background
Recently, I was looking at the source code of sensors transformers and found a data loader in a module collate_ FN, I didn't understand what it meant at that time. Later, I checked it and found it very interesting, so let's share it.
dataloader
dataloader must know that it provides an iterator for data.
Basic working mechanism:
When the dataloader fetches data according to the batch, it takes out the index list whose size is equal to the batch size, then inputs the index in the list into the getitem() function of the dataset, takes out the data corresponding to the index, and finally stacks the data corresponding to each index to form a batch data.
Complete parameter list
The complete parameter table of DataLoader is as follows:
class torch.utils.data.DataLoader( dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=<function default_collate>, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None)
- shuffle: when set to True, each generation will disrupt the dataset.
- collate_fn: how to take samples, we can define our own functions to accurately realize the desired functions.
- drop_last: tells how to process the data set length divided by batch_size the remaining data. If True, discard it, otherwise keep it.
collate_fn action
There may be a problem in the last step of stacking: if the length of each data element contained in a piece of data is different, it will not be able to stack Such as multi hot data and sequence data. When using these data, it is usually necessary to supplement the length before stacking With the current process, there is no way to join the operation. In addition, some optimization methods are to operate on the data of a batch.
collate_ The FN function is a function that manually stacks the extracted samples.
Case description
import torch from torch.utils.data import DataLoader, TensorDataset import numpy as np test = np.arange(11) input = torch.tensor(np.array([test[i:(i + 3)] for i in range(10 - 1)])) target = torch.tensor(np.array([test[i:(i + 1)] for i in range(10 - 1)])) torch_dataset = TensorDataset(input, target) batch = 3 #> input data shape: torch.Size([9, 3]) #> target data shape: torch.Size([9, 1])
Note that the input data shape above is (9, 3); The target data shape is (9, 1). We set each batch to 3
1. Do not set collate_fn parameter
my_dataloader = DataLoader(
dataset=torch_dataset,
batch_size=batch
)
for (i, j) in my_dataloader:
print('*' * 30)
print(i)
print(j)
From the above results, you can see that each batch returns two results, one is the input sample and the other is the target sample.

The dimensions of input samples and target samples are consistent with the original, but all sizes are batch.
2. Set collate_fn parameter is lambda x: x
my_dataloader = DataLoader(
dataset=torch_dataset,
batch_size=4,
collate_fn=lambda x: x
)
for i in my_dataloader:
print('*' * 30)
print(i)
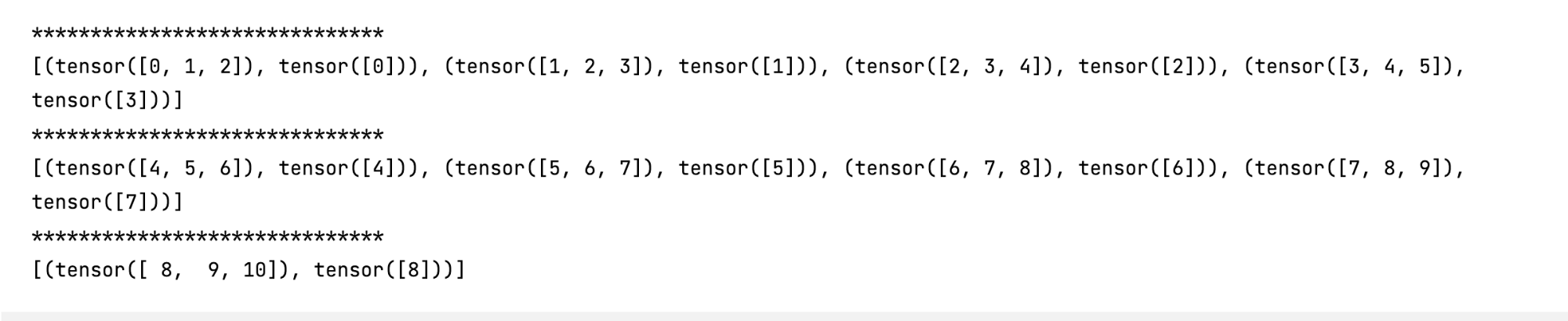
At this time, each batch returns a list. The size of the list is 3. Each object in the list is a pair of input and target.
If we continue to want to parse the above list into the first case, we can do this:
a = i list((torch.cat([a[i][j].unsqueeze(0) for i in range(len(a))]).unsqueeze(0) for j in range(len(a[0]))))
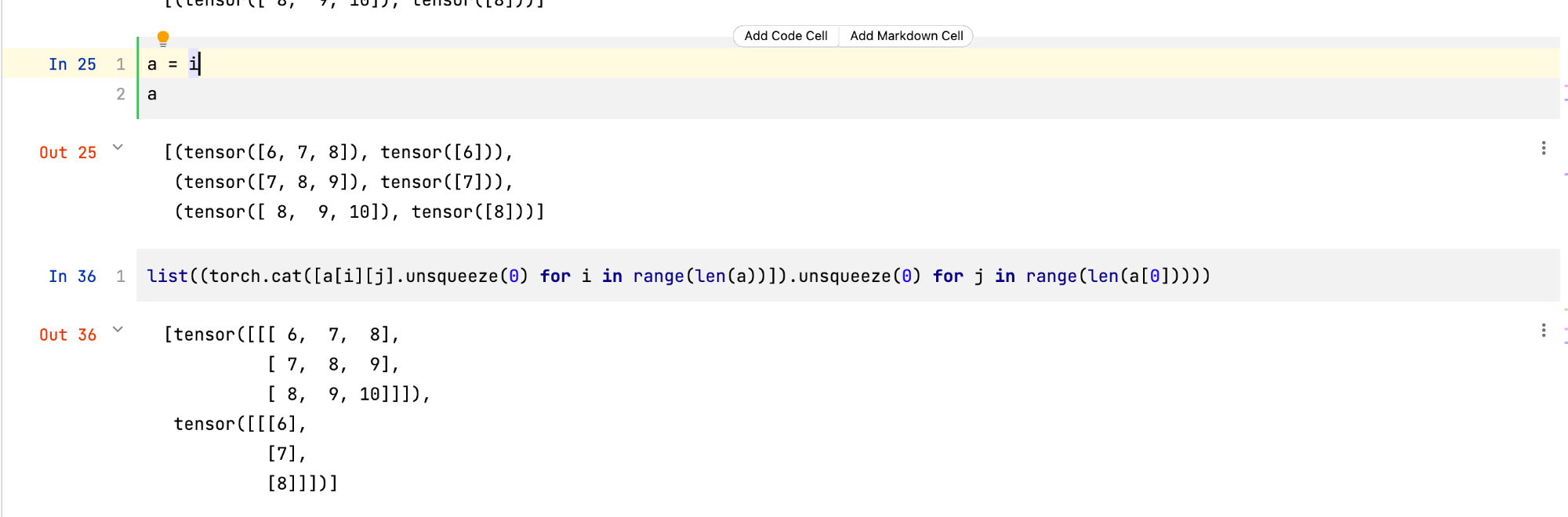
The above is actually very wow. What does it actually mean is to convert the output list with the length of batch into a matrix. It looks very complicated. In fact, it does data extraction and merging for the list. It's simple. There may be such a disassembly route:
my_dataloader = DataLoader(
dataset=torch_dataset,
batch_size=4,
collate_fn=lambda x: x,
drop_last=True
)
for i in my_dataloader:
print('*' * 30)
print(i)
a = i
a
Then, view the video:
3. Customize collate_fn parameter
Now, combined with the above steps, we can customize our own parameters, and then achieve the default effect. The approximate code is as follows:
my_dataloader = DataLoader(
dataset=torch_dataset,
batch_size=batch,
collate_fn=lambda x:(
torch.cat([x[i][j].unsqueeze(0) for i in range(len(x))],dim=0) for j in range(len(x[0]))
)
)
for i,j in my_dataloader:
print('*' * 30)
print(i)
print(j)

last
- Later, we will gradually talk about more popular things about Python and write more small details about python. It is mainly used to record their own learning process. Simplify some of the more complex things in the middle.
Reference link
- https://blog.csdn.net/weixin_42028364/article/details/81675021
- https://zhuanlan.zhihu.com/p/361830892
- https://github.com/pytorch/pytorch/blob/master/torch/utils/data/_utils/collate.py