Scope function selection
At present, there are let, run, with and apply and also five scope functions.
The official document has a table to illustrate the differences between them:
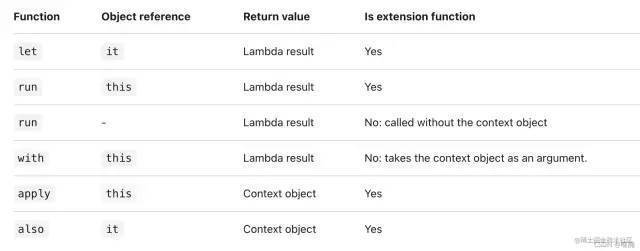
To sum up, there are several differences:
1. apply and also return context objects.
2,let,run And with return lambda results.
3. The reference objects of let and also are it, and the rest are this.
1.let and run are the two most commonly used in my daily life. They are very similar.
private var textView: TextView? = null
textView?.let {
it.text = "Kotlin"
it.textSize = 14f
}
textView?.run {
text = "Kotlin"
textSize = 14f
}In comparison, using run is relatively simple, but the advantage of let is that it can be renamed to improve the readability of the code, and avoid confusing the context object when the scope function is nested.
2. For nullable objects, let is more convenient. For non empty objects, you can use with.
3.apply and also are very similar. The suggestion given in the document is to use apply for object configuration operations and also use also for additional processing. For example:
val numberList = mutableListOf<Double>()
numberList.also { println("Populating the list") }
.apply {
add(2.71)
add(3.14)
add(1.0)
}
.also { println("Sorting the list") }
.sort()In short, it is used according to the meaning of the word to improve the readability of the code.
In general, these functions have many overlapping parts, so they can be used according to the specific situation in development. The above is for reference only.
Sequence
We often use kotlin's set operators, such as map and filter.
list.map {
it * 2
}.filter {
it % 3 == 0
}Old rule, look at the decompiled Code:
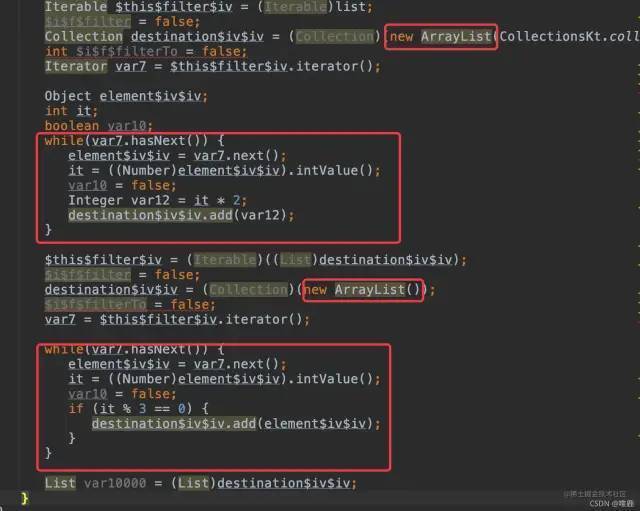
That's what I did. I created two sets and cycled them twice. The efficiency is too low. It's better to write a for loop by yourself, which will be processed in one loop. Take a look at the source code of map:
public inline fun <T, R> Iterable<T>.map(transform: (T) -> R): List<R> {
return mapTo(ArrayList<R>(collectionSizeOrDefault(10)), transform)
}
public inline fun <T, R, C : MutableCollection<in R>> Iterable<T>.mapTo(destination: C, transform: (T) -> R): C {
for (item in this)
destination.add(transform(item))
return destination
}The internal implementation is true. Aren't these operators fragrant?
In fact, you can use Sequences at this time. The usage is very simple. You only need to add an assequence () after the collection method.
list.asSequence().map {
it * 2
}.filter {
it % 3 == 0
}Decompile:
SequencesKt.filter(SequencesKt.map(CollectionsKt.asSequence((Iterable)list), (Function1)null.INSTANCE), (Function1)null.INSTANCE);
There are two functions 1, which are actually lambda expressions. This is because Sequence does not use inlining. Let's first look at the source code of SequencesKt.map:
public fun <T, R> Sequence<T>.map(transform: (T) -> R): Sequence<R> {
return TransformingSequence(this, transform)
}
internal class TransformingSequence<T, R>
constructor(private val sequence: Sequence<T>, private val transformer: (T) -> R) : Sequence<R> {
override fun iterator(): Iterator<R> = object : Iterator<R> {
val iterator = sequence.iterator()
override fun next(): R {
return transformer(iterator.next())
}
override fun hasNext(): Boolean {
return iterator.hasNext()
}
}
internal fun <E> flatten(iterator: (R) -> Iterator<E>): Sequence<E> {
return FlatteningSequence<T, R, E>(sequence, transformer, iterator)
}
}You can see that there is no intermediate set to loop, but a Sequence object is created, which implements the iterator. The SequencesKt.filter method is similar. If you are careful, you will find that this is only the creation of Sequence objects. Therefore, to really get the processed collection, you need to add the end operation of toList().
map and filter are intermediate operations. They return a new Sequence, which contains the actual processing during data iteration. toList and first are end operations used to return results.
Therefore, the execution of Sequence is delayed, which is why it does not have the problem we mentioned at the beginning, and the processing is completed in one cycle.
Summarize the usage scenarios of Sequence:
1. Sequence is recommended when there are multiple set operators.
2. When the amount of data is large, this can avoid creating intermediate sets repeatedly. This is a large amount of data. How can it be more than 10000.
Therefore, for general Android development, there is little difference between not using Sequence... ha-ha..
Synergetic process
Some people will misunderstand kotlin's coroutine and think it has higher performance. It is a "lightweight" thread, similar to the coroutine of go language. But if you think about it, it's impossible. In the end, it has to run on the JVM. You can implement things that java doesn't have. You're not playing the face of java.
Therefore, for the JVM platform, kotlin's coroutine can only encapsulate the Thread API, which is similar to the Executor we use. Therefore, I personally think there is little difference in the performance of the collaborative process. It can only be said that kotlin makes the operation thread easier with the advantage of concise language.
The reason why JVM is mentioned above is that kotlin also has js and native platforms. For them, it may be possible to achieve a real collaborative process.
Recommend the article on collaboration process by the leader of the throwing line to help you better understand kotlin's collaboration process: what is "non blocking" suspension? Is synergy really lighter?
Checked Exception
This is no stranger to students familiar with Java. Checked Exception is a mechanism for handling exceptions. If you declare an exception that may be thrown in your method, the compiler will force the developer to handle the exception, otherwise the compilation will not pass. We need to use try catch Catch exceptions or use throws Throw an exception and handle it.
However, Kotlin does not support this mechanism, that is, it will not force you to handle the thrown exceptions. As for whether the Checked Exception is good or not, there are many disputes. We won't discuss their advantages and disadvantages here.
Since it is a fait accompli that Kotlin does not have this mechanism, we need to consider its impact in use. For example, when calling some methods in our development, we should pay attention to whether there is a specified exception thrown in the source code, and then deal with it accordingly to avoid unnecessary crash.
For example, common json parsing:
private fun test() {
val jsonObject = JSONObject("{...}")
jsonObject.getString("id")
...
}In java, we need to handle JSONException. Because there is no Checked Exception in kotlin, if we use it directly like the above, although the program can run, once there is an exception in parsing, the program will crash.
Intronics check
If you often observe the decompiled java code, you will find many codes like intronics.checkxxx.
fun test(str: String) {
println(str)
}Decompile:
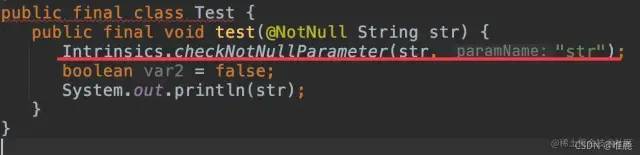
For example, the checkparameterisnotnotnull in the figure is used to check whether the parameter is empty. Although our parameters are uncontrollable, considering that the method will be called by Java, kotlin will add checkparameterisnotnotnull verification by default. If the kotlin method is private, there will be no such line check.
Checkparameterisnotnotnull does not have performance problems. On the contrary, judging whether the parameters are correct in advance can avoid unnecessary resource consumption caused by backward execution of the program.
Of course, if you want to remove it, you can add the following configuration to your gradle file, which will remove it at compile time.
kotlinOptions {
freeCompilerArgs = [
'-Xno-param-assertions',
'-Xno-call-assertions',
'-Xno-receiver-assertions'
]
}Related videos:
Android advanced learning: Kotlin core technology_ Beep beep beep_ bilibili
[advanced Android tutorial] - Analysis of hot repair Principle_ Beep beep beep_ bilibili