
PASSL It includes image self-monitoring algorithms based on comparative learning such as SimCLR, MoCo v1/v2, BYOL, CLIP and PixPro
Open source is not easy. Welcome to a little Star support! 🥰

Hi Guy, let's meet again. This time, let's get a self supervised job, Masked Autoencoders (MAE)
This is another masterpiece of big brother he Kaiming. 2k star was opened in a few days. The CV circle basically knew that it was popular in the whole circle at that time

Others' work is how much they have improved. kaiming's work is best, best, best
Before interpreting MAE in detail, let's first understand the background of the development of visual self-monitoring. Before BEiT, visual self-monitoring has always been dominated by comparative learning, such as SimCLR, MoCo v3, etc. Comparative learning is simply to let the model learn an ability to distinguish between the same type and different types.
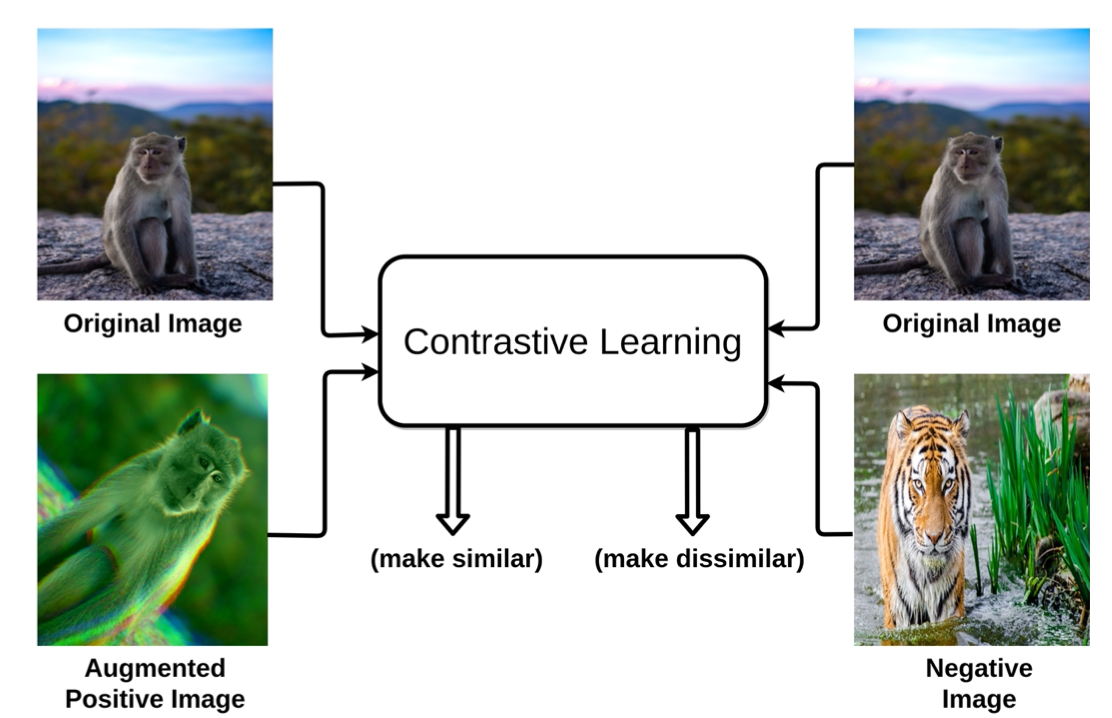
Draw closer to the same picture (Aug) and alienate different pictures
As shown in the above figure, we want the model to draw closer to the original image and the images passing through the Aug, and separate the images different from the original image at the same time. In this way, by drawing closer to the original image and the images after the Aug, we can alienate different images to achieve the effect of comparative learning, so that the model can learn to distinguish the same types of images by itself
Although comparative learning surpasses supervised methods on some benchmark s, its limitations are also obvious. It relies too much on data augmentation and inevitably falls into the contradiction between invariance and consistency. However, comparative learning does attack the previous self supervised methods (prediction, rotation, color jigsaw puzzle, etc.)
(PS: just think about it. Pictures of the same type are basically generated by aug, which is actually a limitation (the ability to generate images of the same type is limited), & & Achilles heel of comparative Learning & &)
kaiming's MoCo v3 is probably one of the best jobs in the post comparative learning era. During this period, Microsoft proposed BEiT to do self-monitoring through Masked Image, so as to replicate the success of Masked Language in NLP field. The results were indeed very successful. The Top-1 acc under ImageNet1k reached an amazing 88.6%. In this way, the wind direction of self-monitoring research began to favor generative self-monitoring
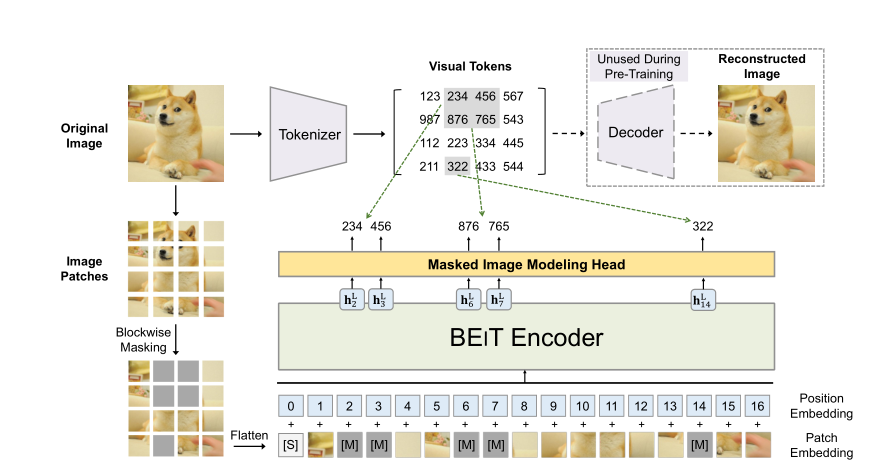
BEiT is a generative self-monitoring paradigm
Many excellent works have been produced based on BEiT. In addition to the MAE in this paper, there are generative self-monitoring algorithms such as PeCo, SimMIM and MaskedFeat
(ps, from the background, it is also because the development of visual Transformer drives the development of generative self-monitoring algorithm)
After the background is finished, let's take a look at MAE. In a word, MAE is simpler than BEiT. The avenue is simple. The viewpoint of the paper is very, very insight ful and solid
The flow chart of MAE is shown below
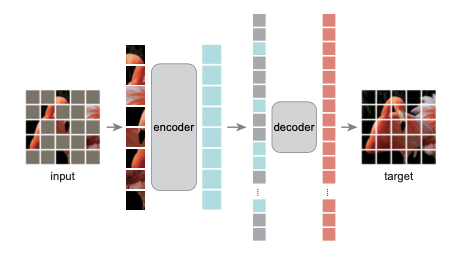
MAE from avenue to Jane
From left to right, patch the picture, then mask off a part, and the part that is not masked enters the encoder. The resulting output, together with the part of the previous mask, enters the decoder restored image. The goal is to restore the image as close as possible to the original image
More detailed things will be explained slowly when we build the model
In order to facilitate your understanding, PASL drew a flow chart to take you to realize a simple MAE
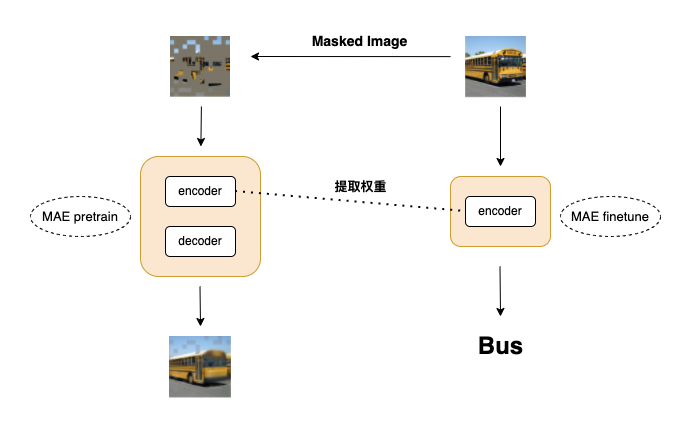
MAE flow chart 1
The original paper used the 8-machine 8-card running experiment under ImageNet1k. Here, we use Cifar10 as the MAE data set, so we can realize a simple MAE with only a single card V100-32g
First, build the model. As shown in the figure above, we first build the pretrain and finetune models, respectively
1. MAE finetune model
2. MAE pretrain model
🎯 FAQ: what are pretrain and finetune doing?
A: pretrain is used to let the model learn "resilience", that is, part of the original mask is removed and the model learns to restore it. In the process of learning and restoring, the model learns the internal representation of data. finetune is to extract the encoder weight after the pre train and use the learned weight to fine tune the down stream
🎯 FAQ: what is the difference between encoder and decoder?
A: in the pre train stage, encoder is mainly used to learn the internal representation of data, and decoder is mainly used to restore images. The encoder model is larger and the decoder model is smaller. They are the architecture of ViT
mae networking
# Build MAE pretrain model
# Because both encoder and decoder are the architecture of Vit, the modules required by vit need to be built first
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from functools import partial
# Weight initialization module
trunc_normal_ = nn.initializer.TruncatedNormal(std=0.02)
xavier_uniform_ = nn.initializer.XavierUniform()
zeros_ = nn.initializer.Constant(value=0.0)
ones_ = nn.initializer.Constant(value=1.0)
# DropPath module
def drop_path(x, drop_prob=0., training=False):
if drop_prob == 0. or not training:
return x
keep_prob = paddle.to_tensor(1 - drop_prob)
shape = (paddle.shape(x)[0], ) + (1, ) * (x.ndim - 1)
random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype)
random_tensor = paddle.floor(random_tensor)
output = x.divide(keep_prob) * random_tensor
return output
class DropPath(nn.Layer):
def __init__(self, drop_prob=None):
super().__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
# Identity module
class Identity(nn.Layer):
def __init__(self):
super().__init__()
def forward(self, x):
return x
# MLP module
class Mlp(nn.Layer):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.drop1 = nn.Dropout(drop)
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop2 = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop1(x)
x = self.fc2(x)
x = self.drop2(x)
return x
# Patch embedded module
# Used to divide images [B C H W] into patches [B L D]
class PatchEmbed(nn.Layer):
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768, norm_layer=None, flatten=True):
super().__init__()
img_size = (img_size, img_size)
patch_size = (patch_size, patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])
self.num_patches = self.grid_size[0] * self.grid_size[1]
self.flatten = flatten
self.proj = nn.Conv2D(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else Identity()
def forward(self, x):
B, C, H, W = x.shape
assert H == self.img_size[0], f"Input image height ({H}) doesn't match model ({self.img_size[0]})."
assert W == self.img_size[1], f"Input image width ({W}) doesn't match model ({self.img_size[1]})."
x = self.proj(x)
if self.flatten:
x = x.flatten(2).transpose([0,2,1]) # BCHW -> BLD
x = self.norm(x)
return x
# MHA (multi-head attention)
# ViT is used for global feature extraction
class Attention(nn.Layer):
def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape([B, N, 3, self.num_heads, C // self.num_heads]).transpose([2, 0, 3, 1, 4])
q, k, v = qkv.unbind(0)
attn = (q @ k.transpose([0, 1, 3, 2])) * self.scale
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose([0, 2, 1, 3]).reshape([B, N, C])
x = self.proj(x)
x = self.proj_drop(x)
return x
# Block module
# The combination of mlp and mha is the "basic unit" of vit architecture
class Block(nn.Layer):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
After the above basic modules are built, we can build pretrain and finetune models like Lego
Let's start with a finetune model
class MAE_FineTune(nn.Layer):
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dim=768, depth=12,
num_heads=12, mlp_ratio=4., qkv_bias=True,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., embed_layer=PatchEmbed, norm_layer=None,
act_layer=None):
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim
norm_layer = norm_layer or partial(nn.LayerNorm, epsilon=1e-6)
act_layer = act_layer or nn.GELU
self.patch_embed = embed_layer(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.cls_token = paddle.create_parameter(
shape=[1, 1, embed_dim],
dtype='float32',
default_initializer=trunc_normal_)
self.pos_embed = paddle.create_parameter(
shape=[1, num_patches + 1, embed_dim],
dtype='float32',
default_initializer=trunc_normal_)
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in paddle.linspace(0, drop_path_rate, depth)]
self.blocks = nn.Sequential(*[
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop_rate,
attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, act_layer=act_layer)
for i in range(depth)])
self.fc_norm = norm_layer(embed_dim)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight)
if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias)
elif isinstance(m, nn.LayerNorm):
zeros_(m.bias)
ones_(m.weight)
def forward_features(self, x):
B = x.shape[0]
x = self.patch_embed(x)
cls_tokens = self.cls_token.expand([B, -1, -1])
x = paddle.concat([cls_tokens, x], axis=1)
x = x + self.pos_embed
x = self.pos_drop(x)
for blk in self.blocks:
x = blk(x)
x = x[:, 1:, :].mean(axis=1)
outcome = self.fc_norm(x)
return outcome
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def mae_vit_b_p16(**kwargs):
model = MAE_FineTune(
embed_dim=768, depth=12, num_heads=12, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, epsilon=1e-6), **kwargs)
return model
if __name__ == '__main__':
# Test whether the model runs through
m = mae_vit_b_p16(img_size=32, patch_size=4, num_classes=10)
x = paddle.randn([2,3,32,32])
out = m(x)
print(out.shape) # output [2,10]
W0208 13:51:01.417953 2649 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0208 13:51:01.423804 2649 device_context.cc:465] device: 0, cuDNN Version: 7.6. [2, 10]
The MAE finetune model is the same as the ViT model, except for the subsequent processing part. ViT extracts CLS tokens for classification, while the MAE finetune model makes patches token s (except CLS tokens) mean and then classifies
Next, implement the pretrain model
import numpy as np
def get_1d_sincos_pos_embed_from_grid(embed_dim, pos):
"""
embed_dim: output dimension for each position
pos: a list of positions to be encoded: size (M,)
out: (M, D)
"""
assert embed_dim % 2 == 0
omega = np.arange(embed_dim // 2, dtype=np.float)
omega /= embed_dim / 2.
omega = 1. / 10000**omega # (D/2,)
pos = pos.reshape(-1) # (M,)
out = np.einsum('m,d->md', pos, omega) # (M, D/2), outer product
emb_sin = np.sin(out) # (M, D/2)
emb_cos = np.cos(out) # (M, D/2)
emb = np.concatenate([emb_sin, emb_cos], axis=1) # (M, D)
return emb
def get_2d_sincos_pos_embed_from_grid(embed_dim, grid):
assert embed_dim % 2 == 0
# use half of dimensions to encode grid_h
emb_h = get_1d_sincos_pos_embed_from_grid(embed_dim // 2,
grid[0]) # (H*W, D/2)
emb_w = get_1d_sincos_pos_embed_from_grid(embed_dim // 2,
grid[1]) # (H*W, D/2)
emb = np.concatenate([emb_h, emb_w], axis=1) # (H*W, D)
return emb
def get_2d_sincos_pos_embed(embed_dim, grid_size, cls_token=False):
"""
grid_size: int of the grid height and width
return:
pos_embed: [grid_size*grid_size, embed_dim] or [1+grid_size*grid_size, embed_dim] (w/ or w/o cls_token)
"""
grid_h = np.arange(grid_size, dtype=np.float32)
grid_w = np.arange(grid_size, dtype=np.float32)
grid = np.meshgrid(grid_w, grid_h) # here w goes first
grid = np.stack(grid, axis=0)
grid = grid.reshape([2, 1, grid_size, grid_size])
pos_embed = get_2d_sincos_pos_embed_from_grid(embed_dim, grid)
if cls_token:
pos_embed = np.concatenate([np.zeros([1, embed_dim]), pos_embed],
axis=0)
return pos_embed
class MAE_Pretrain(nn.Layer):
""" Masked Autoencoder with VisionTransformer backbone
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3,
embed_dim=1024, depth=24, num_heads=16,
decoder_embed_dim=512, decoder_depth=8, decoder_num_heads=16,
mlp_ratio=4., norm_layer=nn.LayerNorm, norm_pix_loss=False):
super().__init__()
# --------------------------------------------------------------------------
# MAE encoder specifics
self.patch_embed = PatchEmbed(img_size, patch_size, in_chans, embed_dim)
num_patches = self.patch_embed.num_patches
self.cls_token = paddle.create_parameter(
shape=[1, 1, embed_dim],
dtype='float32',
default_initializer=trunc_normal_)
self.pos_embed = paddle.create_parameter(
shape=[1, num_patches + 1, embed_dim],
dtype='float32',
default_initializer=trunc_normal_)
self.pos_embed.stop_gradient=True # fixed sin-cos embedding
self.blocks = nn.LayerList([
Block(embed_dim, num_heads, mlp_ratio, qkv_bias=True, norm_layer=norm_layer)
for i in range(depth)])
self.norm = norm_layer(embed_dim)
# --------------------------------------------------------------------------
# --------------------------------------------------------------------------
# MAE decoder specifics
self.decoder_embed = nn.Linear(embed_dim, decoder_embed_dim, bias_attr=True)
self.mask_token = paddle.create_parameter(
shape=[1, 1, decoder_embed_dim],
dtype='float32',
default_initializer=trunc_normal_)
self.decoder_pos_embed = paddle.create_parameter(
shape=[1, num_patches + 1, decoder_embed_dim],
dtype='float32',
default_initializer=trunc_normal_)
self.decoder_pos_embed.stop_gradient=True # fixed sin-cos embedding
self.decoder_blocks = nn.LayerList([
Block(decoder_embed_dim, decoder_num_heads, mlp_ratio, qkv_bias=True, norm_layer=norm_layer)
for i in range(decoder_depth)])
self.decoder_norm = norm_layer(decoder_embed_dim)
self.decoder_pred = nn.Linear(decoder_embed_dim, patch_size**2 * in_chans, bias_attr=True) # decoder to patch
# --------------------------------------------------------------------------
self.norm_pix_loss = norm_pix_loss
self.initialize_weights()
def initialize_weights(self):
# initialization
# initialize (and freeze) pos_embed by sin-cos embedding
pos_embed = get_2d_sincos_pos_embed(
self.pos_embed.shape[-1],
int(self.patch_embed.num_patches**.5),
cls_token=True)
self.pos_embed.set_value(
paddle.to_tensor(pos_embed).astype('float32').unsqueeze(0))
decoder_pos_embed = get_2d_sincos_pos_embed(
self.decoder_pos_embed.shape[-1],
int(self.patch_embed.num_patches**.5),
cls_token=True)
self.decoder_pos_embed.set_value(
paddle.to_tensor(decoder_pos_embed).astype('float32').unsqueeze(0))
# initialize patch_embed like nn.Linear (instead of nn.Conv2d)
w = self.patch_embed.proj.weight
xavier_uniform_(w.reshape([w.shape[0], -1]))
# initialize nn.Linear and nn.LayerNorm
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
# we use xavier_uniform following official JAX ViT:
xavier_uniform_(m.weight)
if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias)
elif isinstance(m, nn.LayerNorm):
zeros_(m.bias)
ones_(m.weight)
def patchify(self, imgs):
"""
imgs: (N, 3, H, W)
x: (N, L, patch_size**2 *3)
"""
p = self.patch_embed.patch_size[0]
assert imgs.shape[2] == imgs.shape[3] and imgs.shape[2] % p == 0
h = w = imgs.shape[2] // p
x = imgs.reshape([imgs.shape[0], 3, h, p, w, p])
x = paddle.einsum('nchpwq->nhwpqc', x)
x = x.reshape([imgs.shape[0], h * w, p**2 * 3])
return x
def unpatchify(self, x):
"""
x: (N, L, patch_size**2 *3)
imgs: (N, 3, H, W)
"""
p = self.patch_embed.patch_size[0]
h = w = int(x.shape[1]**.5)
assert h * w == x.shape[1]
x = x.reshape([x.shape[0], h, w, p, p, 3])
x = paddle.einsum('nhwpqc->nchpwq', x)
imgs = x.reshape([x.shape[0], 3, h * p, h * p])
return imgs
def random_masking(self, x, mask_ratio):
"""
Perform per-sample random masking by per-sample shuffling.
Per-sample shuffling is done by argsort random noise.
x: [N, L, D], sequence
"""
N, L, D = x.shape # batch, length, dim
len_keep = int(L * (1 - mask_ratio))
noise = paddle.rand([N, L]) # noise in [0, 1]
# sort noise for each sample
ids_shuffle = paddle.argsort(noise, axis=1) # ascend: small is keep, large is remove
ids_restore = paddle.argsort(ids_shuffle, axis=1)
# keep the first subset
ids_keep = ids_shuffle[:, :len_keep]
x_masked = x[paddle.arange(N)[:,None], ids_keep]
# generate the binary mask: 0 is keep, 1 is remove
mask = paddle.ones([N, L])
mask[:, :len_keep] = 0
# unshuffle to get the binary mask
mask = mask[paddle.arange(N)[:,None], ids_restore]
return x_masked, mask, ids_restore
def forward_encoder(self, x, mask_ratio):
# embed patches
x = self.patch_embed(x)
# add pos embed w/o cls token
x = x + self.pos_embed[:, 1:, :]
# masking: length -> length * mask_ratio
x, mask, ids_restore = self.random_masking(x, mask_ratio)
# append cls token
cls_token = self.cls_token + self.pos_embed[:, :1, :]
cls_tokens = cls_token.expand([x.shape[0], -1, -1])
x = paddle.concat([cls_tokens, x], axis=1)
# apply Transformer blocks
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
return x, mask, ids_restore
def forward_decoder(self, x, ids_restore):
# embed tokens
x = self.decoder_embed(x)
# append mask tokens to sequence
mask_tokens = self.mask_token.tile([x.shape[0], ids_restore.shape[1] + 1 - x.shape[1], 1])
x_ = paddle.concat([x[:, 1:, :], mask_tokens], axis=1) # no cls token
x_ = x_[paddle.arange(x.shape[0])[:,None], ids_restore] # unshuffle
x = paddle.concat([x[:, :1, :], x_], axis=1) # append cls token
# add pos embed
x = x + self.decoder_pos_embed
# apply Transformer blocks
for blk in self.decoder_blocks:
x = blk(x)
x = self.decoder_norm(x)
# predictor projection
x = self.decoder_pred(x)
# remove cls token
x = x[:, 1:, :]
return x
def forward_loss(self, imgs, pred, mask):
"""
imgs: [N, 3, H, W]
pred: [N, L, p*p*3]
mask: [N, L], 0 is keep, 1 is remove,
"""
target = self.patchify(imgs)
if self.norm_pix_loss:
mean = target.mean(axis=-1, keepdim=True)
var = target.var(axis=-1, keepdim=True)
target = (target - mean) / (var + 1.e-6)**.5
loss = (pred - target) ** 2
loss = loss.mean(axis=-1) # [N, L], mean loss per patch
loss = (loss * mask).sum() / mask.sum() # mean loss on removed patches
return loss
def forward(self, imgs, mask_ratio=0.75):
latent, mask, ids_restore = self.forward_encoder(imgs, mask_ratio)
pred = self.forward_decoder(latent, ids_restore) # [N, L, p*p*3]
loss = self.forward_loss(imgs, pred, mask)
return loss, pred, mask
# dec512d8b -> decoder: 512 dim, 8 blocks
def mae_vit_b_p16_dec512d8b(**kwargs):
model = MAE_Pretrain(
embed_dim=768, depth=12, num_heads=12,
decoder_embed_dim=512, decoder_depth=8, decoder_num_heads=16,
mlp_ratio=4, norm_layer=partial(nn.LayerNorm, epsilon=1e-6), **kwargs)
return model
if __name__ == '__main__':
m = mae_vit_b_p16_dec512d8b(img_size=32, patch_size=4)
x = paddle.randn([1,3,32,32])
loss,pred,mask = m(x, mask_ratio=0.75)
print('==> mae pretrain loss:', loss)
print('==> mae pretrain pred:', pred)
print('==> mae pretrain mask:', mask)
==> mae pretrain loss: Tensor(shape=[1], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[2.96917653])
==> mae pretrain pred: Tensor(shape=[1, 64, 48], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[[[ 0.83697253, -0.26026833, -0.98681760, ..., -1.29600096,
0.88749015, 0.42709437],
[ 0.77716583, -0.24290872, -0.96648449, ..., -1.12869048,
0.78012007, 0.38649371],
[ 0.75501764, -0.18518722, -0.97667748, ..., -1.02986050,
0.81335020, 0.30143970],
...,
[ 0.83380073, 0.77986282, -1.10319304, ..., 0.24139202,
0.51479208, -1.10088062],
[ 0.28179622, 0.62300211, -1.32151759, ..., -1.10423362,
1.41711402, -0.18977059],
[ 0.57918239, 0.73903900, -1.08218038, ..., 0.38149732,
0.35296690, -1.38562918]]])
==> mae pretrain mask: Tensor(shape=[1, 64], dtype=float32, place=CUDAPlace(0), stop_gradient=True,
[[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 1., 1., 1., 1., 0., 0., 1.,
1., 1., 1., 1., 0., 1., 1., 1., 1., 1., 1., 0., 0., 1., 1., 1., 1., 0.,
0., 0., 0., 1., 1., 1., 0., 1., 1., 0., 1., 1., 1., 1., 1., 1., 0., 1.,
1., 0., 1., 1., 1., 1., 1., 0., 1., 0.]])
mae pre training
Cifar10 dataset preparation
Now let's try the Cifar10 dataset with the built model
# PaddlePaddle has built-in Cifar10 data set.
from paddle.io import Dataset
from paddle.io import DataLoader
from paddle.vision import transforms as T
from paddle.vision import datasets
transforms = T.Compose([T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
def get_cifar10_dataset(mode='train'):
assert mode in ['train', 'val']
if mode == 'train':
dataset = datasets.Cifar10(mode='train', transform=transforms)
else:
dataset = datasets.Cifar10(mode='test', transform=transforms)
return dataset
def get_dataloader(dataset, mode='train', batch_size=16):
assert mode in ['train', 'val']
dataloader = DataLoader(dataset,
batch_size=batch_size,
num_workers=2,
shuffle=(mode == 'train'))
return dataloader
if __name__ == '__main__':
dataset_cifar10 = get_cifar10_dataset()
dataloader_cifar10 = get_dataloader(dataset_cifar10, batch_size=16) # Each batch has 16 images and corresponding labels
for imgs,labels in dataloader_cifar10:
print(imgs.shape)
print(labels.shape)
break
[16, 3, 32, 32] [16]
mae visualization tool preparation
The visualization of mae helps us to see the reconstruction ability of the model in pretrain and understand mae pretrain more intuitively
ps: if the picture is not displayed, run it again
import paddle
import matplotlib.pyplot as plt
import numpy as np
# Randomly select a picture from the dataset
def get_random_img(dataset):
total = len(dataset)
random = np.random.randint(total)
img,label = dataset[random]
return img, label
def image_show(img, title=''):
mean = paddle.to_tensor([0.485, 0.456, 0.406])
std = paddle.to_tensor([0.229, 0.224, 0.225])
img = paddle.clip((img * std + mean) * 255, 0, 255)
img = img.numpy().astype('int32')
plt.imshow(img)
plt.title(title, fontsize=16)
plt.axis('off')
def visualize(img, model, mask_ratio=0.75):
x = img.unsqueeze(0)
loss, pre, mask = model(x, mask_ratio=mask_ratio)
pre = model.unpatchify(pre)
pre = paddle.einsum('nchw->nhwc', pre)
mask = mask.unsqueeze(-1).tile([1, 1, model.patch_embed.patch_size[0]**2 *3])
mask = model.unpatchify(mask)
mask = paddle.einsum('nchw->nhwc', mask)
x = paddle.einsum('nchw->nhwc', x)
im_masked = x * (1 - mask)
im_paste = x * (1 - mask) + pre * mask
plt.figure(figsize=(12, 12))
plt.subplot(1, 3, 1)
image_show(x[0], "original")
plt.subplot(1, 3, 2)
image_show(im_masked[0], "masked "+ str(mask_ratio))
plt.subplot(1, 3, 3)
image_show(im_paste[0], "reconstruction")
plt.show()
if __name__ == '__main__':
img,label = get_random_img(dataset_cifar10)
pt_model = mae_vit_b_p16_dec512d8b(img_size=32, patch_size=4)
visualize(img, pt_model)
[the external link image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-j0kdndqu-164473653631) (output_16_0. PNG)]
Materials (cifar10 data set) and pot (mae model) are all alive. Start alchemy!!! 🔥🔥🔥
import paddle
import math
# warmup cosine decay
class WarmupCosineLR(paddle.optimizer.lr.LRScheduler):
def __init__(self,
learning_rate,
warmup_start_lr,
end_lr,
warmup_epochs,
total_epochs,
last_epoch=-1,
verbose=False):
self.warmup_epochs = warmup_epochs
self.total_epochs = total_epochs
self.warmup_start_lr = warmup_start_lr
self.end_lr = end_lr
super().__init__(learning_rate, last_epoch, verbose)
def get_lr(self):
# linear warmup
if self.last_epoch < self.warmup_epochs:
lr = (self.base_lr - self.warmup_start_lr) * float(self.last_epoch)/float(self.warmup_epochs) + self.warmup_start_lr
return lr
# cosine annealing decay
progress = float(self.last_epoch - self.warmup_epochs) / float(max(1, self.total_epochs - self.warmup_epochs))
cosine_lr = max(0.0, 0.5 * (1. + math.cos(math.pi * progress)))
lr = max(0.0, cosine_lr * (self.base_lr - self.end_lr) + self.end_lr)
return lr
# --> step 0: set hyper-parameter
BATCH_SIZE = 256
TOTAL_EPOCHS = 100
WARMUP_EPOCHS = 6
WARMUP_START_LR = 1e-6
BLR = 5e-5
END_LR = 1e-7
IMAGE_SIZE = 32
PATCH_SIZE = 4
MASK_RATIO = 0.75
WEIGHT_DECAY = 1e-4
# -->Step 1: prepare data
train_dataset = get_cifar10_dataset(mode='train')
train_dataloader = get_dataloader(train_dataset, mode='train', batch_size=BATCH_SIZE)
val_dataset = get_cifar10_dataset(mode='val')
# -->Step 2: prepare the model
pt_model = mae_vit_b_p16_dec512d8b(img_size=IMAGE_SIZE, patch_size=PATCH_SIZE)
# -->Step 3: set lr and opt
lr_schedule = WarmupCosineLR(learning_rate=BLR,
warmup_start_lr=WARMUP_START_LR,
end_lr=END_LR,
warmup_epochs=WARMUP_EPOCHS,
total_epochs=TOTAL_EPOCHS)
opt = paddle.optimizer.AdamW(learning_rate=lr_schedule,
beta1=0.9,
beta2=0.95,
parameters=pt_model.parameters(),
weight_decay=WEIGHT_DECAY)
# -->Step 4: start training
for epoch in range(1, TOTAL_EPOCHS+1):
pt_model.train()
print(f'===> [start train] epoch: {epoch}, lr: {opt.get_lr():.6f}')
for b_id,b_data in enumerate(train_dataloader):
imgs = b_data[0]
# labels = b_data[1] # mae pretrain is unsupervised and does not require labels
loss, _, _ = pt_model(imgs, mask_ratio=MASK_RATIO)
loss.backward()
opt.step()
opt.clear_grad()
if b_id % 25 == 0:
print(f"- batch_id: {b_id}, loss: {loss.item():.4f}")
lr_schedule.step()
print(' ')
# visualize
print(f'===> [get visualize] epoch: {epoch}')
img, label = get_random_img(val_dataset)
visualize(img, pt_model)
print(' ')
# step 5 save model
paddle.save(pt_model.state_dict(), "mae_pt_vit_b.pdparams")
Use the trained weights to test the reconstruction ability of mae pretrain model
# Weight trained ckpt_path = '/home/aistudio/mae_pt_vit_b.pdparams' model = mae_vit_b_p16_dec512d8b(img_size=32, patch_size=4) # Select one img at random dataset_cifar10 = get_cifar10_dataset() img, label = get_random_img(dataset_cifar10) # Weight not loaded visualize(img, model) # Load weight model.set_state_dict(paddle.load(ckpt_path)) visualize(img, model)
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-fxvoakpf-164473653632) (output_21_0. PNG)]
[the external link image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-6cokexpx-164473653633) (output_21_1. PNG)]
We can see that mae after pretrain can roughly restore the outline of the original image. Surprisingly, it only uses 25% of the pixels of the original image. As mae's paper said, "unlike language, image has high redundancy"
Let's test the effect of different mask ratio s
# Load weight ckpt_path = '/home/aistudio/mae_pt_vit_b.pdparams' model = mae_vit_b_p16_dec512d8b(img_size=32, patch_size=4) model.set_state_dict(paddle.load(ckpt_path)) # Select one img at random dataset_cifar10 = get_cifar10_dataset() img, label = get_random_img(dataset_cifar10) visualize(img, model, mask_ratio=0.25) visualize(img, model, mask_ratio=0.5) visualize(img, model, mask_ratio=0.75)
[the external link image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-euxqnsdj-164473653633) (output_23_0. PNG)]
[the external link image transfer fails, and the source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-oq4l34ev-164473653634) (output_23_1. PNG)]
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-ayw3dudm-164473653634) (output_23_2. PNG)]
As for the paper, why choose mask ratio 0.75?
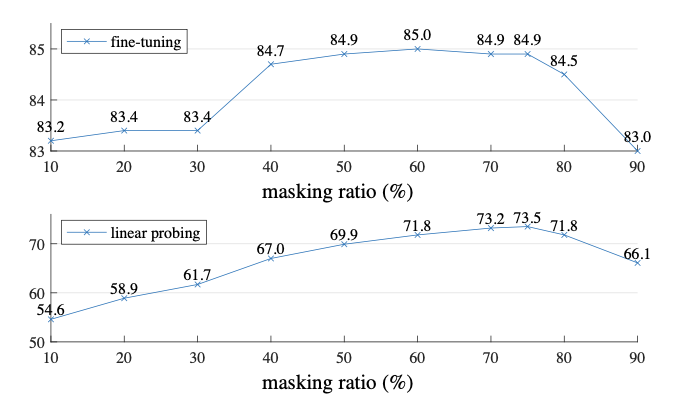
ratio=0.75, better performance
Whether it is to train the fine running of the whole model or freeze the weight and only fine tune the linear probing of the final classification header, the mask ratio is 0.75, which has achieved good performance
mae fine tuning
There are two kinds of mae fine tuning: one is to fine tune the whole model, and the loaded weights participate in the update; the other is linear prob. The loaded weights do not participate in the update, but only update the last classification header
Before fine tuning, extract the weight (encoder) obtained by mae pretrain and load it into mae finetune model
Here, we use cifar10 classification to make a simple fine tuning of finetune and train epoch to 10. Users can adjust parameters themselves to obtain better performance, or they can try linear prob
from collections import OrderedDict
import paddle
ckpt_path = '/home/aistudio/mae_pt_vit_b.pdparams'
ckpt = paddle.load(ckpt_path)
def extract_mae_pt(ckpt):
etr_ckpt = OrderedDict()
for i in ckpt:
if i in ['mask_token', 'decoder_pos_embed']:
continue
if i.startswith('decoder'):
break
etr_ckpt[i] = ckpt[i]
#print(f'keys {i} is extracted')
print('Done!')
return etr_ckpt
/aistudio/mae_pt_vit_b.pdparams'
ckpt = paddle.load(ckpt_path)
def extract_mae_pt(ckpt):
etr_ckpt = OrderedDict()
for i in ckpt:
if i in ['mask_token', 'decoder_pos_embed']:
continue
if i.startswith('decoder'):
break
etr_ckpt[i] = ckpt[i]
#print(f'keys {i} is extracted')
print('Done!')
return etr_ckpt
new_ckpt = extract_mae_pt(ckpt)
# Load the extracted encoder weights into the mae finetune model ft_model = mae_vit_b_p16(img_size=32, patch_size=4, num_classes=10) ft_model.set_state_dict(new_ckpt)
# --> step 0: set hyper-parameter
BATCH_SIZE = 64
TOTAL_EPOCHS = 10
WARMUP_EPOCHS = 3
WARMUP_START_LR = 1e-5
BLR = 5e-4
END_LR = 1e-6
MASK_RATIO = 0.75
WEIGHT_DECAY = 1e-4
# -->Step 1: prepare data
train_dataset = get_cifar10_dataset(mode='train')
train_dataloader = get_dataloader(train_dataset, mode='train', batch_size=BATCH_SIZE)
# -->Step 2: prepare the model
ft_model = ft_model
# -->Step 3: set lr and opt
lr_schedule = WarmupCosineLR(learning_rate=BLR,
warmup_start_lr=WARMUP_START_LR,
end_lr=END_LR,
warmup_epochs=WARMUP_EPOCHS,
total_epochs=TOTAL_EPOCHS)
opt = paddle.optimizer.AdamW(learning_rate=lr_schedule,
parameters=ft_model.parameters(),
weight_decay=WEIGHT_DECAY)
# -->Step 4: start training
loss_fn = paddle.nn.CrossEntropyLoss()
for epoch in range(1, TOTAL_EPOCHS+1):
ft_model.train()
print(f'===> [start train] epoch: {epoch}, lr: {opt.get_lr():.6f}')
for b_id,b_data in enumerate(train_dataloader):
imgs = b_data[0]
labels = b_data[1] # mae finetune is a supervisor and requires a label
pred = ft_model(imgs)
loss = loss_fn(pred, labels)
acc = paddle.metric.accuracy(pred, labels[:,None])
loss.backward()
opt.step()
opt.clear_grad()
if b_id % 100 == 0:
print(f"- batch_id: {b_id}, loss: {loss.item():.4f}, acc: {acc.item():.4f}")
lr_schedule.step()
print(' ')
# step 5 save model
paddle.save(pt_model.state_dict(), "mae_ft_vit_b.pdparams")