prerequisite:
Install Hadoop 2 7.3 (under Linux system)
Install MySQL (under Windows or Linux system)
Install Hive (under Linux system) reference: Hive installation configuration
Title:
Download search data from Sogou lab for analysis
The downloaded data contains 6 fields, and the data format is described as follows:
Access time user ID [query term] the ranking of the URL in the return result, the sequence number clicked by the user, and the URL clicked by the user
be careful:
1. Field separator: field separators are spaces with different numbers;
2. Number of fields: some lines have 6 fields, and some have less than 6 fields.
Question: use MapReduce and Hive to query the data ranked No. 2 in search results and No. 1 in click order?
Experimental steps:
Idea: use MapReduce for data cleaning and Hive for data analysis.
1. Download data source
Open Sogou lab link
http://www.sogou.com/labs/resource/q.php
Download the compact version (one day data, 63mb) tar GZ format data

The downloaded files are as follows:

2. Upload and download files to HDFS
2.1 upload the downloaded files to the Linux system through the Xshell tool
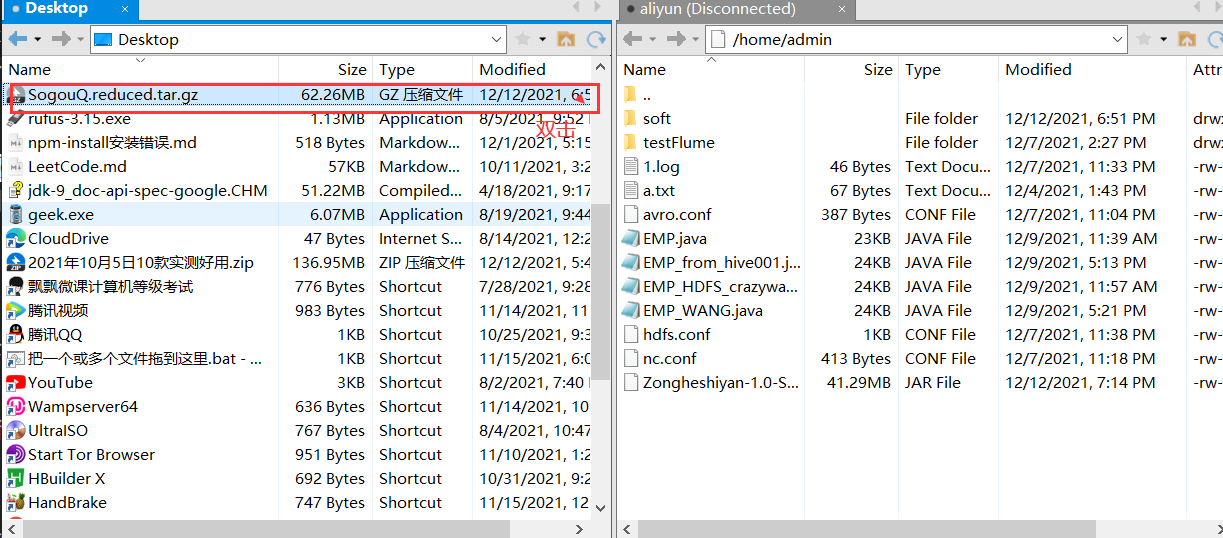
2.2 unzip sogouq reduced. tar. GZ and upload to HDFS
Decompression:
tar -zxvf SogouQ.reduced.tar.gz
You can use the tail command to view the data of the last three lines of the extracted file
tail -3 SogouQ.reduced
The query word is Chinese. The code here is found to be garbled according to UTF-8. When coding, it is specified as' GBK 'to avoid garbled code. The data format is as described above:

Access time user ID [query term] the ranking of the URL in the return result, the sequence number clicked by the user, and the URL clicked by the user
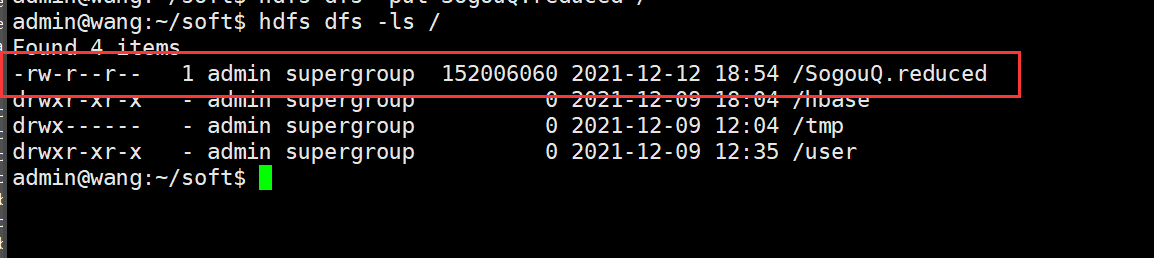
Upload to HDFS:
hdfs dfs -put SogouQ.reduced /
Check whether the upload is successful
hdfs dfs -ls /
3. Data cleaning
Because the number of fields in some rows of the original data is not 6, and the field separator of the original data is not the comma '' and '' specified in Hive table, the original data needs to be cleaned.
Complete data cleaning by writing MapReduce program:
a.Delete rows that do not meet 6 fields b.Change the field separator from unequal spaces to commas','Separator
3.1 idea new Maven project: Zongheshiyan
Group Id is com, and Artifact Id is Zongheshiyan
The directory structure of the new project is as follows:
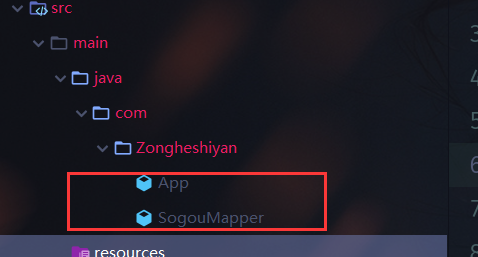
3.2 create two new classes
App and SogouMapper
3.3 modify POM XML file
Set main class: add the following statement before a line
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<!-- main()Note that the package name should be changed to the package name+Main class name -->
<mainClass>com.Zongheshiyan.App</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
Add dependency: add the following statement before a line
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.3</version>
</dependency>
3.4 coding
SogouMapper.java
package com.Zongheshiyan;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
// k1 , v1, k2 , v2
public class SogouMapper extends Mapper<LongWritable,Text,Text,NullWritable> {
@Override
/**
* Called once at the beginning of the task. And will only be called once.
*/
protected void setup(Context context) throws IOException, InterruptedException {
super.setup(context);
}
@Override
protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException {
//Avoid garbled code
//Data format: 201112300000005 57375476989eea12893c0c3811607bcf Qiyi HD 1 http://www.qiyi.com/
String data = new String(v1.getBytes(),0,v1.getLength(),"GBK");
//split("\s+") \s + is a regular expression, which means to match one or more white space characters, including space, tab, page feed, etc.
//reference resources: http://www.runoob.com/java/java-regular-expressions.html
String words[] = data.split("\\s+");
//If the judgment data is not equal to 6 fields, exit the program
if(words.length != 6){
return;//The return statement is followed by no return value. It is used to exit the program https://www.cnblogs.com/paomoopt/p/3746963.html
}
//Replace white space characters with commas
String newData = data.replaceAll("\\s+",",");
//output
context.write(new Text(newData),NullWritable.get());
}
@Override
/**
* Called once at the end of the task. And will only be called once.
*/
protected void cleanup(Context context) throws IOException, InterruptedException {
super.cleanup(context);
}
}
App.java
package com.Zongheshiyan;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* Data washer main class
*
*/
public class App
{
public static void main( String[] args ) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(App.class);
//Specify map output
job.setMapperClass(SogouMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//Specify the output of reduce
job.setOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//Specify input and output
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//Submit the job and wait for the end
job.waitForCompletion(true);
}
}
3.5 packaging works:
mvn clean package
Or idea packaging
3.6 uploading to Linux: Xftp is recommended
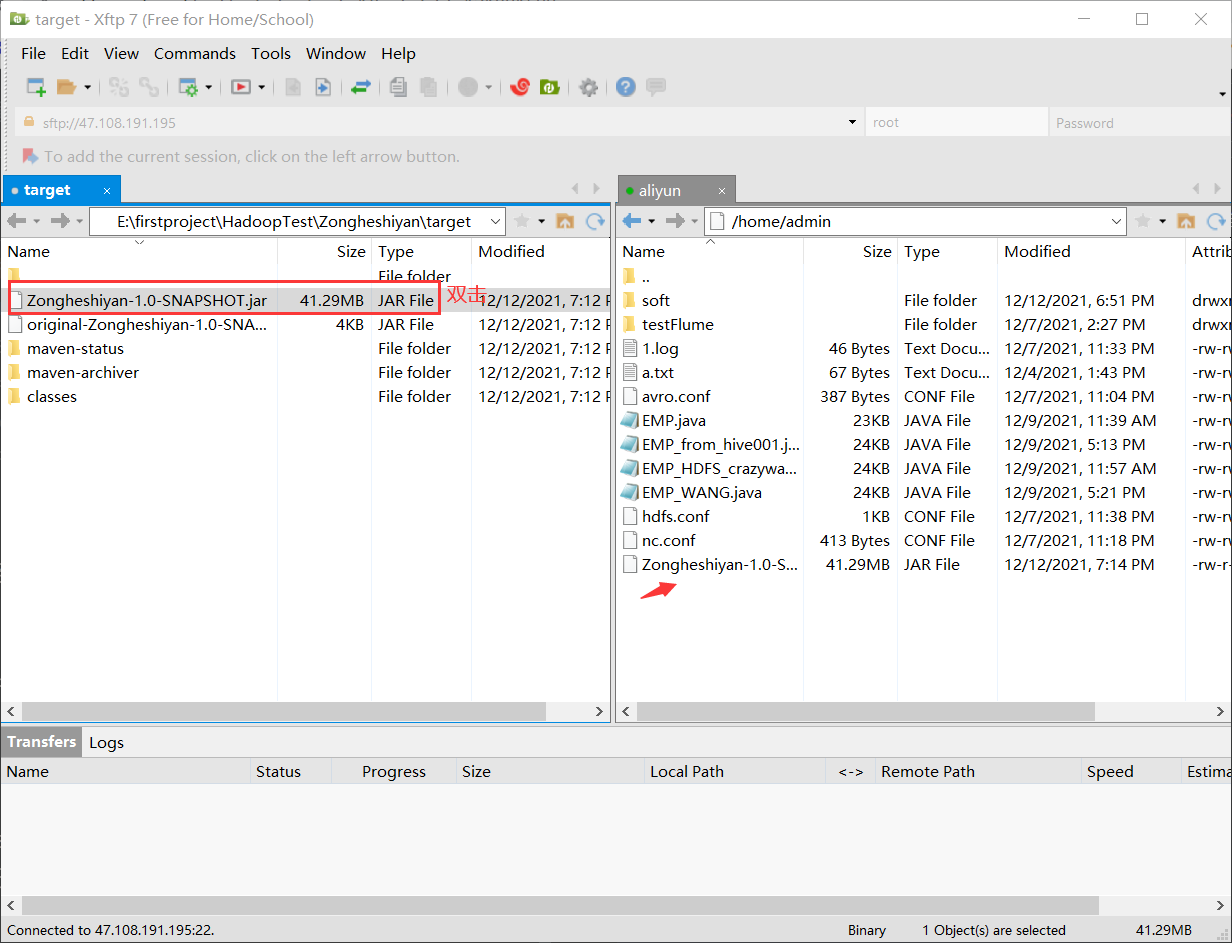
3.7 running jar package
Before running the jar package, make sure that all hadoop processes are started
start-all.sh
jps to see if it is open
Also open the mr history server process
mr-jobhistory-daemon.sh start historyserver

Run the jar package:
hadoop jar Zongheshiyan-1.0-SNAPSHOT.jar /SogouQ.reduced /out/Oneday
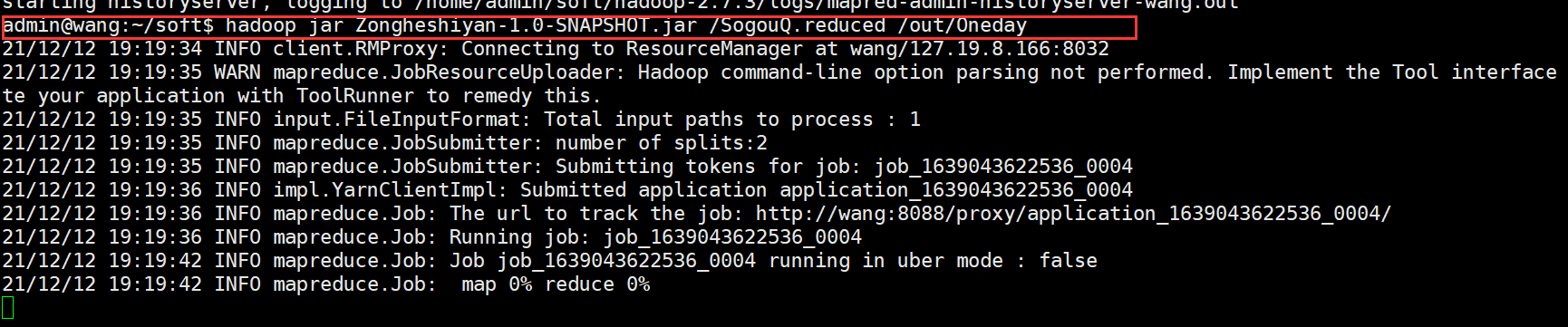
The execution time varies with the machine configuration (about 3 minutes). See the output as shown in the figure below, indicating successful execution.
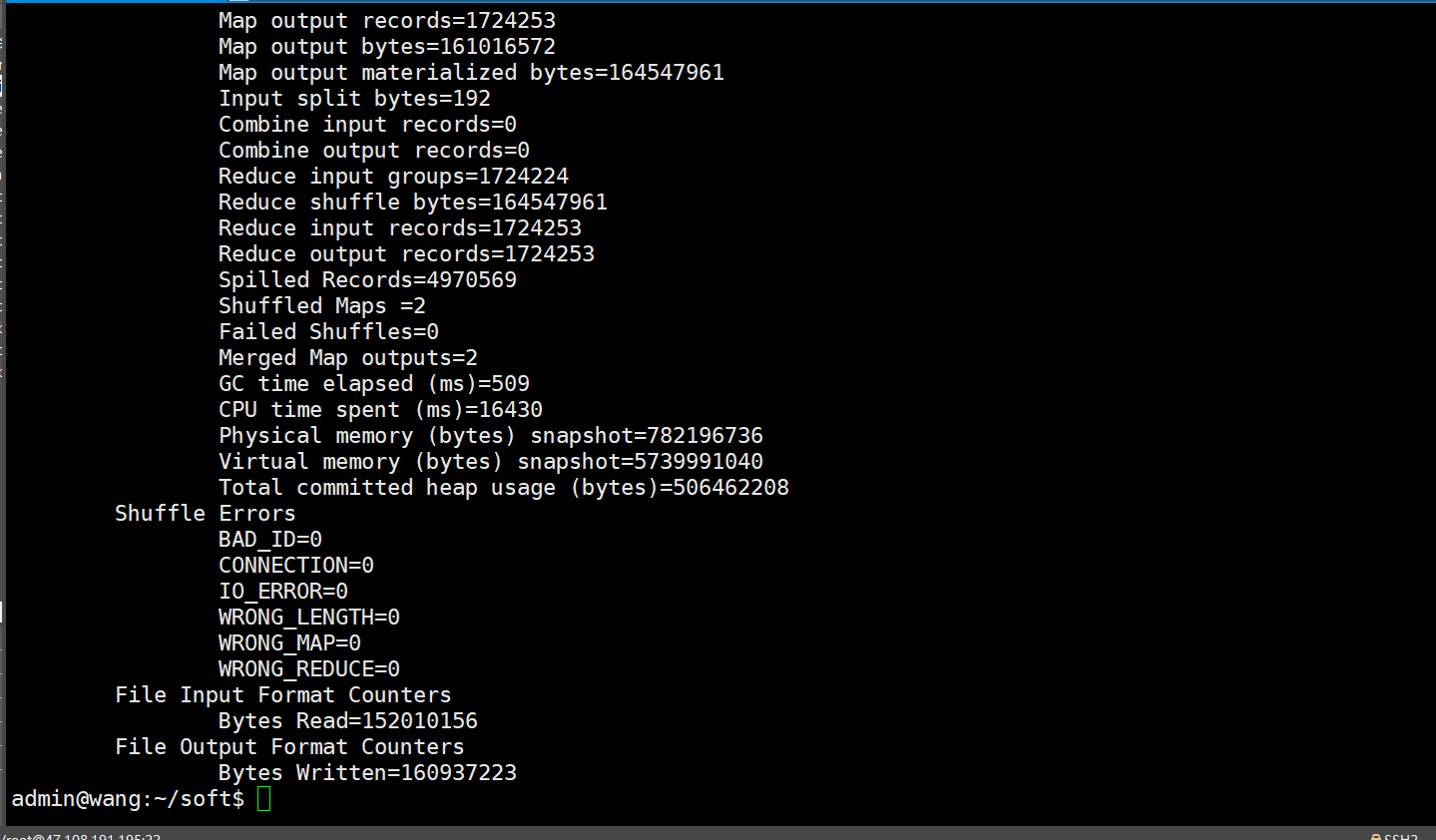
View output results
hdfs dfs -ls /out/Oneday

View the last 10 lines of data in the output file
hdfs dfs -tail /out/Oneday/part-r-00000
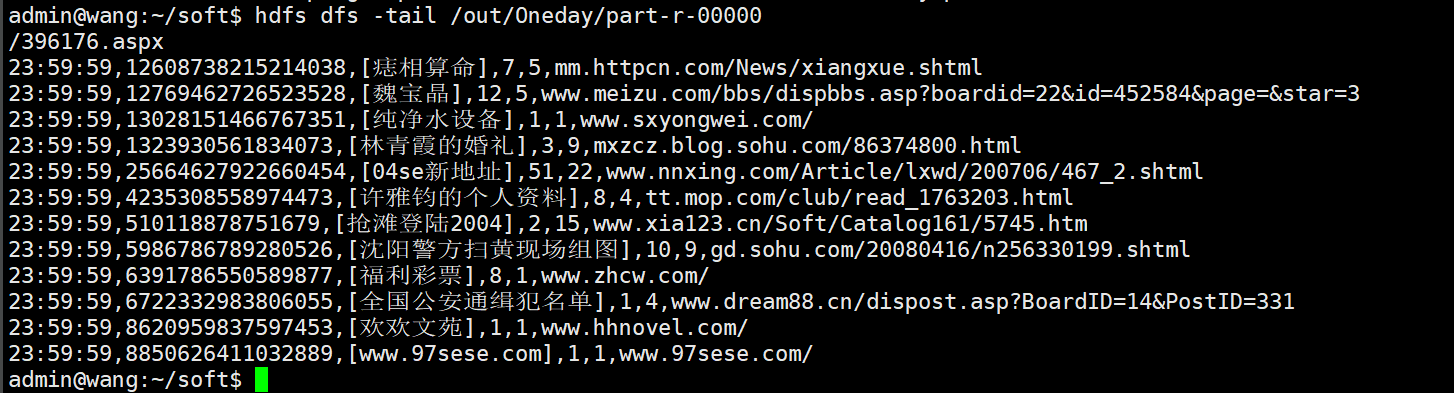
4. Create hive table
Enter the hive command line
hive
Create hive table
create table sogoulog_1(accesstime string,useID string,keyword string,no1 int,clickid int,url string) row format delimited fields terminated by ',';

5. Import MapReduce cleaned data into hive sogoulog_ In Table 1
load data inpath '/out/Oneday/part-r-00000' into table sogoulog_1;

6. Use SQL to query qualified data (only the first 10 items are displayed)
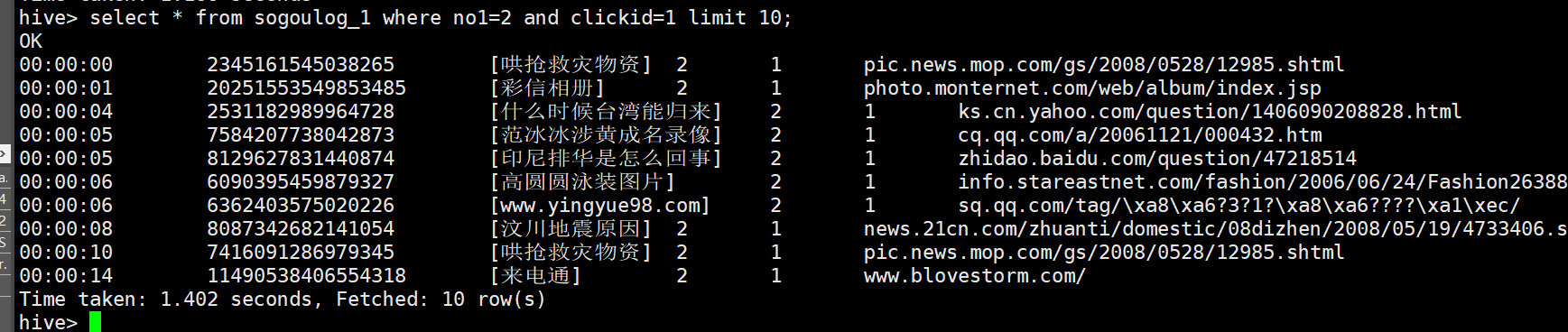
select * from sogoulog_1 where no1=2 and clickid=1 limit 10;
In fact, you can also explore the data, such as:
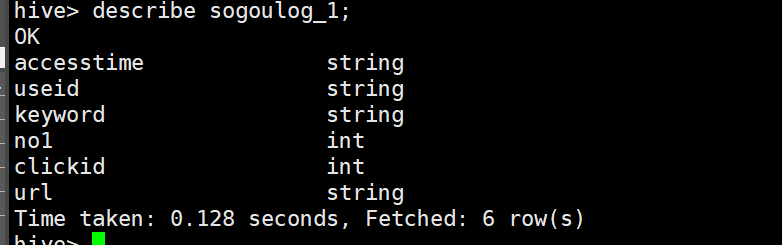
View sogoulog_ Table 1 Structure
describe sogoulog_1;
Number of search keywords in a day
select count(keyword) from sogoulog_1;

In terms of the number of first clicks, the higher the ranking, the more clicks
select count(keyword) from sogoulog_1 where no1=1 and clickid=1;

select count(keyword) from sogoulog_1 where no1=2 and clickid=1;

select count(keyword) from sogoulog_1 where no1=3 and clickid=1;

From the first URL, the smaller the click order is, the more likely it is to be clicked first.
select count(keyword) from sogoulog_1 where no1=1 and clickid=1;

select count(keyword) from sogoulog_1 where no1=1 and clickid=2;

select count(keyword) from sogoulog_1 where no1=1 and clickid=3;

Summary:
MapReduce cleaning the original data is the difficulty of this experiment. It is necessary to understand the code in combination with comments (data cleaning).
hive analyzes the data to find the law / value hidden in the data (data mining).
You can also do data visualization and so on.