I won't say much about installing spark here~
!!! Look! To install mysql and hive:
Install RPM package and download mysql:
sudo yum localinstall https://repo.mysql.com//mysql80-community-release-el7-1.noarch.rpm sudo yum install mysql-community-server
Start MySQL service and view the status:
systemctl start mysqld.service service mysqld status
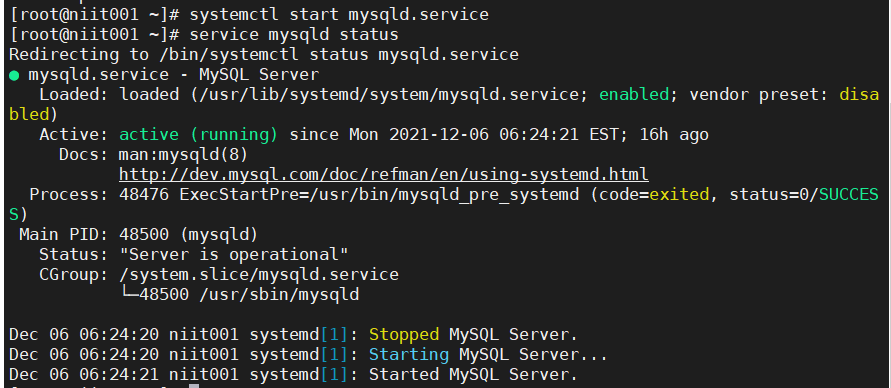
Seeing the integration, it is estimated that the passwords of many small partners should also be OK. If there is any change, remember to restart the MySQL service!
systemctl restart mysqld
All right, install hive:
Unzip: tar -zvxf /tools/apache-hive-2.3.8-bin.tar.gz -C /training/
Configure the environment variable vi ~/.bash_profile,
Remember to save (ESC, shift +:, wq) refresh: source ~ /. Bash after configuration_ profile
#Hive Path export HIVE_HOME=/training/hive export HIVE_CONF_DIR=$HIVE_HOME/conf export PATH=$PATH:$HIVE_HOME/bin
Enter the configuration directory: cd $HIVE_HOME/conf ; Configuration file: vi hive-site.xml; The contents are as follows:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- WARNING!!! This file is auto generated for documentation purposes ONLY! -->
<!-- WARNING!!! Any changes you make to this file will be ignored by Hive. -->
<!-- WARNING!!! You must make your changes in hive-site.xml instead. -->
<!-- Hive Execution Parameters -->
<property>
<name>hive.default.fileformat</name>
<value>TextFile</value>
</property>
<property>
<!--The port is changed to your own port. Here is the onhive database in the connection database. If not, create it later -->
<name>hive.metastore.warehouse.dir</name>
<value>hdfs://niit001:9000/user/hive/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://niit001:3306/hive_metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<!--The latest version of the jar package to connect to MySQL All write com.mysql.cj.jdbc.Driver, if it is the old version with com.mysql.jdbc.Driver-->
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<!--Connect to MySQL username-->
<name>javax.jdo.option.ConnectionUserName</name>
<value>hiveuser</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>hive.aux.jars.path</name>
<value>file:///training/hbase-1.1.3/lib/zookeeper-3.4.6.jar,,file:///training/hbase-1.1.3/lib/guava-12.0.1.jar,file:///training/hbase-1.1.3/lib/hbase-client-1.1.3.jar,file:///training/hbase-1.1.3/lib/hbase-common-1.1.3.jar,file:///training/hbase-1.1.3/lib/hbase-server-1.1.3.jar,file:///training/hbase-1.1.3/lib/hbase-shell-1.1.3.jar,file:///training/hbase-1.1.3/lib/hbase-thrift-1.1.3.jar</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://niit001:9083</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
</configuration>Remember to copy the driver jar package mysql-connector-java-8.0.23.jar to $HIVE_HOME/lib and / Training / spark-2.2.0-bin-hadoop 2.7/jars/ here!
After the driver is installed, it initializes the metabase!
schematool -dbType mysql -initSchema
There's a mistake. Don't worry!
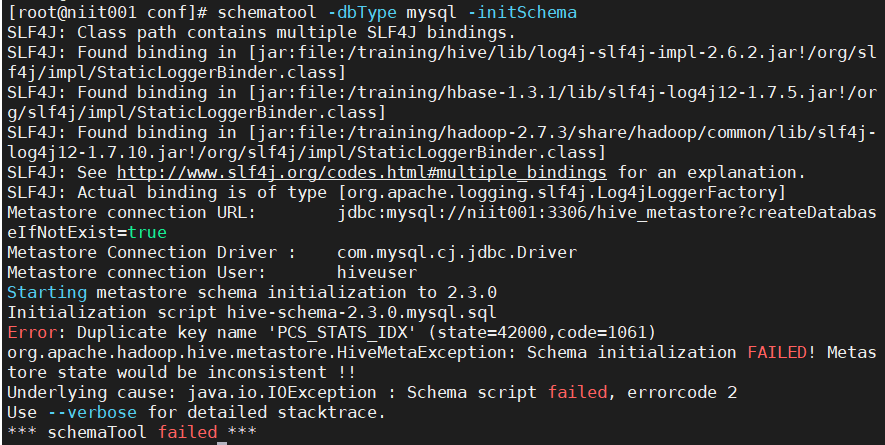
If so, the knowledge meta database has been established in MySQL. We just need to delete it:
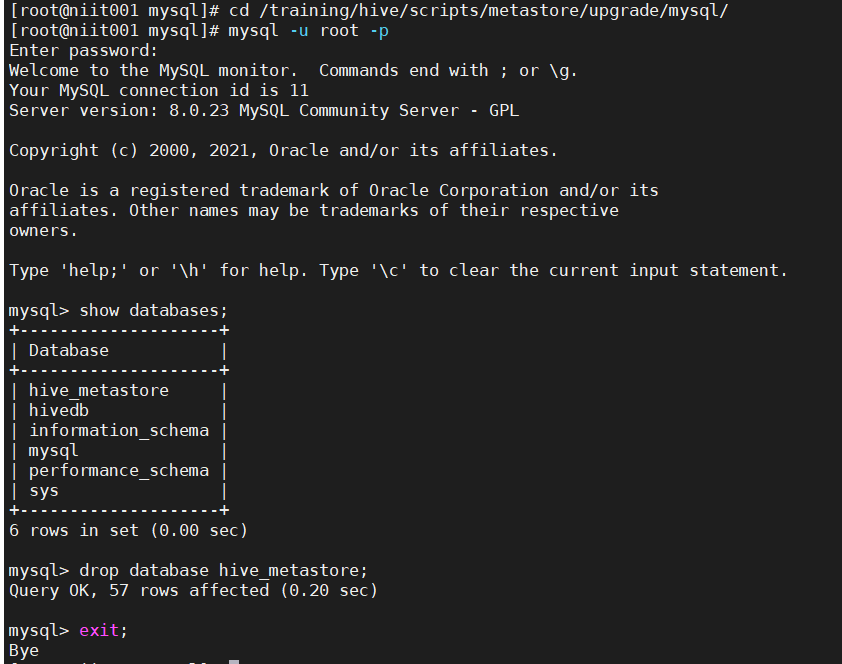
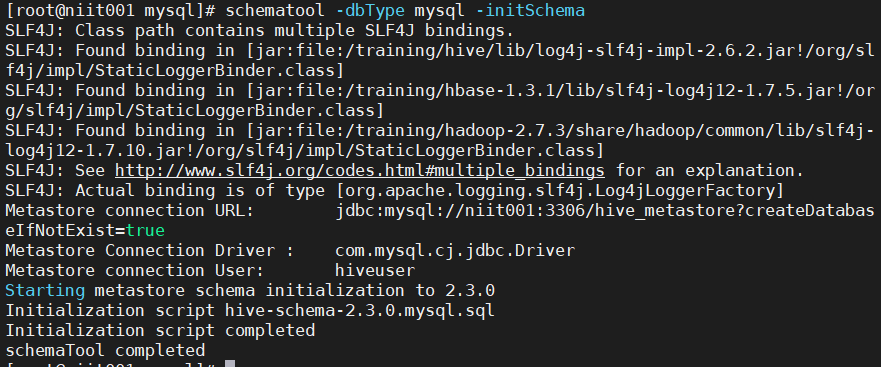
That's OK!
Next, remember to copy the hive and Hadoop configuration files to the spark configuration file directory:
cp $HIVE_HOME/conf/hive-site.xml $SPARK_HOME/conf cp $HADOOP_HOME/etc/hadoop/hdfs-site.xml $SPARK_HOME/conf cp $HADOOP_HOME/etc/hadoop/core-site.xml $SPARK_HOME/conf
Then you can start hive metastore!
! Warm tip: remember to start Hadoop and spark before starting hive!
[root@niit001 mysql]# start-dfs.sh SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/training/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/training/hbase-1.3.1/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] Starting namenodes on [niit001] niit001: starting namenode, logging to /training/hadoop-2.7.3/logs/hadoop-root-namenode-niit001.out niit001: starting datanode, logging to /training/hadoop-2.7.3/logs/hadoop-root-datanode-niit001.out Starting secondary namenodes [0.0.0.0] 0.0.0.0: starting secondarynamenode, logging to /training/hadoop-2.7.3/logs/hadoop-root-secondarynamenode-niit001.out SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/training/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/training/hbase-1.3.1/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] [root@niit001 mysql]# start-yarn.sh starting yarn daemons starting resourcemanager, logging to /training/hadoop-2.7.3/logs/yarn-root-resourcemanager-niit001.out niit001: starting nodemanager, logging to /training/hadoop-2.7.3/logs/yarn-root-nodemanager-niit001.out [root@niit001 mysql]# start-all.sh starting org.apache.spark.deploy.master.Master, logging to /training/spark-2.2.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-niit001.out localhost: starting org.apache.spark.deploy.worker.Worker, logging to /training/spark-2.2.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-niit001.out [root@niit001 mysql]# jps 52752 DataNode 53569 Worker 52627 NameNode 52917 SecondaryNameNode 53191 NodeManager 53640 Jps 53082 ResourceManager 53501 Master [root@niit001 mysql]#
Start hive metastore: hive --service metastore
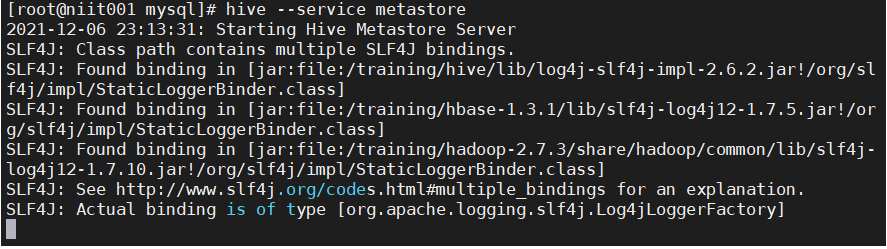
Here, maybe many little friends will be very anxious. Why don't they come out? What's wrong with this
Ha ha, in fact, you have succeeded here!!!
This just starts the process. We open a new window to run MySQL in spark! Look!
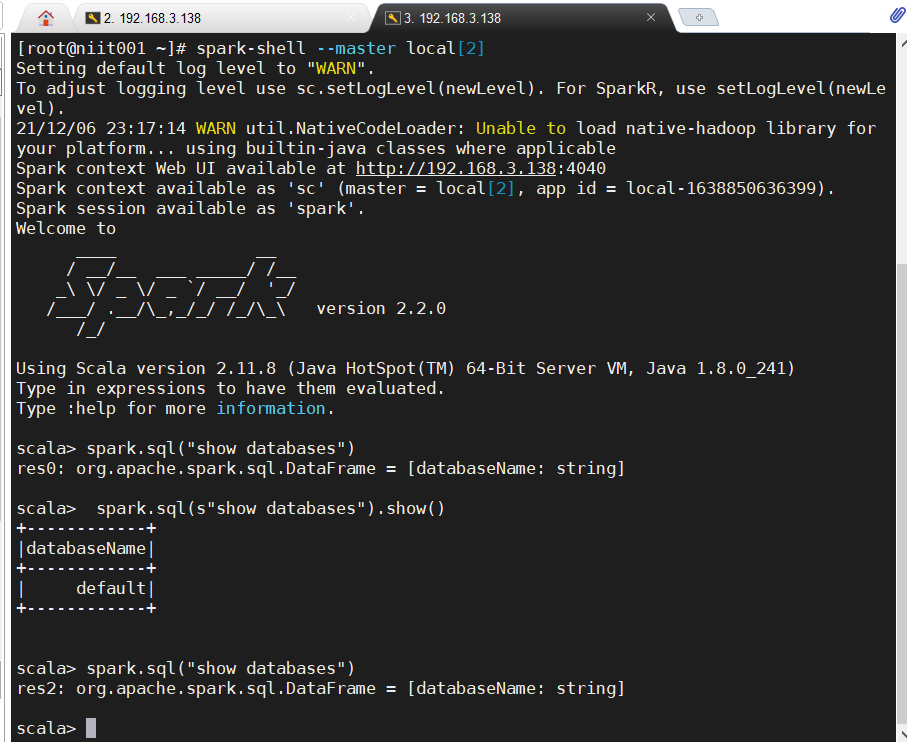
This is success!
If a small partner reports that the driver cannot be found when starting spark shell, it is that the driver has not been copied to the jars directory of spark! You can take a closer look at the driving part mentioned above;
If there are other errors displayed, partners can check jps and kill the extra process - 9 process number;
If the DBS already exists when you start hive metastore, just reinitialize the metabase. If the initialization metabase is wrong, the metabase has been established. Just delete it from MySQL. As mentioned above, pictures are attached!
Come on, everybody! You can also contact me if you have any mistakes!