is the delay hanging function on line 8, so the Job started is printed after the Job is executed. Although it is cancelled, it will not respond to cancellation until the first hanging point is executed. It will not respond to cancel until the fib function result is printed for about 5 seconds.
In applications, operations that cannot be cancelled are usually placed before the pending function, and the cancellation is responded only after its execution is completed.
UNDISPATCHED
After the coprocessor is created, it is executed in the current function call stack immediately until the first real hang point is encountered.
@Test
fun test_un_dispatched() = runBlocking {
val start = System.currentTimeMillis()
val job = launch(context = Dispatchers.IO, start = CoroutineStart.UNDISPATCHED) {
println("Job started. ${Thread.currentThread().name}, ${System.currentTimeMillis() - start}")
val result = fib(46)
println("result $result ${System.currentTimeMillis() - start}")
delay(1000)
println("Job finished. ${System.currentTimeMillis() - start}")
}
job.cancel()
println("end.")
}result
Job started. main @coroutine#2, 3 result 1836311903 5073 end. Process finished with exit code 0
Specify context = dispatchers when starting a collaboration IO is started in undispatched mode. During the execution of the collaboration, the current thread name is printed. It is the main thread, not the IO thread. Because runBlocking is running on the main thread, that is, the current function call stack.
Scope builder for a collaboration
coroutineScope and runBlocking
runBlocking is a regular function, which is mainly used for main functions and tests, while coroutineScope is a suspended function
They will all wait for the end of their coroutine body and all child coroutines. The main difference is that the runBlocking method will block the current thread to wait, while coroutineScope is only suspended and will release the underlying thread for other purposes.
runBlocking example
@Test
fun test_coroutine_scope_runBlocking() {
val start = System.currentTimeMillis()
runBlocking {
val job1 = async {
println("job 1 start. ${System.currentTimeMillis() - start}")
delay(400)
println("job 1 end. ${System.currentTimeMillis() - start}")
}
val job2 = launch {
println("job 2 start. ${System.currentTimeMillis() - start}")
delay(200)
println("job 2 end. ${System.currentTimeMillis() - start}")
}
println("runBlocking end.")
}
println("Program end.")
}Output results
runBlocking end. job 1 start. 121 job 2 start. 127 job 2 end. 333 job 1 end. 525 Program end. Process finished with exit code 0
Before the program ends, it will wait for the end of the subprocess in runBlocking.
Examples of coroutineScope
@Test
fun test_coroutine_scope_coroutineScope() = runBlocking {
val start = System.currentTimeMillis()
coroutineScope {
val job1 = async {
println("job 1 start. ${System.currentTimeMillis() - start}")
delay(400)
println("job 1 end. ${System.currentTimeMillis() - start}")
}
val job2 = launch {
println("job 2 start. ${System.currentTimeMillis() - start}")
delay(200)
println("job 2 end. ${System.currentTimeMillis() - start}")
}
println("coroutineScope end.")
}
println("Program end.")
}Output results
coroutineScope end. job 1 start. 16 job 2 start. 28 job 2 end. 233 job 1 end. 424 Program end. Process finished with exit code 0
Similarly, it will wait for the sub processes in coroutineScope to end before the program ends. As mentioned above, coroutineScope is a suspended function that needs to be executed in the coroutine. Therefore, runBlocking is used to generate a coroutine environment for coroutineScope to run.
coroutineScope and supervisorScope
- Coroutine scope: if a collaboration fails, other sibling collaborations will also be cancelled.
supervisorScope: if a collaboration fails, it will not affect other sibling collaborations.
For example, the test with coroutineScope failed@Test fun test_coroutine_scope_coroutineScopeFail() = runBlocking { val start = System.currentTimeMillis() coroutineScope { val job1 = async { println("job 1 start. ${System.currentTimeMillis() - start}") delay(400) println("job 1 end. ${System.currentTimeMillis() - start}") } val job2 = launch { println("job 2 start. ${System.currentTimeMillis() - start}") delay(200) throw IllegalArgumentException("exception happened in job 2") println("job 2 end. ${System.currentTimeMillis() - start}") } println("coroutineScope end.") } println("Program end.") }result
coroutineScope end. job 1 start. 15 job 2 start. 24 java.lang.IllegalArgumentException: exception happened in job 2 ... Process finished with exit code 255
Job1 and job2 are two brother processes started in coroutine scope. Job2 fails and job1 does not continue to execute.
For example, if the test with supervisor scope fails, replace the coroutine scope abovesupervisorScope end. job 1 start. 10 job 2 start. 17 Exception in thread "main @coroutine#3" java.lang.IllegalArgumentException: exception happened in job 2 ... job 1 end. 414 Program end. Process finished with exit code 0
Job1 and job2 are two sibling processes started in supervisor scope. If job2 fails and throws an exception, job1 continues to execute until the task is completed.
Job object
For each created collaboration (through launch or async), a Job instance will be returned, which is the unique identifier of the collaboration and is responsible for managing the lifecycle of the collaboration.
A Job can contain a series of states. Although these states cannot be accessed directly, the properties of the Job (isActive, isCancelled, isCompleted) can be accessed- Create New
- Active
- Completing
- Completed
- Canceling
Cancelled
@Test fun test_job_status() = runBlocking { val start = System.currentTimeMillis() var job1: Job? = null var job2: Job? = null job1 = async { println("job 1 start. ${System.currentTimeMillis() - start}") delay(400) job1?.let { println("Job1- isActive:${it.isActive}, isCancelled:${it.isCancelled}, isCompleted:${it.isCompleted}") } job2?.let { println("Job2- isActive:${it.isActive}, isCancelled:${it.isCancelled}, isCompleted:${it.isCompleted}") } println("job 1 end. ${System.currentTimeMillis() - start}") } job2 = launch { println("job 2 start. ${System.currentTimeMillis() - start}") delay(200) job1?.let { println("Job1- isActive:${it.isActive}, isCancelled:${it.isCancelled}, isCompleted:${it.isCompleted}") } job2?.let { println("Job2- isActive:${it.isActive}, isCancelled:${it.isCancelled}, isCompleted:${it.isCompleted}") } println("job 2 end. ${System.currentTimeMillis() - start}") } println("Program end.") }Output:
Program end. job 1 start. 8 job 2 start. 15 Job1- isActive:true, isCancelled:false, isCompleted:false Job2- isActive:true, isCancelled:false, isCompleted:false job 2 end. 216 Job1- isActive:true, isCancelled:false, isCompleted:false Job2- isActive:false, isCancelled:false, isCompleted:true job 1 end. 416 Process finished with exit code 0
After the execution of job2, the information of job2 is printed in job1. Since job2 has been completed, isActive=false, isCompleted=true
Look at the picture below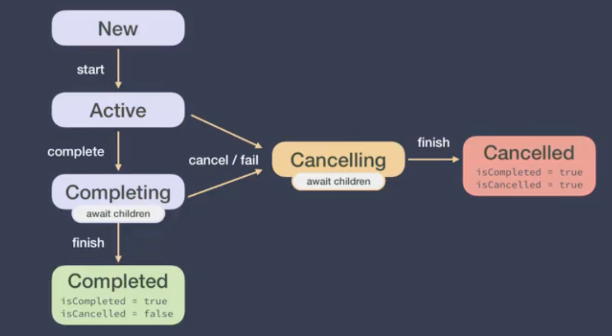
Cancellation of collaboration
- Canceling a scope cancels its children
- The cancelled subprocess will not affect the other sibling subprocesses
- The coroutine handles the cancellation operation by throwing a special cancelationexception
All kotlinx Pending functions (withcontext / delay, etc.) in coroutines are cancelable
Canceling a scope cancels its children
@Test fun test_cancel_2() = runBlocking<Unit> { val scope = CoroutineScope(Dispatchers.Default) val job1 = scope.launch { println("job1 started.") delay(10) println("job1 finished.") } val job2 = scope.launch { println("job2 started.") delay(100) println("job2 finished.") } delay(500) }
output:
job1 started. job2 started. job1 finished. job2 finished. Process finished with exit code 0
Note: runBlocking is the main coroutine. Start two child coroutines with a custom scope. Job1 and job2 are child coroutines in the scope. In line 14, the delay of 500 milliseconds is in the main process and is managed by the scope of the main process. Run the test code, and the program will exit after the suspend function delay 500 is completed. At this time, one of the subprocess job1 and job2 tasks started by scope takes 10 milliseconds and the other takes 100 milliseconds, and can also be completed. If the delay is 50 milliseconds, job1 can be completed during this period, but job2 cannot be completed.
Here's how to cancel the scope:
@Test
fun test_cancel_3() = runBlocking<Unit> {
val scope = CoroutineScope(Dispatchers.Default)
val job1 = scope.launch {
println("job1 started.")
delay(10)
println("job1 finished.")
}
val job2 = scope.launch {
println("job2 started.")
delay(100)
println("job2 finished.")
}
scope.cancel()
delay(500)
}The result is
job1 started. job2 started. Process finished with exit code 0
In line 14, cancel the scope. You can see that job1 and job2 belong to the brother process in the scope. After the scope is cancelled, there will be no skin and hair. They are both cancelled. That is, canceling the scope cancels its child processes.
The cancelled subprocess does not affect other sibling subprocesses
@Test
fun test_cancel_4() = runBlocking<Unit> {
val scope = CoroutineScope(Dispatchers.Default)
val job1 = scope.launch {
println("job1 started.")
delay(10)
println("job1 finished.")
}
val job2 = scope.launch {
println("job2 started.")
delay(100)
println("job2 finished.")
}
job1.cancel()
delay(500)
}result
job1 started. job2 started. job2 finished. Process finished with exit code 0
Canceling job1 does not affect the execution of brother job2.
CancellationException
@Test
fun test_cancel_exception() = runBlocking<Unit> {
val scope = CoroutineScope(Dispatchers.Default)
val job1 = scope.launch {
try {
println("job1 started.")
delay(10)
println("job1 finished.")
} catch (e: Exception) {
println(e.toString())
}
}
job1.cancel("handle the cancellation exception!")
job1.join()
}Output
job1 started. java.util.concurrent.CancellationException: handle the cancellation exception! Process finished with exit code 0
There is also a cancelAndJoin():
@Test
fun test_cancel_exception() = runBlocking<Unit> {
val scope = CoroutineScope(Dispatchers.Default)
val job1 = scope.launch {
try {
println("job1 started.")
delay(10)
println("job1 finished.")
} catch (e: Exception) {
println(e.toString())
}
}
job1.cancelAndJoin()
}The effect is the same.
All kotlinx Pending functions (withcontext / delay, etc.) in coroutines are cancelable
For example, in the above example, the delay() suspend function can be cancel led when the wait is suspended.
Cancellation of CPU intensive tasks
- isActive is an extended property that can be used in CoroutineScope to check whether a Job is active
- ensureActive(), if the job is inactive, this method will immediately throw an exception.
The yield function will check the status of the associated process. If it has been cancelled, it will throw a cancelationexception in response. In addition, it will try to transfer the execution right of the thread to provide execution opportunities for other processes.
@Test fun test_cpu_task() = runBlocking { val start = System.currentTimeMillis(); val job = launch(Dispatchers.Default) { var i = 0 var nextPrintTime = start while (i < 5) { if (System.currentTimeMillis() >= nextPrintTime) { println("job is waiting ${i++}") nextPrintTime += 1000 } } } delay(1000) job.cancel() println("main ended.") }output:
job is waiting 0 job is waiting 1 main ended. job is waiting 2 job is waiting 3 job is waiting 4 Process finished with exit code 0
Job is a CPU intensive task, which is printed every 1 second. Although the job was cancelled, the job finished executing while. To terminate a task, use isActive to add a judgment in the while condition:
@Test fun test_cpu_task_active() = runBlocking { val start = System.currentTimeMillis(); val job = launch(Dispatchers.Default) { var i = 0 var nextPrintTime = start while (i < 5 && isActive) { if (System.currentTimeMillis() >= nextPrintTime) { println("job is waiting ${i++}") nextPrintTime += 1000 } } } delay(1000) job.cancel() println("main ended.") }output:
job is waiting 0 job is waiting 1 main ended. Process finished with exit code 0
This isActive can be used to check the status of the process, but cannot throw an exception. That is, adding try catch does not catch any exceptions. If you want to achieve this effect, you can use the ensureActive() function to check isActive internally and throw an exception:
@Test fun test_cpu_task_active_cancel() = runBlocking { val start = System.currentTimeMillis(); val job = launch(Dispatchers.Default) { try { var i = 0 var nextPrintTime = start while (i < 5) { ensureActive() if (System.currentTimeMillis() >= nextPrintTime) { println("job is waiting ${i++}") nextPrintTime += 1000 } } } catch (e: Exception) { println(e.toString()) } } delay(1000) job.cancel() println("main ended.") }output:
job is waiting 0 job is waiting 1 main ended. kotlinx.coroutines.JobCancellationException: StandaloneCoroutine was cancelled; job="coroutine#2":StandaloneCoroutine{Cancelling}@720b7121 Process finished with exit code 0You can see that the exception jobcancelationexception is thrown and caught.
yeild can also throw exceptions and respond. It can also give thread execution rights to provide execution opportunities for other collaborations.@Test fun test_cpu_task_yield() = runBlocking { val start = System.currentTimeMillis(); val job = launch(Dispatchers.Default) { try { var i = 0 var nextPrintTime = start while (i < 5) { yield() if (System.currentTimeMillis() >= nextPrintTime) { println("job is waiting ${i++}") nextPrintTime += 1000 } } } catch (e: Exception) { println(e.toString()) } } delay(1000) job.cancel() println("main ended.") }output:
job is waiting 0 job is waiting 1 main ended. kotlinx.coroutines.JobCancellationException: StandaloneCoroutine was cancelled; job="coroutine#2":StandaloneCoroutine{Cancelling}@478cdf05 Process finished with exit code 0Side effects of collaborative process cancellation
- Release resources in finally
use function: this function can only be used by objects that implement Coloseable. The close method will be called automatically at the end of the program, which is suitable for file objects.
@Test fun test_release() = runBlocking { val job = launch { try { repeat(1000) { i -> println("job is waiting $i ...") delay(1000) } } catch (e: Exception) { println(e.toString()) } finally { println("job finally.") } } delay(1500) println("job cancel.") job.cancelAndJoin() println("main ended.") }output:
job is waiting 0 ... job is waiting 1 ... job cancel. kotlinx.coroutines.JobCancellationException: StandaloneCoroutine was cancelled; job="coroutine#2":StandaloneCoroutine{Cancelling}@4f6ee6e4 job finally. main ended. Process finished with exit code 0You can release resources in finally.
Using the use function, you can omit the manual release of resources. When you don't use use use, you have to deal with it yourself:@Test fun test_not_use() = runBlocking { val filePath = "" val br = BufferedReader(FileReader(filePath)) with(br) { var line: String? try { while (true) { line = readLine() ?: break println(line) } } catch (e: Exception) { println(e.toString()) } finally { close() } } }use without additional processing:
@Test fun test_use() = runBlocking { val path = "" BufferedReader(FileReader(path)).use { var line: String? while (true) { line = readLine()?:break println(line) } } }NonCancellable
NonCancellable can be used to handle operations that cannot be cancelled.
Look at this example
@Test
fun test_cancel_normal() = runBlocking {
val job = launch {
try {
repeat(100) { i ->
println("job is waiting $i...")
delay(1000)
}
} finally {
println("job finally...")
delay(1000)
println("job delayed 1 second as non cancellable...")
}
}
delay(1000)
job.cancelAndJoin()
println("main end...")
}output
job is waiting 0... job finally... main end... Process finished with exit code 0
If there are operations that cannot be cancelled in line 11 and line 12 in finally, this will not work. You can use NonCancellable:
@Test
fun test_non_cancellable() = runBlocking {
val job = launch {
try {
repeat(100) { i ->
println("job is waiting $i...")
delay(1000)
}
} finally {
withContext(NonCancellable) {
println("job finally...")
delay(1000)
println("job delayed 1 second as non cancellable...")
}
}
}
delay(1000)
job.cancelAndJoin()
println("main end...")
}output
job is waiting 0... job finally... job delayed 1 second as non cancellable... main end... Process finished with exit code 0
Timeout task
- In many cases, the reason to cancel a collaboration is that it may timeout
withTimeoutOrNull performs a timeout operation by returning null instead of throwing an exception
@Test fun test_timeout() = runBlocking { val job = withTimeout(1300) { repeat(5) { println("start job $it ...") delay(1000) println("end job $it ...") } } }output:
start job 0 ... end job 0 ... start job 1 ... kotlinx.coroutines.TimeoutCancellationException: Timed out waiting for 1300 ms
withTimeout, when more than 1300 milliseconds, the task will terminate, and then a TimeoutCancellationException will be thrown
@Test fun test_timeout_return_null() = runBlocking { val res = withTimeoutOrNull(1300) { repeat(5) { println("start job $it ...") delay(1000) println("end job $it ...") } "Done" } println("Result: $res") }output:
start job 0 ... end job 0 ... start job 1 ... Result: null Process finished with exit code 0
withTimeoutOrNull will return a result in the last line of the code block. After normal completion, it will return the modified result. If timeout, it will return null. Example:
@Test fun test_timeout_return_null() = runBlocking { val res = withTimeoutOrNull(1300) { try { repeat(5) { println("start job $it ...") delay(1000) println("end job $it ...") } "Done" } catch (e: Exception) { println(e.toString()) } } println("Result: $res") }output:
start job 0 ... end job 0 ... start job 1 ... kotlinx.coroutines.TimeoutCancellationException: Timed out waiting for 1300 ms Result: null Process finished with exit code 0
Exception handling of collaborative process
Context of collaboration
- Combining elements in context
- Inheritance of coroutine context
Exception handling of collaborative process
- Propagation characteristics of anomalies
- Exception capture
- Global exception handling
- Cancellation and exception
- Abnormal aggregation
What is the context of the collaboration
CoroutineContext is a set of elements used to define the behavior of a coroutine. It consists of the following items:
- Job: control the life cycle of the collaboration
- CoroutineDispatcher: distribute tasks to appropriate threads
- CoroutineName: the name of the collaboration process, which is very useful during debugging
CoroutineExceptionHandler: handle uncapped exceptions
Combining elements in context
Sometimes multiple elements need to be defined in the context of a collaboration, which can be implemented using the + operator. For example, you can specify a scheduler to start the process, and explicitly specify a name at the same time:
@Test fun test_coroutine_context() = runBlocking<Unit> { launch(Dispatchers.Default + CoroutineName("test")) { println("running on thread: ${Thread.currentThread().name}") } }output:
running on thread: DefaultDispatcher-worker-1 @test#2 Process finished with exit code 0
Inheritance of coroutine context
For the newly created collaboration, its CoroutineContext will contain a new Job instance, which will help us control the lifecycle of the collaboration. The remaining elements will inherit from the parent class of CoroutineContext, which may be another collaboration or the CoroutineScope that created the collaboration.
@Test fun test_coroutine_context_extend() = runBlocking<Unit> { // Create a collaboration scope val scope = CoroutineScope(Job() + Dispatchers.IO + CoroutineName("test")) println("${coroutineContext[Job]} , ${Thread.currentThread().name}") // Start a collaboration through the collaboration scope val job = scope.launch { println("${coroutineContext[Job]} , ${Thread.currentThread().name}") val result = async { println("${coroutineContext[Job]} , ${Thread.currentThread().name}") "Ok" }.await() println("result: $result") } job.join() }output:
"coroutine#1":BlockingCoroutine{Active}@2ddc8ecb , main @coroutine#1 "test#2":StandaloneCoroutine{Active}@5dd0b98f , DefaultDispatcher-worker-1 @test#2 "test#3":DeferredCoroutine{Active}@4398fdb7 , DefaultDispatcher-worker-3 @test#3 result: Ok Process finished with exit code 0runBlocking is the collaboration running in the main thread, job is the collaboration in the scope, and result is the collaboration in the job; Each layer of CoroutineContext will have a new job instance, BlockingCoroutine{Active}@2ddc8ecb, StandaloneCoroutine{Active}@5dd0b98f, DeferredCoroutine{Active}@4398fdb7; The remaining elements inherit from the parent class of CoroutineContext, such as the job under the scope, and inherit dispatchers from the parent scope IO and CoroutineName("test")
Context of coroutine = default value + inherited CoroutineContext + parameter
- Some elements contain default values: dispatchers Default is the default coroutine dispatcher, and "coroutine" is the default coroutine name;
- The inherited CoroutineContext is the CoroutineContext of CoroutineScope or its parent process;
The parameters passed into the collaboration builder take precedence over the inherited context parameters, so the corresponding parameter values are overwritten.
@Test fun test_coroutine_context_extend2() = runBlocking<Unit> { val coroutineExceptionHandler = CoroutineExceptionHandler { _, exception -> println("handle exception: $exception") } val scope = CoroutineScope(Job() + Dispatchers.Main + CoroutineName("test") + coroutineExceptionHandler) val job = scope.launch(Dispatchers.IO) { println("${coroutineContext[Job]} , ${Thread.currentThread().name}") 3/0 println("end of job...") } job.join() }output:
"test#2":StandaloneCoroutine{Active}@39e6aad4 , DefaultDispatcher-worker-2 @test#2 handle exception: java.lang.ArithmeticException: / by zero Process finished with exit code 0As can be seen from the above example, the constructor passes in the parameter dispatchers IO covers the original Main; The name comes from CoroutineName("test") in scope; The exception caused by the divide by 0 operation in the collaboration task is caught by the user-defined exceptionHandler.
Necessity of exception handling
When there are some unexpected situations in the application, it is very important to provide the user with an appropriate experience. On the one hand, the application crash is a very bad experience. In addition, the user must be able to give correct prompt information when the operation fails.
Abnormal propagation
There are two forms of Builders:
- Auto propagation exception (launch and actor)
Expose exceptions to users (async and produce)
When these constructors are used to create a root coprocessor (the coprocessor is not a child of another coprocessor), the exception of the former type of constructor will be thrown at the first time it occurs; The latter relies on users to end up consuming exceptions, such as via await or receive Take an example:@Test fun test_exception() = runBlocking<Unit> { val job = GlobalScope.launch { try { throw IllegalArgumentException("exception from job1") } catch (e: Exception) { println("Caught exception: $e") } } job.join() val job2 = GlobalScope.async { 1 / 0 } try { job2.await() } catch (e: Exception) { println("Caught exception: $e") } }launch is an automatic propagation exception, which is thrown the first time it occurs; async is used to expose exceptions to the user and rely on the user to consume exceptions. It is called through the await function. The output is as follows
Caught exception: java.lang.IllegalArgumentException: exception from job1 Caught exception: java.lang.ArithmeticException: / by zero Process finished with exit code 0
For async started coroutines, if the user does not handle them, no exceptions will be exposed. as follows
@Test fun test_exception() = runBlocking<Unit> { val job = GlobalScope.launch { try { throw IllegalArgumentException("exception from job1") } catch (e: Exception) { println("Caught exception: $e") } } job.join() val job2 = GlobalScope.async { println("job2 begin") 1 / 0 } delay(1000) // try { // job2.await() // } catch (e: Exception) { // println("Caught exception: $e") // } }output
Caught exception: java.lang.IllegalArgumentException: exception from job1 job2 begin Process finished with exit code 0
job2 executes, but does not throw an exception. User consumption exception is required.
Anomaly of non root coprocess
In the processes created by other processes, the exceptions generated will always be propagated.
@Test fun text_exception_2() = runBlocking<Unit> { val scope = CoroutineScope(Job()) val job = scope.launch { async { println("async started a coroutine...") 1/0 } } delay(100) }output:
async started a coroutine... Exception in thread "DefaultDispatcher-worker-2 @coroutine#3" java.lang.ArithmeticException: / by zero
Characteristics of anomaly propagation
When a coroutine fails due to an exception, it propagates the exception and passes it to its parent. Next, the parent will perform the following steps:
- Cancel its own children
- Cancel itself
Propagate the exception and pass it to its parent
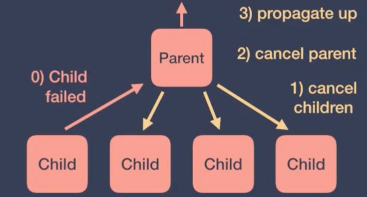
SupervisorJob
- When using SupervisorJob, the running failure of one sub process will not affect other sub processes. The SupervisorJob does not propagate exceptions to its parent. It lets the child process handle exceptions by itself.
This requirement is common in defining the UI component of a job in the scope. If the execution of any UI sub job fails, it is not always necessary to cancel the whole UI component. However, if the UI component is destroyed and its results are no longer needed, it is necessary to fail the execution of all sub jobs.
@Test fun text_supervisor_job1() = runBlocking<Unit> { val scope = CoroutineScope(SupervisorJob()) val job1 = scope.launch { println("child 1 start.") delay(1000) 1 / 0 } val job2 = scope.launch { println("child 2 start.") delay(5000) println("child 2 end.") } joinAll(job1, job2) }output
child 1 start. child 2 start. Exception in thread "DefaultDispatcher-worker-1 @coroutine#2" java.lang.ArithmeticException: / by zero ... child 2 end. Process finished with exit code 0
In the above example, the supervisor job is used to start two sub processes job1 and job2. Both jobs are executed. There is a division by zero operation in job1 and an exception is thrown, but job2 is not affected. However, if val scope = CoroutineScope(Job()), both sub processes will terminate
@Test fun text_supervisor_job2() = runBlocking<Unit> { val scope = CoroutineScope(Job()) val job1 = scope.launch { println("child 1 start.") delay(1000) 1 / 0 } val job2 = scope.launch { println("child 2 start.") delay(5000) println("child 2 end.") } joinAll(job1, job2) }result
child 1 start. child 2 start. Exception in thread "DefaultDispatcher-worker-1 @coroutine#2" java.lang.ArithmeticException: / by zero ... Process finished with exit code 0
supervisorScope
When the job itself fails to execute, all sub jobs will be cancelled.
@Test @Test fun text_supervisor_scope() = runBlocking<Unit> { try { supervisorScope { val job1 = launch { println("child 1 start.") delay(50) println("child 1 end.") } val job2 = launch { println("child 2 start.") delay(5000) println("child 2 end.") } println("in supervisor scope...") delay(1000) 1 / 0 } } catch (e: Exception) { println("caught exception: ${e.toString()}") } }output
in supervisor scope... child 1 start. child 2 start. child 1 end. caught exception: java.lang.ArithmeticException: / by zero Process finished with exit code 0
Directly use the supervisorScope to start the collaboration. The two subprocesses job1 and job2 are printed, delayed and divided by zero. You can see that the division by zero operation throws an exception. During this period, job1 delay time is short and the execution is completed, but job2 is not completed and is cancelled.
Exception capture
- Use CoroutineExceptionHandler to catch the exception of the coroutine
Exceptions are caught when the following conditions are met:
- Timing: the exception is thrown by the coroutine that automatically throws the exception (when using launch instead of async)
- Location: in the CoroutineContext of CoroutineScope or in a root process (the direct child process of CoroutineScope or supervisorScope).
@Test fun test_exception_handler() = runBlocking<Unit> { val handler = CoroutineExceptionHandler { _, exception -> println("caught exception: $exception") } val job = GlobalScope.launch(handler) { throw IllegalArgumentException("from job") } val deferred = GlobalScope.async(handler) { throw ArithmeticException("from deferred") } job.join() deferred.await() }output
caught exception: java.lang.IllegalArgumentException: from job java.lang.ArithmeticException: from deferred ... Process finished with exit code 255
It can be seen that the handler captures the launch started coroutine (auto throw), but does not capture the async started coroutine (non auto throw); And GlobalScope is a root process.
@Test fun test_exception_handler2() = runBlocking<Unit> { val handler = CoroutineExceptionHandler { _, exception -> println("caught exception: $exception") } val scope = CoroutineScope(Job()) val job1 = scope.launch(handler) { launch { throw IllegalArgumentException("from job1") } } job1.join() }output:
caught exception: java.lang.IllegalArgumentException: from job1 Process finished with exit code 0
In the above example, the handler is installed on the external process and can be captured. However, if it is installed on an internal process, it cannot be captured, as shown below
@Test fun test_exception_handler4() = runBlocking<Unit> { val handler = CoroutineExceptionHandler { _, exception -> println("caught exception: $exception") } val scope = CoroutineScope(Job()) val job1 = scope.launch { launch(handler) { throw IllegalArgumentException("from job1") } } job1.join() }output:
Exception in thread "DefaultDispatcher-worker-2 @coroutine#3" java.lang.IllegalArgumentException: from job1 ... Process finished with exit code 0
Global exception handling in Android
- Global exception handling can obtain all unhandled exceptions that are not handled by the collaboration, but it can not capture exceptions. Although it can not prevent program crash, the global exception handler is still very useful in scenarios such as program debugging and exception reporting.
You need to create the META-INF/services directory in the classpath and create a directory named kotlinx coroutines. Coroutineexceptionhandler file. The file content is the full class name of our global exception handler.
Take an example of an exception caught in android:override fun onCreate(savedInstanceState: Bundle?) { super.onCreate(savedInstanceState) binding = DataBindingUtil.setContentView(this, R.layout.activity_main) val handler = CoroutineExceptionHandler { _, e -> Log.d(TAG, "onCreate: caught exception: $e") } binding.btnFetch.setOnClickListener { lifecycleScope.launch(handler) { Log.d(TAG, "onCreate: on click") "abc".substring(10) } } }If the handler is not used, the application will crash; With handler, you can catch and handle exceptions to avoid application crash.
But what if it's not captured? There is another way to get the global exception information, which is the above-mentioned Android global exception handling.
As mentioned above, create the resource/META-INF/services / directory src/main in the project directory and create kotlinx coroutines. Coroutineexceptionhandler file.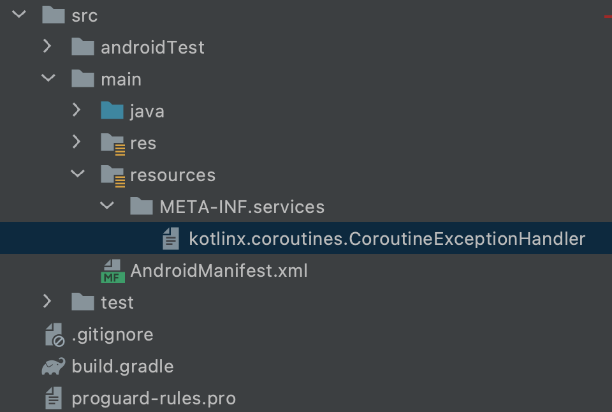
The file content is the full class name of the global exception handler. as follows
The global exception handling classes are as follows. When implementing the handleException method, implement logic such as printing and log collection according to your business needs.class GlobalCoroutineExceptionHandler: CoroutineExceptionHandler { override val key = CoroutineExceptionHandler override fun handleException(context: CoroutineContext, exception: Throwable) { Log.d("GlobalException", "Unhandled exception: $exception") } }In this way, exceptions that are not caught will be obtained in the modified method.
Cancellation and exception
- Cancelation is closely related to exceptions. Cancelationexception is used to cancel in the collaboration process, and the exception will be ignored.
- When a child collaboration is cancelled, its parent collaboration is not cancelled.
If a coroutine encounters an exception other than cancelationexception, it will use the exception to cancel its parent coroutine. When all the child processes of the parent process are completed, the exception will be handled by the parent process.
@Test fun test_cancel_and_exception1() = runBlocking<Unit> { val job = launch { println("parent started.") val child = launch { println("child started.") delay(10000) println("child ended.") } yield() child.cancelAndJoin() yield() println("parent is not cancelled.") } }output
parent started. child started. parent is not cancelled. Process finished with exit code 0
The program runs normally, the child ended does not print, and the child is cancelled.
There will be a jobcancelationexception. You can use try catch to capture. As follows:@Test fun test_cancel_and_exception2() = runBlocking<Unit> { val job = launch { println("parent started.") val child = launch { try { println("child started.") delay(10000) println("child ended.") } catch (e: Exception) { println("child exception: $e") } finally { println("child finally.") } } yield() child.cancelAndJoin() yield() println("parent is not cancelled.") } }output
parent started. child started. child exception: kotlinx.coroutines.JobCancellationException: StandaloneCoroutine was cancelled; job="coroutine#3":StandaloneCoroutine{Cancelling}@294425a7 child finally. parent is not cancelled. Process finished with exit code 0@Test fun test_cancel_and_exception3() = runBlocking<Unit> { val handler = CoroutineExceptionHandler { _, e -> println("handle the exception: $e") } val parent = GlobalScope.launch(handler) { val child1 = launch { try { println("child1 started.") delay(Long.MAX_VALUE) println("child1 ended.") } finally { withContext(NonCancellable) { println("child1 cancelled, but exception is not handled until all children are terminated") delay(100) println("child1 finished in the non cancellable block") } } } val child2 = launch { println("child2 started.") "abc".substring(10) delay(100) println("child2 ended.") } } parent.join() }output
child1 started. child2 started. child1 cancelled, but exception is not handled until all children are terminated child1 finished in the non cancellable block handle the exception: java.lang.StringIndexOutOfBoundsException: String index out of range: -7 Process finished with exit code 0
When all the child processes of the parent process are completed, the exception will be handled by the parent process.
Abnormal aggregation
When multiple sub processes of a process fail due to an exception, the first exception is generally taken for processing. All other exceptions that occur after the first exception are bound to the first exception.
@Test fun exception_aggregation() = runBlocking<Unit> { val handler = CoroutineExceptionHandler { _, e -> println("handle the exception: $e") println("the other exceptions: ${e.suppressedExceptions}") } val job = GlobalScope.launch(handler) { launch { try { delay(Long.MAX_VALUE) } finally { throw ArithmeticException("first exception") } } launch { try { delay(Long.MAX_VALUE) } finally { throw ArithmeticException("second exception") } } launch { "abc".substring(10) } } job.join() }output:
handle the exception: java.lang.StringIndexOutOfBoundsException: String index out of range: -7 the other exceptions: [java.lang.ArithmeticException: second exception, java.lang.ArithmeticException: first exception] Process finished with exit code 0
e.suppressedExceptions can be used in the exception handler to get other exceptions.
Study notes, tutorials from:
https://www.bilibili.com/vide...
Thank you~