Computer vision quick start learning notes
Great cause needs great theory to guide. Code without theory is a rogue
I Overview of artificial intelligence
-
Turing test: in 1950, Turing put forward the Turing test, that is, a person carries out a series of questions and answers with the other party in a special way without contacting the other party. If he cannot judge whether the other party is a person or a computer according to these questions for a long time, then the computer can be considered to have the same intelligence as a person, That is, this computer can think.
-
Machines that pass the Turing test are called "human intelligence". So far, no artificial intelligence equipment has passed the Turing test.
-
Dartmouth conference: 1956 is the first year of artificial intelligence.
-
Artificial intelligence: if machines and programs show abilities similar to human learning or other aspects, we can call them artificial intelligence.
II machine learning
-
Machine learning: automatically analyze and obtain the model from the data, and use the model to predict the unknown data. (data and features determine the upper limit of machine learning, while models and algorithms only approach this upper limit)
-
Machine learning workflow:
- 1. Obtain data
- 2. Basic data processing
- 3. Characteristic Engineering
- 4. Machine learning (model training)
- 5. Model evaluation
- The results meet the requirements and the online service is available
- If the requirements are not met, repeat the above steps
-
The relationship between machine learning and artificial intelligence: machine learning is a way to realize artificial intelligence.
III Fundamentals of iconography
-
RGB color model: also known as RGB color model or red, green and blue color model, it is an additive color model, which adds the color lights of the three primary colors of red, green and blue in different proportions to synthesize and produce various color lights.
- (the principle of three primary colors is not for physical reasons, but for physiological reasons.)
-
Computer display mode: 24 bit mode (8,8,8) - three 8-bit unsigned integers (0 to 255) are used to represent the intensity of red, green and blue. (for OpenCV, the order of three channels is BGR instead of RGB).
- Representation of pixels in computer: a linked list [0,0255]
- Representation of computer centerline: two-dimensional linked list array [[0,0255], [0,0255]]
- Face representation in computer: 3D linked list array[
[[0,0255], [0,0255]], / / red
[[255,0,0], [255,0,0]], / / blue
[[0255,0], [0255,0]], / / Green
]
-
Code for installing OpenCV Library: PIP install OpenCV python (if it is too slow, you can change the domestic image source, such as Douban, you can use the command - i https://pypi.douban.com/simple )
-
Code for importing OpenCV Library: import cv2
-
Representation of color pictures in computer: using a three-dimensional array or list can simply represent the color pictures in computer.
-
Representation of gray image in computer: a two-dimensional array can be used to represent gray image. The use of gray image can reduce dimension and facilitate rapid processing by computer.
IV Computer vision and Internet of things
- Computer vision is a simulation of biological vision using computers and related equipment. Its main task is to process the collected pictures or videos to obtain the three-dimensional information of the corresponding scene, just as humans and many other creatures do every day. Computer vision is a knowledge about how to use camera and computer to obtain the data and information of the subject we need. Figuratively speaking, it is to install eyes (camera) and brain (algorithm) on the computer so that the computer can perceive the environment.
- In short, computer vision is a science that studies how to make machines "see" and "understand". Its development has experienced a process from seeing and understanding to recognition and understanding.
- Internet of Things (IOT) refers to the real-time collection of any object or process that needs monitoring, connection and interaction through various devices and technologies such as information sensors, radio frequency identification technology, global positioning system, infrared sensors and laser scanners, and the collection of sound, light, heat, electricity, mechanics, chemistry, biology, location and other information, Through all kinds of possible network access, we can realize the ubiquitous connection between things and people, and realize the intelligent perception, identification and management of things and processes. The Internet of Things is an information carrier based on the Internet and traditional telecommunication networks. It allows all ordinary physical objects that can be independently addressed to form an interconnected network.
- With the development of Internet and chip technology, many devices can be equipped with chips and software systems, and then connected to the Internet. This is actually the so-called Internet of things, which is the concept of new bottled old wine.
V Face recognition case practice
1. Install the required package
- pip install cmake
- pip install scikit-image
- pip install dlib
- pip install face_recognition
If there are no red errors in the installation, just wait patiently. Generally, if your network is OK, the installation will succeed (there may be some errors in the installation of dlib. Solve it by Baidu. If there are no errors, wait more).
2. Steps of face recognition
- Locate the human face and frame the human face with a green frame;
- Read the names and facial features in the database;
- Matching the photographed facial features with the facial features in the database and identifying them with the user's name;
- Locate and lock the target task, and use a red box to frame the face of the target task.
3. Complete code with comments
# Overall task
# 1: Turn on the camera and read the picture taken by the camera
# Locate the face in the picture, frame it with a green box, and identify the name
# 2: Read the names and facial features in the database
# 3: The facial features captured by the camera are matched with the facial features in the database
# The user's name is marked on the green box of the user's Avatar, and Unknown users are uniformly used as Unknown
# 4: Locate and lock the target character, and frame the face of the target character with a red frame
import os
import cv2
import face_recognition
# 1. Preparation
face_dataset = 'dataset'
user_names = [] # Save user name
user_faces_encodings = [] # Save the user's facial feature vector (one-to-one correspondence with the name)
target_names = ['ZhangWei','zhangwei','Zhang Yida']
# 2. Formal work
# 2.1 get all the file names under the dataset folder
files = os.listdir('dataset')
# 2.2 read the file name circularly for further processing
for image_name in files:
# 2.2.1 intercept the file name and save it as user name_ In the list of names
user_name, _ = os.path.splitext(image_name)
user_names.append(user_name)
# 2.2.2 read the facial feature information in the picture file and store it in users_ faces_ In the encodings list
image_file_name = os.path.join(face_dataset, image_name)
image_file = face_recognition.load_image_file(image_file_name)
face_encoding = face_recognition.face_encodings(image_file)[0]
user_faces_encodings.append(face_encoding)
# 1. Open the camera and obtain the camera object
cap = cv2.VideoCapture(0) # 0 represents the first camera
cap.set(5,30)
# 2. Repeatedly obtain the pictures captured by the camera and make further processing
while True:
# 2.1 obtain the picture taken by the camera
ret, img = cap.read()
# 2.2 extract the area of human face from the captured picture (there may be multiple)
# 2.2.1 return the position of the recognized face (two diagonal points determine a rectangle)
# face_locations = ['area where the first face is located', 'area where the second face is located',...]
face_locations = face_recognition.face_locations(img)
# 2.2.2 extract facial features from the area where everyone's Avatar is located
# face_encodings = ['facial features of the first person', 'facial features of the second person',...]
face_encodings = face_recognition.face_encodings(img, face_locations)
# 2.2.3 define a list for storing the names of the photographed users, and traverse the list_ Encodings, match the facial features in the previous database
# names = ['first person's name', 'second person's name',...]
names = []
for face_encoding in face_encodings:
# compare_faces(['facial feature 1', 'facial feature 2',...], Unknown facial features) and returns an array. It is True where it matches and False where it doesn't match
matchs = face_recognition.compare_faces(user_faces_encodings, face_encoding)
name = 'Unknown'
for index, is_match in enumerate(matchs):
if is_match:
name = user_names[index]
break
names.append(name)
# 2.3 cycle through the area where the person's face is located, draw a frame (color BGR format, the last parameter is line thickness), and identify the person's name
# zip (['first person's location', 'second person's location',...], ['first person's name', 'second person's name',...], When traversing, it will be traversed one by one
for (top, right, bottom, left), name in zip(face_locations, names):
color = (0, 255, 0) # The default green box is marked with green
if name in target_names:
color = (0, 0, 255) # The red box of the target character is marked with red
cv2.rectangle(img, (left, top), (right, bottom), color, 2)
font = cv2.FONT_HERSHEY_DUPLEX
cv2.putText(img, name, (left, top-10), font, 0.5, color, 1)
# 2.4 display the captured and framed pictures through OpenCV
cv2.imshow("video_image", img)
# 2.5 setting: press the 'q' key (lowercase under English input method) to exit the cycle, and ord() returns the ASCII code of the corresponding character
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 3. When exiting the program, release the camera and close all windows
cap.release()
cv2.destroyAllWindows()
4. Final result demonstration
It can realize the real-time display of the camera. The more pictures in the database, the more features, and the more accurate the recognition results.

Vi Motion sensor case practice
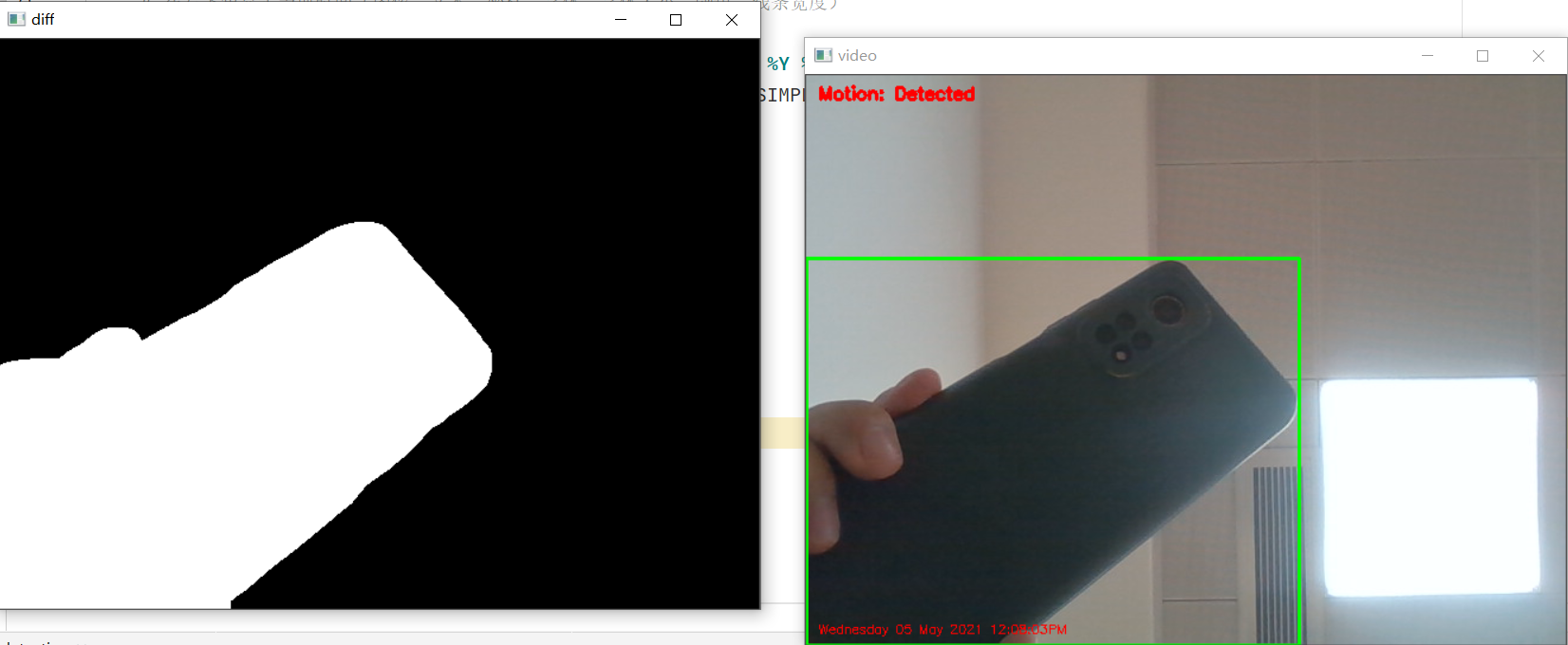
1. Use the difference method to detect moving objects
Principle of difference method:
Frame difference method is one of the most commonly used moving target detection and segmentation methods. The basic principle is to extract the moving region in the image by using pixel based time difference between two or three adjacent frames of the image sequence. Firstly, the corresponding pixel values of adjacent frame images are subtracted to obtain the difference image, and then the difference image is binarized. When the ambient brightness changes little, if the change of the corresponding pixel value is less than the predetermined threshold value, it can be considered as the background pixel; if the pixel value of the image area changes greatly, it can be considered that it is caused by the moving object in the image, These areas are marked as foreground pixels, and the position of the moving target in the image can be determined by using the marked pixel areas. Because the time between two adjacent frames is very short and the accumulation time between two adjacent frames is not very fast, and the algorithm has good real-time calculation. The disadvantage of the algorithm is that it is sensitive to environmental noise, and the selection of threshold is very key. If the selection is too low, it is not enough to suppress the noise in the image, and if it is too high, it ignores the useful changes in the image. For large moving targets with consistent color, there may be holes in the target, which can not extract the moving target completely. It only works when the camera is stationary.
2. Prepare wechat public platform test number and install HTTP library requests
-
(1) Visit wechat public platform website https://mp.weixin.qq.com
-
(2) Service number development document
-
(3) Start development - > interface test number application - > enter wechat public account test number application system
-
(4) Just scan the code and log in
-
(5) Install HTTP library requests: pip install requests
3. Write the code module of wechat sending notice
import json
import requests
class WxTools():
def __init__(self, myappid, myappsecret):
self.app_id = myappid
self.app_secret = myappsecret
# 1. Get access_token
# HTTPS request method: get https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid=APPID&secret=APPSECRET
def get_access_token(self):
url = f'https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid={self.app_id}&secret={self.app_secret}'
resp = requests.get(url).json()
access_token = resp.get('access_token')
return access_token
# 2. Use access_ Send wechat notification with token
# http request method: POST https://api.weixin.qq.com/cgi-bin/message/custom/send?access_token=ACCESS_TOKEN
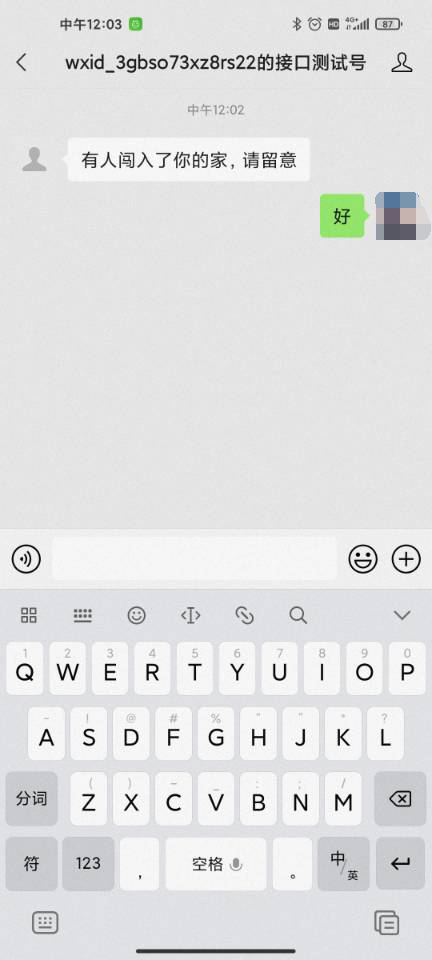
def send_wx_customer_msg(self, open_id, msg="Someone broke into your house"):
url = f'https://api.weixin.qq.com/cgi-bin/message/custom/send?access_token={self.get_access_token()}'
req_data = {
"touser": open_id,
"msgtype": "text",
"text":
{
"content": msg
}
}
requests.post(url, data=json.dumps(req_data, ensure_ascii=False).encode('utf-8'))
if __name__ == "__main__":
myAppId = 'wx810664b7b6822792' # Please change it to your own appID
myAppSecret = 'bda74affba1edb48bcc7b882fd2e4369' # Please change it to your own appsecret
myOpenID = 'o6h6p5xY9ZiPRH80GcgRzTIHXjk0' # Please change to your own openID
wx_tools = WxTools(myAppId, myAppSecret) # Instantiate the object and initialize
wx_tools.send_wx_customer_msg(myOpenID) # Call the function to send messages. If you want to send different messages, please add the content of the parameter msg
4. Write the code of motion detection
import cv2
import datetime
from wx_notice import WxTools
cap = cv2.VideoCapture(0)
background = None # Specify the background as the first picture to compare the difference method
es = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5, 4))
is_send_msg = False # Define a flag. When the notification has been sent, it will not continue to send the notification, that is, when a moving object is detected, it will only send the notification once
myAppId = 'wx810664b7b6822792' # Please change it to your own appID
myAppSecret = 'bda74affba1edb48bcc7b882fd2e4369' # Please change it to your own appsecret
myOpenID = 'o6h6p5xY9ZiPRH80GcgRzTIHXjk0' # Please change to your own openID
while True:
ret, img = cap.read()
# The image captured by the camera is converted into gray image, and Gaussian filter is used to eliminate the noise in the image
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray_img = cv2.GaussianBlur(gray_img, (25, 25), 3)
if background is None:
background = gray_img
continue
diff = cv2.absdiff(background, gray_img) # The difference between background image and gray image is calculated by difference method
diff = cv2.threshold(diff, 50, 255, cv2.THRESH_BINARY)[1] # Set the threshold value, i.e. 50. If the difference is less than 50, it is the same. 255 represents different parts, which are represented in white
# cv2.dilate(src, kernel, iteration)
# Parameter Description: src indicates the input picture, kernel indicates the size of the box, and iteration indicates the number of iterations
# Principle of expansion operation: there is a kernel to translate the image from left to right and from top to bottom. If there is white in the box, all colors in the box are white
diff = cv2.dilate(diff, es, iterations=3) # Do morphological expansion to enlarge the foreground object, that is, the small crack becomes smaller and looks more continuous
# cv2.findContours(image, mode, method, contours=None, hierarchy=None, offset=None)
# Image represents the input picture. Note that the input image must be a binary image. If the input picture is a color picture, grayscale and binarization must be carried out first.
# Mode refers to the retrieval mode of contour. There are four kinds:
# cv2.RETR_EXTERNAL means that only the outer contour is detected.
# cv2. RETR_ The contour detected by list does not establish a hierarchical relationship.
# cv2.RETR_CCOMP establishes two levels of contours. The upper layer is the outer boundary and the inner layer is the boundary information of the inner hole. If there is a connected object in the inner hole, the boundary of the object is also on the top layer.
# cv2.RETR_TREE establishes the outline of a hierarchical tree structure.
# Method is the approximate method of contour. There are four methods:
# cv2.CHAIN_APPROX_NONE stores all contour points. The pixel position difference between two adjacent points is no more than 1, that is, max (abs (x1 - x2), abs (y2 - y1)) < = 1.
# cv2.CHAIN_APPROX_SIMPLE compresses the elements in the horizontal, vertical and diagonal directions, and only retains the end coordinates of the direction. For example, a rectangular contour only needs 4 points to save the contour information.
# cv2.CHAIN_APPROX_TC89_L1 and CV2 CHAIN_ APPROX_ TC89_ KCOs uses teh - Chinlchain approximation algorithm.
# The function returns two values, one is the contour itself, and the other is the attribute hierarchy corresponding to each contour.
contours, hierarchy = cv2.findContours(diff.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
is_detected = False
for c in contours:
# Moving objects are considered detected only when the contour area is > 2000
if cv2.contourArea(c) < 2000:
continue
(x, y, w, h) = cv2.boundingRect(c)
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
is_detected = True
if not is_send_msg:
is_send_msg = True
wx_tools = WxTools(myAppId, myAppSecret)
wx_tools.send_wx_customer_msg(myOpenID, 'Someone broke into your home, please pay attention')
if is_detected:
show_text = "Motion: Detected"
show_color = (0, 0, 255) # Detected displays red and detected
else:
show_text = "Motion: Undetected"
show_color = (0, 255, 0) # Not detected displays green and not detected
# The current detection status (image, text, coordinates, font, font size, color, line width) is displayed in the upper left corner
cv2.putText(img, show_text, (10, 20),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, show_color, 2)
# The current time (image, text, coordinates, font, font size, color, line width) is displayed in the lower left corner
cv2.putText(img,
datetime.datetime.now().strftime("%A %d %B %Y %I:%M:%S%p"),
(10, img.shape[0] - 10), cv2.FONT_HERSHEY_SIMPLEX,
0.35, show_color, 1)
cv2.imshow('video', img)
cv2.imshow('diff', diff)
key = cv2.waitKey(1) & 0xFFf
if key == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
5. Operation effect demonstration
PC end:
Mobile terminal:
It should be noted that the background image of the detection is the photo collected by the camera at the beginning, so try to ensure that the first photo is not too bright or too dark, which will affect the subsequent detection.