Article directory
1, Introduction to Oozie framework
Definition of Oozie: tamer
An open source framework based on workflow engine, contributed by Cloudera to Apache, provides task scheduling and coordination for Hadoop Mapreduce and Pig Jobs. Oozie needs to be deployed to the Java Servlet container to run.
Write the scheduling process in the form of xml, which can schedule mr, pig, hive, shell, jar, etc.
2, Main functions of Oozie
Workflow: sequence execution process node, support fork (branch multiple nodes), join (merge multiple nodes into one)
Coordinator, to trigger workflow regularly (HUE4 renamed Schedule)
Bundle Job, binding multiple coordinator s (schedule)
Diagram:
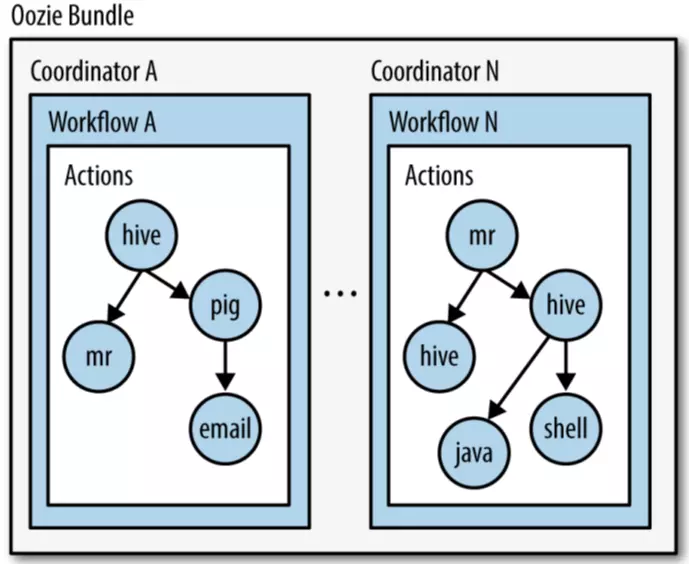
Oozie architecture:
Oozie node:
- Control Flow Nodes:
Control flow nodes are generally defined at the beginning or end of a workflow, such as start,end,kill, etc. And provide the execution path mechanism of workflow, such as decision,fork,join, etc.
- Action nodes:
In short, we can't simply say that it is mainly to perform some actions, such as FS ACTION, which can delete files on HDFS, create folders, etc.
- summary
If you don't understand the concept of oozie scheduling framework, you can first learn the examples in the state of incomprehension, and then review the knowledge points, then you will naturally understand.
3, Oozie internal analysis
Oozie is the workflow management system of Hadoop. As the paper "Oozie: towards a scalable workflow management system for Hadoop" said: workflow provides a declarative framework to effectively manage all kinds of jobs. There are four major requirements: scalability, multi tenant, Hadoop security, operability.
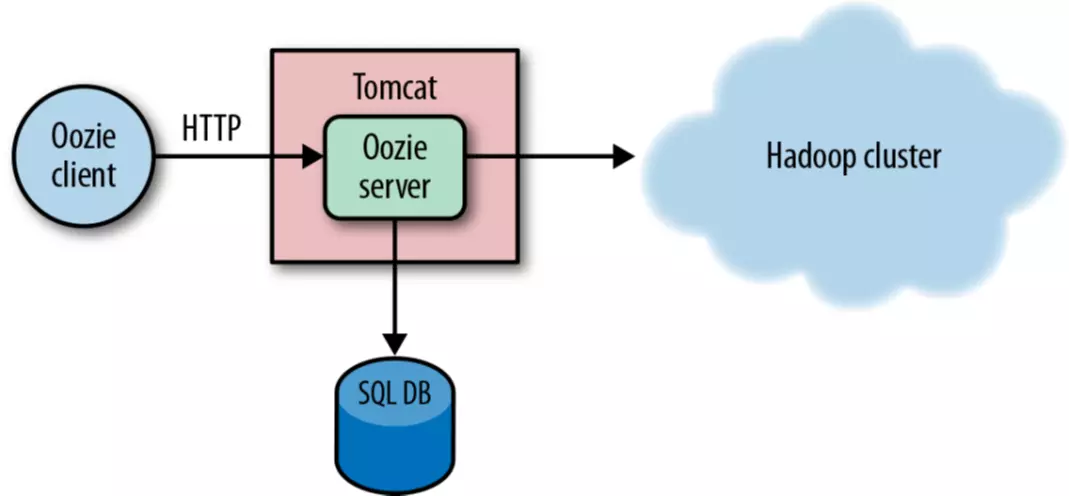
The architecture of Oozie is as follows:
Oozie provides a RESTful API interface to accept users' submit requests (submit workflow jobs). In fact, using oozie -job xxx command to submit jobs on the command line is essentially sending HTTP requests to submit jobs to OozieServer.
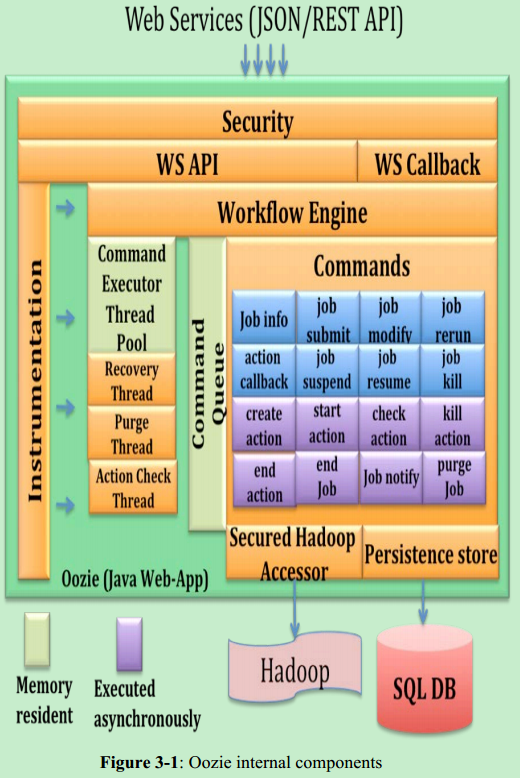
After the workflow submission to Oozie, workflow engine layer drives the execution and associated transitions. The workflow engine accomplishes these through a set of pre-defined internal sub-tasks called Commands.
When the workflow is submitted, the workflow engine is responsible for the workflow execution and state transition. For example, from one Action to the next, or the workflow status changes from Suspend to KILLED
Most of the commands are stored in an internal priority queue from where a pool of worker threads picks up and executes those commands. There are two types of commands: some are executed when the user submits the request and others are executed asynchronously.
There are two types of Commands, one is synchronous, the other is asynchronous.
Users deploy jobs (MR Jobs) on HDFS, and then submit workflow to oozie, who submits jobs (MR Jobs) to Hadoop asynchronously. This is also the reason why a jobId can be returned immediately after the job is submitted by calling the RESTful interface of oozie, and the user program does not have to wait for the job to be executed (because some large jobs may be executed for a long time (several hours or even days)). Oozie asynchronously submits the Action corresponding to workflow to Hadoop for execution in the background.
Oozie splits larger workflow management tasks (not Hadoop jobs) into smaller manageable subtasks and asynchronously processes them using a pre-defined state transition model.
In addition, Oozie provides an access layer to access the underlying cluster resources. This is one aspect of Hadoop Security.
Oozie provides a generic Hadoop access layer restricted through Kerberos authentication to access Hadoop's Job Tracker and Name Node components.
4, Horizontal and vertical scalability of Oozie
Horizontal scalability is reflected in the following aspects:
① The specific job execution context is not in Oozie Server process. This is mentioned in oozie's Action execution model. That is to say: Oozie Server is only responsible for executing workflow, while actions in workflow, such as MapReduce Action or Java Action, are executed in a cluster way. Oozie Server is only responsible for querying the execution status and results of these actions, thus reducing the load of Oozie Server.
Oozie needs to execute different types of jobs as part of workflow processing. If the jobs are executed in the context of the server process, there will be twoissues: 1) fewer jobs could run simultaneously due to limited resources in a server process causing significant penalty in scalability and 2) the user application could directly impact the Oozie server performance.
The operation of the actual job (MR Action or JAVA Action) is managed and executed by handing it to Hadoop. Oozie Server is only responsible for querying the status of the job If the number of workflow submitted by users increases, simply add Oozie Server.
② The status of the job is persisted in the relational database (zookeeper will be considered in the future). Because the status of the job (such as MR Action status) is stored in the database, rather than in the memory of a single machine, it is very scalable. In addition, as mentioned above, the actual job execution is performed by Hadoop.
Oozie stores the job states into a persistent store. This approach enables multiple Oozie servers to run simultaneously from different machines.
Vertical scalability is reflected in:
① Proper configuration and use of Commands in thread pool and queue.
② Asynchronous job submission model - reduce thread blocking
Oozie often uses a pre-defined timeout for any external communication. Oozie follows an asynchronous job execution pattern for interaction with external systems. For example, when a job is submitted to the Hadoop Job Tracker, Oozie does not wait for the job to finish since it may take a long time. Instead Oozie quickly returns the worker thread back to the thread pool and later checks for job completion in a separate interaction using a different thread.
③ Using the transaction model of the memory lock instead of the persistent model? – a bit confusing
In order to maximize resource usage, the persistent store connections are held for the shortest possible duration. To this end, we chose a memory lock based transaction model instead of a persistent store based one; the latter is often more expensive to hold for long time.
Finally, how does Oozie get the execution results of jobs from Hadoop cluster? - callback and polling combined
Callback is to reduce the cost, polling is to ensure reliability.
When Oozie starts a MapReduce job, it provides a unique callback URL as part of the MapReduce job configuration; the Hadoop Job Tracker invokes the given URL to notify the completion of the job. For cases where the Job Tracker failed to invoke the callback URL for any reason (i.e. a transient network failure), the system has a mechanism to poll the Job Tracker for determining the completion of the MapReduce job.
5, The Action execution model of Oozie
A fundamental design principle in Oozie is that the Oozie server never runs user code other than the execution of the workflow itself. This ensures better service stability byisolating user code away from Oozie's code. The Oozie server is also stateless and the launcher job makes it possible for it to stay that way. By leveraging Hadoop for running the launcher, handling job failures and recoverability becomes easier for the stateless Oozie server.
① Oozie never run user code other than the execution of the workflow itself.
② The Oozie server is also stateless and the launcher job...
The statelessness of oozie server is actually that it persists the execution information of jobs to the database.
The execution model of Action is as follows:
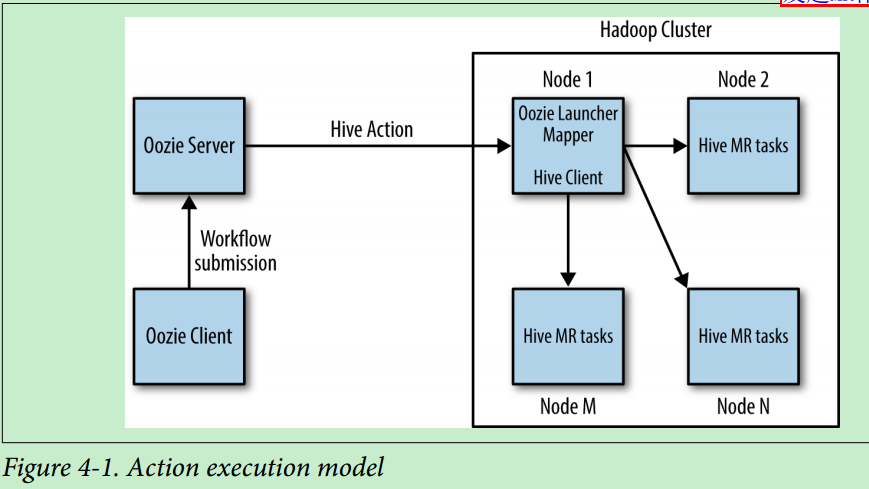
Oozie runs the actual actions through a launcher job, which itself is a Hadoop Map‐Reduce job that runs on the Hadoop cluster. The launcher is a map-only job that runs only one mapper.
Oozie runs a specific Action through the launcher job. The launcher job is a map only Mr job, and it is unknown which machine it will execute the MR job on in the cluster.
In the figure above, Oozie Client submits a workflow to Oozie Server. Specific Hive Action should be executed in this workflow
First, Oozie Server will start an MR job, that is, launcher job. The launcher job will initiate the specific Hive job. (Hive operation is essentially Mr operation)
We know that the launcher job is an MR job, which needs to occupy slots. That is to say, every time a workflow job is submitted, a launcher job will be created and occupy a slot. If the number of slots in the underlying Hadoop cluster is small, and there are many jobs submitted by Oozie, the launcher job will When the slot is used up, there is no slot available for the actual Action, which will lead to deadlock. Of course, you can prevent Oozie from initiating too many launcher jobs by configuring the relevant parameters of Oozie
In addition, for MR Action (Hive Action), the launcher job does not need to wait until the Action it initiates is completed before exiting. In fact, the launcher of MR Action does not wait for MR job to finish executing before exiting.
The <map-reduce>launcher is the exception and it exits right after launching the actual job instead of waiting for it to complete.
In addition, because of this "launcher job mechanism", when the job needs to be handed over to Oozie to manage and run, it is necessary to deploy the job related configuration files on HDFS, and then send a RESTful request to Oozie Server to submit the job.

