Pytorch: Target Detection-Feature Pyramid-FPN
Copyright: Jingmin Wei, Pattern Recognition and Intelligent System, School of Artificial and Intelligence, Huazhong University of Science and Technology
This tutorial is not commercial and is only for learning and reference exchange. If you need to reproduce it, please contact me.
Reference
Pytorch Object Detection in Deep Learning
import torch.nn as nn import torch.nn.functional as F import torch
FPN Network Structure
To enhance semantics, traditional object detection models usually only perform subsequent operations on the last feature map of the deep convolution network, which usually has a larger downsampling rate (multiple of the image reduction), such as 16 , 32 16,32 16,32. As a result, small objects have less valid information on the feature map and their detection performance decreases dramatically, this problem is also known as multiscale problem.
The key to solving multiscale problems is how to extract multiscale features. The traditional method is Image Pyramid. The main idea is to make the input pictures into multiple scales, and the images of different scales generate different scales of features. This method is simple and effective, and has been used in many contests such as COCO. However, its drawback is time-consuming and computational.
From torch. As you can see from the chapter nn, the different layers of convolution neural network have different sizes and semantic information and are similar to a pyramid structure. 2017 2017 The 2017 FPN (Feature Pyramid Network) method combines the features of different layers and improves the multi-scale detection problem.
The overall architecture of FPN is shown in the figure, which mainly includes bottom-up network, top-down network, horizontal connection and convolution fusion. 4 4 Four parts.
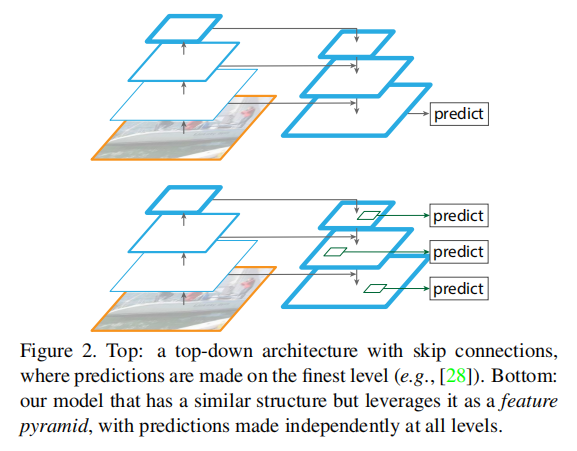
-
Bottom-up: The leftmost side is the normal convolution network, which uses the ResNet structure by default to extract semantic information. C 1 C_1 C1 represents the first convolution and pooling layers of ResNet, while C 2 − C 5 C_2-C_5 C2_C5 are different ResNet convolution groups, which contain multiple Bottleneck structures with the same size of feature maps and decreasing size between groups.
-
Top-down: First C 5 C_5 C5 1 × 1 1\times1 1 × 1 Convolution reduces the number of channels to get M 5 M_5 M5, then sequentially up-sampling M 4 , M 3 , M 2 M_4,M_3,M_2 M4, M3, M2, for the purpose of getting and C 4 , C 3 , C 2 C_4,C_3,C_2 C4, C3, C2 have the same characteristics in length and width to facilitate element-by-element addition in the next step. Use here 2 2 Twice nearest neighbor up sampling, i.e. direct replication of near elements, rather than linear interpolation.
-
Lateral Connection: The purpose is to fuse the high-semantic features sampled above with the shallow positioning detail features. When the high-semantic features are sampled up, they have the same length and width as the corresponding shallow features, while the number of channels is fixed to 256 256 256, so the underlying features need to be addressed C 2 − C 4 C_2-C_4 C2 C4 Conducted 1 × 1 1\times1 1 × 1 Convolution causes the number of channels to become 256 256 256, then add them element by element to get M 4 , M 3 , M 2 M_4,M_3,M_2 M4, M3, M2. Because C 1 C_1 C1's signature graph is large and has insufficient semantic information, so it is not C 1 C_1 C1 is placed in the horizontal connection.
-
Convolution Fusion: After deriving the added features, use 3 × 3 3\times3 3 × 3 Convolution pair generated M 2 − M 4 M_2-M_4 M2_M4 is fused again, M 5 M_5 M5 Do not process. The goal is to eliminate the overlap effect of the up-sampling process in order to generate the final feature map. P 2 − P 5 P_2-P_5 P2−P5 .
For the actual object detection algorithm, RoI(Region of Interests), which is the area of interest, needs to be extracted on the feature map. And FPN has 4 4 It is also a problem to choose which of the four output feature maps has the above feature. The solution given by FPN is to extract large-scale RoI from deep feature maps using different feature maps for different sizes of RoI, such as P 5 P_5 P5, small-scale RoI is extracted from shallow feature maps, such as P 2 P_2 P2, to determine the method, you can view the FPN paper by yourself.
FPN transmits the deep semantic information to the bottom to supplement the shallow semantic information, which obtains the high resolution and strong semantic features, and has a very good performance in small object detection, instance segmentation and other fields.
code implementation
First implement Residual Block:
# Define the Bottleneck class for ResNet
class Bottleneck(nn.Module):
expansion = 4 # Define a class property, not an instance property
def __init__(self, in_channels, channels, stride=1, downsample=None):
super(Bottleneck, self).__init__()
# A network stack layer consists of three convolutions + BN s
self.bottleneck = nn.Sequential(
nn.Conv2d(in_channels, channels, 1, stride=1, bias=False),
nn.BatchNorm2d(channels),
nn.ReLU(True),
nn.Conv2d(channels, channels, 3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(channels),
nn.ReLU(inplace=True),
nn.Conv2d(channels, channels*self.expansion, 1, stride=1, bias=False),
nn.BatchNorm2d(channels * self.expansion)
)
self.relu = nn.ReLU(inplace=True)
# Down sample consists of a 1*1 convolution containing BN
self.downsample = downsample
def forward(self, x):
identity = x
output = self.bottleneck(x)
if self.downsample is not None:
identity = self.downsample(x)
# Add identity (identity mapping) to stack layer output
output += identity
output = self.relu(output)
return output
Secondly, the residual blocks are used to build the FPN, which is unfamiliar. ResNet Tutorial.
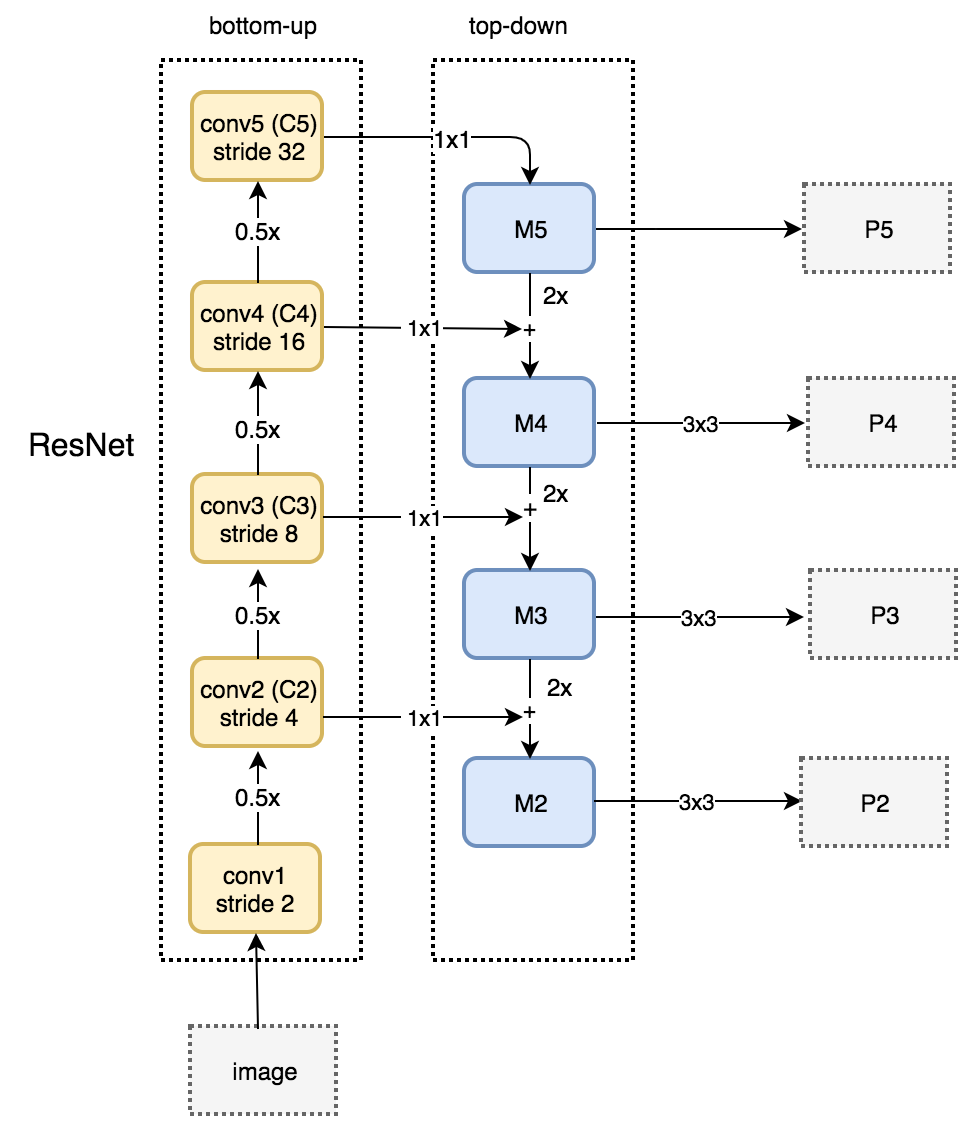
# Define FPN class, initialization requires a list representing the number of Bottleneck s per ResNet stage
class FPN(nn.Module):
def __init__(self, layers):
super(FPN, self).__init__()
self.in_channels = 64
# C1 module handling input
self.conv1 = nn.Conv2d(3, 64, 7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(3, stride=2, padding=1)
# Build bottom-up C2,C3,C4,C5
self.layer1 = self._make_layer(64, layers[0]) # stride=1
self.layer2 = self._make_layer(128, layers[1], 2) # stride=2
self.layer3 = self._make_layer(256, layers[2], 2) # stride=2
self.layer4 = self._make_layer(512, layers[3], 2) # stride=2
# Reduce the number of channels for C5 to get M5
self.toplayer = nn.Conv2d(2048, 256, 1, stride=1, padding=0)
# 3*3 Convolution Fusion Features
self.smooth1 = nn.Conv2d(256, 256, 3, 1, 1)
self.smooth2 = nn.Conv2d(256, 256, 3, 1, 1)
self.smooth3 = nn.Conv2d(256, 256, 3, 1, 1)
# Horizontal connection to ensure the same number of channels
self.latlayer1 = nn.Conv2d(1024, 256, 1, 1, 0)
self.latlayer2 = nn.Conv2d(512, 256, 1, 1, 0)
self.latlayer3 = nn.Conv2d(256, 256, 1, 1, 0)
# Define a protected method to build C2-C5
# Think like ResNet, pay attention to distinguishing stride=1/2
def _make_layer(self, channels, blocks, stride=1):
downsample = None
# Residual Block has an identity mapping when stride is 2
if stride != 1 or self.in_channels != Bottleneck.expansion * channels:
downsample = nn.Sequential(
nn.Conv2d(self.in_channels, Bottleneck.expansion*channels, 1, stride, bias=False),
nn.BatchNorm2d(Bottleneck.expansion*channels)
)
layers = []
layers.append(Bottleneck(self.in_channels, channels, stride, downsample))
self.in_channels = channels*Bottleneck.expansion
for i in range(1, blocks):
layers.append(Bottleneck(self.in_channels, channels))
return nn.Sequential(*layers)
# Top-down up sampling module
def _upsample_add(self, x, y):
_, _, H, W = y.shape
return F.interpolate(x, size=(H, W)) + y
def forward(self, x):
# Bottom-up
c1 = self.maxpool(self.relu(self.bn1(self.conv1(x))))
c2 = self.layer1(c1)
c3 = self.layer2(c2)
c4 = self.layer3(c3)
c5 = self.layer4(c4)
# Top-down
m5 = self.toplayer(c5)
m4 = self._upsample_add(m5, self.latlayer1(c4))
m3 = self._upsample_add(m4, self.latlayer2(c3))
m2 = self._upsample_add(m3, self.latlayer3(c2))
# Convolution Fusion, Smoothing
p5 = m5
p4 = self.smooth1(m4)
p3 = self.smooth2(m3)
p2 = self.smooth3(m2)
return p2, p3, p4, p5
def FPN50():
return FPN([3, 4, 6, 3]) # FPN50
def FPN101():
return FPN([3, 4, 23, 3]) # FPN101
def FPN152():
return FPN([3, 8, 36, 3]) # FPN152
# Define a FPN network net_fpn = FPN50() # FPN50
input = torch.randn(1, 3, 224, 224) output = net_fpn(input)
# Look at the sizes of the signature maps, which have the same number of channels and are decreasing in size print(output[0].shape) # p2 print(output[1].shape) # p3 print(output[2].shape) # p4 print(output[3].shape) # p5
torch.Size([1, 256, 56, 56]) torch.Size([1, 256, 28, 28]) torch.Size([1, 256, 14, 14]) torch.Size([1, 256, 7, 7])
from torchsummary import summary # D*W*H summary(net_fpn, input_size=(3, 224, 224), device='cpu')
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
Conv2d-5 [-1, 64, 56, 56] 4,096
BatchNorm2d-6 [-1, 64, 56, 56] 128
ReLU-7 [-1, 64, 56, 56] 0
Conv2d-8 [-1, 64, 56, 56] 36,864
BatchNorm2d-9 [-1, 64, 56, 56] 128
ReLU-10 [-1, 64, 56, 56] 0
Conv2d-11 [-1, 256, 56, 56] 16,384
BatchNorm2d-12 [-1, 256, 56, 56] 512
Conv2d-13 [-1, 256, 56, 56] 16,384
BatchNorm2d-14 [-1, 256, 56, 56] 512
ReLU-15 [-1, 256, 56, 56] 0
Bottleneck-16 [-1, 256, 56, 56] 0
Conv2d-17 [-1, 64, 56, 56] 16,384
BatchNorm2d-18 [-1, 64, 56, 56] 128
ReLU-19 [-1, 64, 56, 56] 0
Conv2d-20 [-1, 64, 56, 56] 36,864
BatchNorm2d-21 [-1, 64, 56, 56] 128
ReLU-22 [-1, 64, 56, 56] 0
Conv2d-23 [-1, 256, 56, 56] 16,384
BatchNorm2d-24 [-1, 256, 56, 56] 512
ReLU-25 [-1, 256, 56, 56] 0
Bottleneck-26 [-1, 256, 56, 56] 0
Conv2d-27 [-1, 64, 56, 56] 16,384
BatchNorm2d-28 [-1, 64, 56, 56] 128
ReLU-29 [-1, 64, 56, 56] 0
Conv2d-30 [-1, 64, 56, 56] 36,864
BatchNorm2d-31 [-1, 64, 56, 56] 128
ReLU-32 [-1, 64, 56, 56] 0
Conv2d-33 [-1, 256, 56, 56] 16,384
BatchNorm2d-34 [-1, 256, 56, 56] 512
ReLU-35 [-1, 256, 56, 56] 0
Bottleneck-36 [-1, 256, 56, 56] 0
Conv2d-37 [-1, 128, 56, 56] 32,768
BatchNorm2d-38 [-1, 128, 56, 56] 256
ReLU-39 [-1, 128, 56, 56] 0
Conv2d-40 [-1, 128, 28, 28] 147,456
BatchNorm2d-41 [-1, 128, 28, 28] 256
ReLU-42 [-1, 128, 28, 28] 0
Conv2d-43 [-1, 512, 28, 28] 65,536
BatchNorm2d-44 [-1, 512, 28, 28] 1,024
Conv2d-45 [-1, 512, 28, 28] 131,072
BatchNorm2d-46 [-1, 512, 28, 28] 1,024
ReLU-47 [-1, 512, 28, 28] 0
Bottleneck-48 [-1, 512, 28, 28] 0
Conv2d-49 [-1, 128, 28, 28] 65,536
BatchNorm2d-50 [-1, 128, 28, 28] 256
ReLU-51 [-1, 128, 28, 28] 0
Conv2d-52 [-1, 128, 28, 28] 147,456
BatchNorm2d-53 [-1, 128, 28, 28] 256
ReLU-54 [-1, 128, 28, 28] 0
Conv2d-55 [-1, 512, 28, 28] 65,536
BatchNorm2d-56 [-1, 512, 28, 28] 1,024
ReLU-57 [-1, 512, 28, 28] 0
Bottleneck-58 [-1, 512, 28, 28] 0
Conv2d-59 [-1, 128, 28, 28] 65,536
BatchNorm2d-60 [-1, 128, 28, 28] 256
ReLU-61 [-1, 128, 28, 28] 0
Conv2d-62 [-1, 128, 28, 28] 147,456
BatchNorm2d-63 [-1, 128, 28, 28] 256
ReLU-64 [-1, 128, 28, 28] 0
Conv2d-65 [-1, 512, 28, 28] 65,536
BatchNorm2d-66 [-1, 512, 28, 28] 1,024
ReLU-67 [-1, 512, 28, 28] 0
Bottleneck-68 [-1, 512, 28, 28] 0
Conv2d-69 [-1, 128, 28, 28] 65,536
BatchNorm2d-70 [-1, 128, 28, 28] 256
ReLU-71 [-1, 128, 28, 28] 0
Conv2d-72 [-1, 128, 28, 28] 147,456
BatchNorm2d-73 [-1, 128, 28, 28] 256
ReLU-74 [-1, 128, 28, 28] 0
Conv2d-75 [-1, 512, 28, 28] 65,536
BatchNorm2d-76 [-1, 512, 28, 28] 1,024
ReLU-77 [-1, 512, 28, 28] 0
Bottleneck-78 [-1, 512, 28, 28] 0
Conv2d-79 [-1, 256, 28, 28] 131,072
BatchNorm2d-80 [-1, 256, 28, 28] 512
ReLU-81 [-1, 256, 28, 28] 0
Conv2d-82 [-1, 256, 14, 14] 589,824
BatchNorm2d-83 [-1, 256, 14, 14] 512
ReLU-84 [-1, 256, 14, 14] 0
Conv2d-85 [-1, 1024, 14, 14] 262,144
BatchNorm2d-86 [-1, 1024, 14, 14] 2,048
Conv2d-87 [-1, 1024, 14, 14] 524,288
BatchNorm2d-88 [-1, 1024, 14, 14] 2,048
ReLU-89 [-1, 1024, 14, 14] 0
Bottleneck-90 [-1, 1024, 14, 14] 0
Conv2d-91 [-1, 256, 14, 14] 262,144
BatchNorm2d-92 [-1, 256, 14, 14] 512
ReLU-93 [-1, 256, 14, 14] 0
Conv2d-94 [-1, 256, 14, 14] 589,824
BatchNorm2d-95 [-1, 256, 14, 14] 512
ReLU-96 [-1, 256, 14, 14] 0
Conv2d-97 [-1, 1024, 14, 14] 262,144
BatchNorm2d-98 [-1, 1024, 14, 14] 2,048
ReLU-99 [-1, 1024, 14, 14] 0
Bottleneck-100 [-1, 1024, 14, 14] 0
Conv2d-101 [-1, 256, 14, 14] 262,144
BatchNorm2d-102 [-1, 256, 14, 14] 512
ReLU-103 [-1, 256, 14, 14] 0
Conv2d-104 [-1, 256, 14, 14] 589,824
BatchNorm2d-105 [-1, 256, 14, 14] 512
ReLU-106 [-1, 256, 14, 14] 0
Conv2d-107 [-1, 1024, 14, 14] 262,144
BatchNorm2d-108 [-1, 1024, 14, 14] 2,048
ReLU-109 [-1, 1024, 14, 14] 0
Bottleneck-110 [-1, 1024, 14, 14] 0
Conv2d-111 [-1, 256, 14, 14] 262,144
BatchNorm2d-112 [-1, 256, 14, 14] 512
ReLU-113 [-1, 256, 14, 14] 0
Conv2d-114 [-1, 256, 14, 14] 589,824
BatchNorm2d-115 [-1, 256, 14, 14] 512
ReLU-116 [-1, 256, 14, 14] 0
Conv2d-117 [-1, 1024, 14, 14] 262,144
BatchNorm2d-118 [-1, 1024, 14, 14] 2,048
ReLU-119 [-1, 1024, 14, 14] 0
Bottleneck-120 [-1, 1024, 14, 14] 0
Conv2d-121 [-1, 256, 14, 14] 262,144
BatchNorm2d-122 [-1, 256, 14, 14] 512
ReLU-123 [-1, 256, 14, 14] 0
Conv2d-124 [-1, 256, 14, 14] 589,824
BatchNorm2d-125 [-1, 256, 14, 14] 512
ReLU-126 [-1, 256, 14, 14] 0
Conv2d-127 [-1, 1024, 14, 14] 262,144
BatchNorm2d-128 [-1, 1024, 14, 14] 2,048
ReLU-129 [-1, 1024, 14, 14] 0
Bottleneck-130 [-1, 1024, 14, 14] 0
Conv2d-131 [-1, 256, 14, 14] 262,144
BatchNorm2d-132 [-1, 256, 14, 14] 512
ReLU-133 [-1, 256, 14, 14] 0
Conv2d-134 [-1, 256, 14, 14] 589,824
BatchNorm2d-135 [-1, 256, 14, 14] 512
ReLU-136 [-1, 256, 14, 14] 0
Conv2d-137 [-1, 1024, 14, 14] 262,144
BatchNorm2d-138 [-1, 1024, 14, 14] 2,048
ReLU-139 [-1, 1024, 14, 14] 0
Bottleneck-140 [-1, 1024, 14, 14] 0
Conv2d-141 [-1, 512, 14, 14] 524,288
BatchNorm2d-142 [-1, 512, 14, 14] 1,024
ReLU-143 [-1, 512, 14, 14] 0
Conv2d-144 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-145 [-1, 512, 7, 7] 1,024
ReLU-146 [-1, 512, 7, 7] 0
Conv2d-147 [-1, 2048, 7, 7] 1,048,576
BatchNorm2d-148 [-1, 2048, 7, 7] 4,096
Conv2d-149 [-1, 2048, 7, 7] 2,097,152
BatchNorm2d-150 [-1, 2048, 7, 7] 4,096
ReLU-151 [-1, 2048, 7, 7] 0
Bottleneck-152 [-1, 2048, 7, 7] 0
Conv2d-153 [-1, 512, 7, 7] 1,048,576
BatchNorm2d-154 [-1, 512, 7, 7] 1,024
ReLU-155 [-1, 512, 7, 7] 0
Conv2d-156 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-157 [-1, 512, 7, 7] 1,024
ReLU-158 [-1, 512, 7, 7] 0
Conv2d-159 [-1, 2048, 7, 7] 1,048,576
BatchNorm2d-160 [-1, 2048, 7, 7] 4,096
ReLU-161 [-1, 2048, 7, 7] 0
Bottleneck-162 [-1, 2048, 7, 7] 0
Conv2d-163 [-1, 512, 7, 7] 1,048,576
BatchNorm2d-164 [-1, 512, 7, 7] 1,024
ReLU-165 [-1, 512, 7, 7] 0
Conv2d-166 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-167 [-1, 512, 7, 7] 1,024
ReLU-168 [-1, 512, 7, 7] 0
Conv2d-169 [-1, 2048, 7, 7] 1,048,576
BatchNorm2d-170 [-1, 2048, 7, 7] 4,096
ReLU-171 [-1, 2048, 7, 7] 0
Bottleneck-172 [-1, 2048, 7, 7] 0
Conv2d-173 [-1, 256, 7, 7] 524,544
Conv2d-174 [-1, 256, 14, 14] 262,400
Conv2d-175 [-1, 256, 28, 28] 131,328
Conv2d-176 [-1, 256, 56, 56] 65,792
Conv2d-177 [-1, 256, 14, 14] 590,080
Conv2d-178 [-1, 256, 28, 28] 590,080
Conv2d-179 [-1, 256, 56, 56] 590,080
================================================================
Total params: 26,262,336
Trainable params: 26,262,336
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 302.71
Params size (MB): 100.18
Estimated Total Size (MB): 403.47
----------------------------------------------------------------
# View the first layer of the FPN, C2 net_fpn.layer1
Sequential(
(0): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(relu): ReLU(inplace=True)
)
)
# Look at the second layer of the FPN, C3, which contains four Bottleneck s net_fpn.layer2
Sequential(
(0): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(relu): ReLU(inplace=True)
)
)