1. Theoretical knowledge
Feature points are composed of key points and descriptors. ORB feature points (Oriented FAST and Rotated BRIEF) are composed of Oriented FAST corner points and BRIEF (binary robot independent elemental features) descriptors. Its calculation speed is 100 times that of sift feature points and 10 times that of surf feature points.
1.1. Fast corner extraction
FAST is a kind of corner point, which mainly detects the places where the gray level of local pixels changes significantly. It is famous for its FAST speed. Its idea is that if a pixel is quite different from the pixels in its neighborhood (too bright or too dark), it is more likely to be a corner. Compared with other corner detection algorithms, FAST only needs to compare the brightness of pixels, which is very FAST.
Extraction steps:
- 1. Select pixel p in the image and assume that its brightness is Ip.
- 2. Set a threshold T (such as 20% of Ip).
- 3. Take pixel p as the center and select 16 pixels on the circle with radius 3.
- 4. If the brightness of N consecutive points on the selected circle is greater than Ip + T or less than Ip − T, pixel p can be considered as feature points (n usually takes 12, that is, FAST-12. Other commonly used n values are 9 and 11, which are called FAST-9 and fast-11 respectively).
- 5. Cycle the above four steps and perform the same operation for each pixel.
In order to improve efficiency, additional acceleration methods can be used. The specific operation is to directly detect the brightness of the 1st, 5th, 9th and 13th pixels on the neighborhood circle for each pixel. Only when the gray value of at least three and candidate points is greater than Ip + T or less than Ip − t at the same time, the current pixel may be a corner, otherwise it should be excluded directly. In order to improve the efficiency of comparison, only N peripheral pixels are usually used for comparison, which is often referred to as FAST-N, of which Fast-9 and Fast-12 are most used.

FAST corners do not have direction, but ORB improves FAST corners due to the need of feature point matching. The improved FAST is called Oriented FAST, which has the description of rotation and scale.
Scale invariance is realized by constructing image pyramid and detecting corners on each layer of pyramid, which is not specifically introduced in SLAM Lecture 14. Here is an introduction.
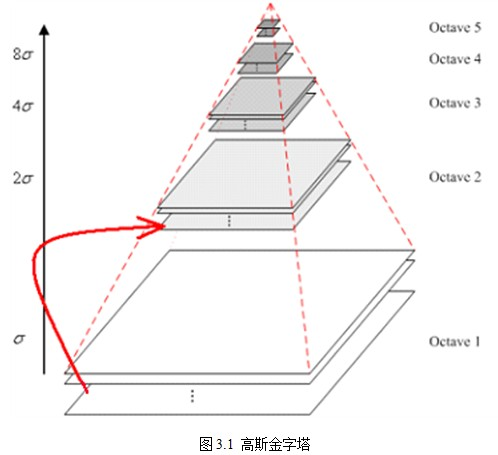
1.2. Gaussian pyramid construction
- Do Gaussian blur of different scales on the image
In order to make the scale reflect its continuity, Gaussian pyramid adds Gaussian filter on the basis of simple downsampling. One image of each layer of the image pyramid is Gaussian blurred with different parameters, so that each layer of the pyramid contains multiple Gaussian blurred images. The multiple images of each layer of the pyramid are collectively referred to as octave. Each layer of the pyramid has only one group of images. The number of groups and the number of layers of the pyramid are similar. The following formula is used to calculate that each group contains multiple (also known as layer Interval) images. In addition, during downsampling, the initial image (bottom image) of a group of images on the Gaussian pyramid is obtained by sampling every other point of the penultimate image of the previous group of images.
Where M and N are the size of the original image, and t is the logarithm of the minimum dimension of the tower top image. For example, for the image with the size of 512 * 512, the size of the image of each layer on the pyramid is shown in Table 3.1. When the image of the tower top is 4 * 4, n=7, and when the image of the tower top is 2 * 2, n=8.
- Downsampling the image (interval sampling)
1.3. summary
Set a scale factor (opencv defaults to 1.2) and the number of layers of the pyramid nlevers (pencv defaults to 8). Reduce the original image to nlevels images by scale factor. The scaled image is: I '= I/scaleFactork(k=1,2,..., nlevers). Nlevers extracts the sum of feature points from images with different proportions as the offast feature points of this image.
The rotation of features is realized by the Intensity Centroid method. The gray centroid method is introduced below.
1.4. Gray centroid method
- In a small image block B, the moment defining the image block is:
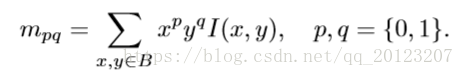
- The centroid of the image block can be found through the moment:
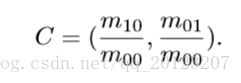
- Connect the geometric center O and the centroid C of the image block to obtain a direction vector \ vec{OC}, so the direction of the feature point can be defined as:
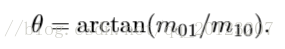
The above formula is extracted from Gao Xiang's visual SLAM14 lecture. But if you still don't understand the program, come to a more intuitive formula
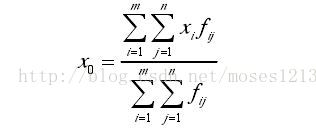
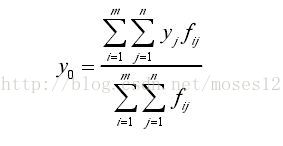

Where (UX) is the centroid of the picture, where (UX}, m {0,)_ {i} Represents the coordinates of line I, y_{j} Represents the coordinates of column J, and f(i,j) represents the pixel value of column J in row I.
2. ORB feature matching
After we extract the Fast corner, we need to describe it. Otherwise we can't match. ORB uses BREF algorithm to calculate the descriptor of a feature point. The core idea is to select N point pairs in a certain mode around the key point P, and combine the comparison results of these N point pairs as descriptors.
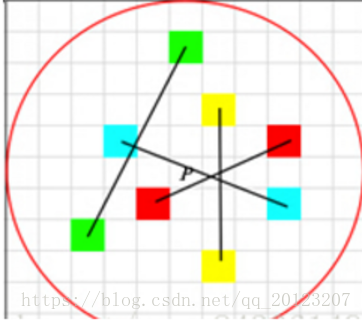
step
1. Make circle O with key point P as the center and d as the radius.
2. the first mock exam is to select N points in a O mode. For convenience, N=4. In practical application, n can be taken as 512
Suppose that the four currently selected point pairs are marked as follows:
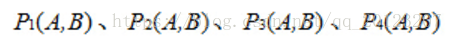
3. Define operation T
4. T-operate the selected point pairs respectively and combine the results.
If:
Then the final descriptor is 1011
The matching of ORB feature points uses Hamming distance. The Hamming distance between two equal length strings is the number of different characters in the corresponding positions of the two strings. In other words, it is the number of characters that need to be replaced to transform one string into another. For example, the Hamming distance between 1011101 and 1001 is 2. When the Hamming distance of two feature points is less than the set threshold, it can be considered as matching.
Compared with the extraction and matching of ORB features, SIFT is much more complex, but the effect of SIFT is better.
3. Code implementation
The ORB feature extracted from ORB-SLAM2 is determined by orbextracer CC implementation. Let's look at the main functions first.
static float IC_Angle(const Mat& image, Point2f pt, const vector<int> & u_max)
//To calculate the direction of feature points, we use the centroid method formula mentioned above
static void computeOrbDescriptor(const KeyPoint& kpt, const Mat& img, const Point *pattern,uchar* desc)calculation ORB descriptor
ORBextractor::ORBextractor(int _nfeatures, float _scaleFactor, int _nlevels,
int _iniThFAST, int _minThFAST)//Specific feature extraction, ORB
{
//Define scale size
mvScaleFactor.resize(nlevels);
mvLevelSigma2.resize(nlevels);
mvScaleFactor[0]=1.0f;
mvLevelSigma2[0]=1.0f;
for(int i=1; i<nlevels; i++)
{
mvScaleFactor[i]=mvScaleFactor[i-1]*scaleFactor;
mvLevelSigma2[i]=mvScaleFactor[i]*mvScaleFactor[i];
}
mvInvScaleFactor.resize(nlevels);
mvInvLevelSigma2.resize(nlevels);
//Calculate inverse scale size
for(int i=0; i<nlevels; i++)
{
mvInvScaleFactor[i]=1.0f/mvScaleFactor[i];
mvInvLevelSigma2[i]=1.0f/mvLevelSigma2[i];
}
mvImagePyramid.resize(nlevels);
mnFeaturesPerLevel.resize(nlevels);
float factor = 1.0f / scaleFactor;
//Number of feature points to be included in each layer
float nDesiredFeaturesPerScale = nfeatures*(1 - factor)/(1 - (float)pow((double)factor, (double)nlevels));
int sumFeatures = 0;
for( int level = 0; level < nlevels-1; level++ )
{
//The feature points contained in the upper layer are rounded
mnFeaturesPerLevel[level] = cvRound(nDesiredFeaturesPerScale);
//Total number of feature points
sumFeatures += mnFeaturesPerLevel[level];
//Number of feature points contained in the next layer
nDesiredFeaturesPerScale *= factor;
}
//The number of feature points required by the largest layer = the number of feature points required - the sum of feature points of all other layers
mnFeaturesPerLevel[nlevels-1] = std::max(nfeatures - sumFeatures, 0);
//Copy training template
const int npoints = 512;
const Point* pattern0 = (const Point*)bit_pattern_31_;
std::copy(pattern0, pattern0 + npoints, std::back_inserter(pattern));
//This is for orientation
// pre-compute the end of a row in a circular patch
// Define a vector to save the maximum coordinate u corresponding to each v
umax.resize(HALF_PATCH_SIZE + 1);
// The v coordinate is divided into two parts to ensure that the X and Y directions are symmetrical when calculating the main direction of the feature
int v, v0, vmax = cvFloor(HALF_PATCH_SIZE * sqrt(2.f) / 2 + 1);
int vmin = cvCeil(HALF_PATCH_SIZE * sqrt(2.f) / 2);
const double hp2 = HALF_PATCH_SIZE*HALF_PATCH_SIZE;
for (v = 0; v <= vmax; ++v)
umax[v] = cvRound(sqrt(hp2 - v * v)); //Pythagorean theorem
// Make sure we are symmetric
for (v = HALF_PATCH_SIZE, v0 = 0; v >= vmin; --v)
{
while (umax[v0] == umax[v0 + 1])
++v0;
umax[v] = v0;
++v0;
}
}
tatic void computeOrientation(const Mat& image, vector<KeyPoint>& keypoints, const vector<int>& umax)//Calculate the angle of each key
void ExtractorNode::DivideNode(ExtractorNode &n1, ExtractorNode &n2, ExtractorNode &n3, ExtractorNode &n4)//In many cases, the image is easy to focus on a certain part, and the corners of a large part of the area are very sparse. This is calculated
//In order to make the corner distribution more uniform and reasonable, we use the quadtree algorithm to redistribute the corner. Place image in
//The point is the far point, which is divided into four quadrants, and then check the feature points contained in each quadrant respectively. If the feature points are greater than 1,
//Continue to divide in this quadrant until the number of feature points is 1, so naturally there will be many leaves without feature points,
//Remove it directly, and then reassign the feature points
vector<cv::KeyPoint> ORBextractor::DistributeOctTree(const vector<cv::KeyPoint>& vToDistributeKeys, const int &minX,const int &maxX, const int &minY, const int &maxY, const int &N, const int &level)///Calculate whether the feature points selected by FAST are qualified
void ORBextractor::ComputeKeyPointsOctTree(vector<vector<KeyPoint> >& allKeypoints)Calculate the feature points of each layer of image in the image pyramid. The specific calculation process is to divide the image grid into small areas
//FAST corner detection is used independently in small areas
//After detection, use the DistributeOcTree function to filter all detected corners to make the corners evenly distributed
//Computational descriptor
static void computeDescriptors(const Mat& image, vector<KeyPoint>& keypoints, Mat& descriptors, const vector<Point>& pattern)//Computational descriptor
void ORBextractor::ComputePyramid(cv::Mat image)//Build pyramids. I'll write more about this
{
// Calculate pictures with n level scales
for (int level = 0; level < nlevels; ++level)
{
//Acquisition scale
float scale = mvInvScaleFactor[level];
//Get the size of the picture at the current scale. According to the pyramid model, the higher the number of layers, the larger the scale. Scale is the inverse scale factor
// Therefore, the higher the number of layers, the smaller the picture size
Size sz(cvRound((float)image.cols*scale), cvRound((float)image.rows*scale));
Size wholeSize(sz.width + EDGE_THRESHOLD*2, sz.height + EDGE_THRESHOLD*2);
Mat temp(wholeSize, image.type()), masktemp;
//Initialization of pictures
mvImagePyramid[level] = temp(Rect(EDGE_THRESHOLD, EDGE_THRESHOLD, sz.width, sz.height));
// Compute the resized image
if( level != 0 )
{
resize(mvImagePyramid[level-1], mvImagePyramid[level], sz, 0, 0, INTER_LINEAR);
// Add a width of edge around the image in a symmetrical manner_ The edge of threshold is convenient for later calculation
copyMakeBorder(mvImagePyramid[level], temp, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD,
BORDER_REFLECT_101+BORDER_ISOLATED);
}
else
{
//The first one is the resolution of the original image and does not need to be scaled
copyMakeBorder(image, temp, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD, EDGE_THRESHOLD,
BORDER_REFLECT_101);
}
}
}