Spark-SQL
summary
Spark SQL is a spark module used by spark for structured data processing.
For developers, SparkSQL can simplify the development of RDD, improve the development efficiency, and the execution efficiency is very fast. Therefore, in practical work, SparkSQL is basically used. In order to simplify the development of RDD and improve development efficiency, Spark SQL provides two programming abstractions, similar to RDD in Spark Core:
DataFrame
DataSet
SparkSQL features
Easy integration
Seamless integration of SQL query and Spark programming
Unified data access
Connect different data sources in the same way
Compatible with Hive
Run SQL or HiveQL directly on the existing warehouse. Hive is the only SQL on Hadoop tool running on Hadoop in the early stage.
Standard data connection
Connect via JDBC or ODBC
What is a DataFrame
In Spark, DataFrame is a distributed data set based on RDD, which is similar to two-dimensional tables in traditional databases.
The main difference between DataFrame and RDD is that the former has schema meta information, that is, each column of the two-dimensional table dataset represented by DataFrame has a name and type. This enables Spark SQL to gain insight into more structural information, so as to optimize the data sources hidden behind the DataFrame and the transformations acting on the DataFrame, and finally achieve the goal of greatly improving runtime efficiency. In contrast to RDD, because there is no way to know the specific internal structure of the stored data elements, Spark Core can only carry out simple and general pipeline optimization at the stage level.
DataFrame also supports nested data types (struct, array, and map). From the perspective of API usability, DataFrame API provides a set of high-level relational operations, which is more friendly and lower threshold than functional RDD API
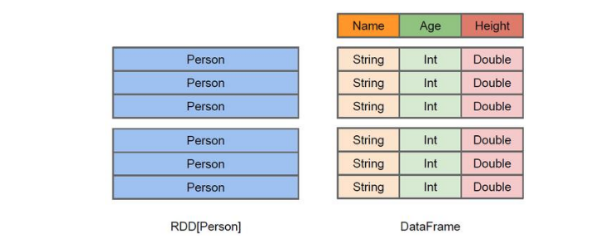
The figure above intuitively shows the difference between DataFrame and RDD.
Although the RDD[Person] on the left takes Person as the type parameter, the Spark framework itself does not understand the internal structure of the Person class. The DataFrame on the right provides detailed structure information, so that Spark SQL can clearly know which columns are included in the dataset, and what is the name and type of each column.
DataFrame is a view that provides a Schema for data. It can be treated as a table in the database.
DataFrame is also lazy, but its performance is higher than RDD. The main reason is that the optimized execution plan, that is, the query plan is optimized through spark catalyst optimizer.
What is a DataSet
DataSet is a distributed data set. DataSet is a new abstraction added in Spark 1.6 and an extension of DataFrame. It provides the advantages of RDD (strong typing, the ability to use powerful lambda functions) and the advantages of SparkSQL optimized execution engine. DataSet can also use functional transformation (operation map,flatMap,filter, etc.).
DataSet is an extension of DataFrame API and the latest data abstraction of SparkSQL
User friendly API style, with both type safety check and query optimization characteristics of DataFrame;
Use the sample class to define the data structure information in the DataSet. The name of each attribute in the sample class is directly mapped to the field name in the DataSet;
DataSet is strongly typed. For example, there can be DataSet[Car],DataSet[Person].
DataFrame is a special column of DataSet, DataFrame=DataSet[Row], so you can convert DataFrame to DataSet through the as method. Row is a type. Like Car and Person, all table structure information is represented by row. The order needs to be specified when getting data
SparkSQL core programming
In Spark Core, if you want to execute an application, you need to first build the context object sparkcontext. Spark SQL can actually be understood as an encapsulation of Spark Core, not only on the model, but also on the context object.
In the old version, SparkSQL provides two SQL query starting points: one is SQLContext, which is used for SQL queries provided by Spark itself; One is called HiveContext, which is used to connect Hive queries.
SparkSession is the starting point of Spark's latest SQL query. It is essentially a combination of SQLContext and HiveContext. Therefore, the API s available on SQLContext and HiveContext can also be used on SparkSession. SparkSession encapsulates SparkContext internally, so the calculation is actually completed by SparkContext. When we use spark shell, the spark framework will automatically create a SparkSession object called spark, just as we can automatically obtain an sc to represent the SparkContext object in the past
DataFrame
The DataFrame API of Spark SQL allows us to use DataFrame without having to register temporary tables or generate SQL expressions. The DataFrame API has both transformation and action operations.
Create DataFrame
In Spark SQL, SparkSession is the entrance to create DataFrame and execute SQL. There are three ways to create DataFrame:
Create through Spark data source;
Convert from an existing RDD;
You can also query and return from HiveTable.
- Create from Spark data source
View the data source formats that Spark supports to create files
scala> spark.read. csv format table text jdbc json textFile load option options orc parquet schema

Create a user. In the bin/data directory of spark JSON file
{"username":"zhangsan","age":20}
{"username":"lisi","age":30}
{"username":"wangwu","age":40}
Read json file to create DataFrame
scala> val df = spark.read.json("data/user.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, username: string]
Note: if you get data from memory, spark can know what the data type is. If it is a number, it is treated as Int by default; However, the type of the number read from the file cannot be determined. Therefore, receiving it with bigint can be converted with Long, but not with Int
Show results
df.show +---+--------+ |age|username| +---+--------+ | 20|zhangsan| | 30| lisi| | 40| wangwu| +---+--------+
2) Convert from RDD
Discussed in subsequent chapters
3) Query from Hive Table and return
Discussed in subsequent chapters
SQL syntax
SQL syntax style means that we use SQL statements to query data. This style of query must be assisted by temporary view or global view
1) Read JSON file and create DataFrame
scala> val df = spark.read.json("data/user.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, username: string]
2) Create a temporary table for the DataFrame
scala> df.createOrReplaceTempView("people")
3) Query the whole table through SQL statement
scala> val sqlDF = spark.sql("SELECT * FROM people")
sqlDF: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
4) Result display
scala> sqlDF.show +---+--------+ |age|username| +---+--------+ | 20|zhangsan| | 30| lisi| | 40| wangwu| +---+--------+
Note: the general temporary table is within the Session range. If you want to be effective within the application range, you can use the global temporary table. Full path access is required when using global temporary tables, such as global_temp.people
5) Create a global table for the DataFrame
scala> df.createGlobalTempView("people")
6) Query the whole table through SQL statement
scala> spark.sql("SELECT * FROM global_temp.people").show()
+---+--------+
|age|username|
+---+--------+
| 20|zhangsan|
| 30| lisi|
| 40| wangwu|
+---+--------+
scala> spark.newSession().sql("SELECT * FROM global_temp.people").show()
+---+--------+
|age|username|
+---+--------+
| 20|zhangsan|
| 30| lisi|
| 40| wangwu|
+---+--------+
DSL syntax
DataFrame provides a domain specific language (DSL) to manage structured data. You can use DSL in Scala, Java, Python and R. you don't have to create temporary views using DSL syntax style
1) Create a DataFrame
scala> val df = spark.read.json("data/user.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
2) View Schema information of DataFrame
scala> df.printSchema root |-- age: Long (nullable = true) |-- username: string (nullable = true)
3) View only the "username" column data,
scala> df.select("username").show()
+--------+
|username|
+--------+
|zhangsan|
|lisi |
|wangwu |
+--------+
Note: when operations are involved, each column must use $, or use quotation mark expression: single quotation mark + field name
scala> df.select($"username",$"age" + 1).show
scala> df.select('username, 'age + 1).show()
scala> df.select('username, 'age + 1 as "newage").show()
+--------+---------+
|username|(age + 1)|
+--------+---------+
|zhangsan|21|
|lisi |31|
|wangwu |41|
+--------+---------+
5) View data with age greater than 30
scala> df.filter($"age">30).show +---+---------+ |age| username| +---+---------+ | 40| wangwu| +---+---------+
6) Group by "age" to view the number of data pieces
scala> df.groupBy("age").count.show
+---+-----+
|age|count|
+---+-----+
| 20|1|
| 30|1|
| 40|1|
+---+-----+
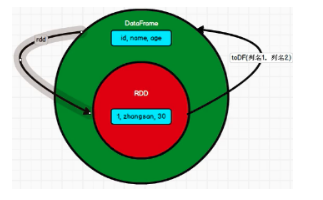
RDD to DataFrame
When developing a program in IDEA, if RDD and DF or DS need to operate with each other, import spark needs to be introduced implicits._
The spark here is not the package name in Scala, but the variable name of the created sparksession object, so you must create a sparksession object before importing. The spark object here cannot be declared with var, because Scala only supports the introduction of val decorated objects.
No import is required in spark shell, and this operation is completed automatically.
.toDF
scala> val idRDD = sc.textFile("data/id.txt")
scala> idRDD.toDF("id").show
+---+
| id|
+---+
| 1|
| 2|
| 3|
| 4|
+---+
In actual development, RDD is generally transformed into DataFrame through sample classes
scala> case class User(name:String, age:Int)
defined class User
scala> sc.makeRDD(List(("zhangsan",30), ("lisi",40))).map(t=>User(t._1,t._2)).toDF.show
+--------+---+
|name |age|
+--------+---+
|zhangsan| 30|
| lisi| 40|
+--------+---+
Convert DataFrame to RDD
DataFrame is actually the encapsulation of RDD, so you can directly obtain the internal RDD
.rdd
scala> val df = sc.makeRDD(List(("zhangsan",30), ("lisi",40))).map(t=>User(t._1,t._2)).toDF
df: org.apache.spark.sql.DataFrame = [name: string, age: int]
scala> val rdd = df.rdd
rdd: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[46]at rdd at <console>:25
scala> val array = rdd.collect
array: Array[org.apache.spark.sql.Row] = Array([zhangsan,30], [lisi,40])
Note: the RDD storage type obtained at this time is Row
scala> array(0)
res28: org .apache.spark.sql.Row = [zhangsan,30]
scala> array(0)(0)
res29: Any = zhangsan
scala> array(0).getAs[String]("name")
res30: String = zhangsan
DataSet
DataSet is a strongly typed data set, and the corresponding type information needs to be provided.
Create DataSet
- Create DataSet using sample class sequence
scala> case class Person(name: String, age: Long)
defined class Person
scala> val caseClassDS = Seq(Person("zhangsan",2)).toDS()
caseClassDS: org.apache.spark.sql.Dataset[Person] = [name: string, age: Long]
scala> caseClassDS.show
+---------+---+
| name|age|
+---------+---+
| zhangsan| 2|
+---------+---+
- Create a DataSet using a sequence of basic types
scala> val ds = Seq(1,2,3,4,5).toDS ds: org.apache.spark.sql.Dataset[Int] = [value: int] scala> ds.show +-----+ |value| +-----+ |1| |2| |3| |4| |5| +-----+
Note: in actual use, it is rarely used to convert a sequence into a DataSet, and it is more used to obtain a DataSet through RDD
RDD to DataSet
SparkSQL can automatically convert the RDD containing the case class into a dataset. The case class defines the structure of the table, and the case class attribute becomes the column name of the table through reflection. Case classes can contain complex structures such as Seq or Array.
scala> case class User(name:String, age:Int)
defined class User
scala> sc.makeRDD(List(("zhangsan",30), ("lisi",49))).map(t=>User(t._1,t._2)).toDS
res11: org.apache.spark.sql.Dataset[User] = [name: string, age: int]
Convert DataSet to RDD
DataSet is actually an encapsulation of RDD, so you can directly obtain the internal RDD
scala> case class User(name:String, age:Int)
defined class User
scala> sc.makeRDD(List(("zhangsan",30), ("lisi",49))).map(t=>User(t._1,t._2)).toDS
res11: org.apache.spark.sql.Dataset[User] = [name: string, age: int]
scala> val rdd = res11.rdd
rdd: org.apache.spark.rdd.RDD[User] = MapPartitionsRDD[51] at rdd at<console>:25
scala> rdd.collect
res12: Array[User] = Array(User(zhangsan,30), User(lisi,49))
DataFrame and DataSet conversion
DataFrame is actually a special case of DataSet, so they can be converted to each other.
Convert DataFrame to DataSet
scala> case class User(name:String, age:Int)
defined class User
scala> val df = sc.makeRDD(List(("zhangsan",30),("lisi",49))).toDF("name","age")
df: org.apache.spark.sql.DataFrame = [name: string, age: int]
scala> val ds = df.as[User]
ds: org.apache.spark.sql.Dataset[User] = [name: string, age: int]
Convert DataSet to DataFrame
scala> val ds = df.as[User] ds: org.apache.spark.sql.Dataset[User] = [name: string, age: int] scala> val df = ds.toDF df: org.apache.spark.sql.DataFrame = [name: string, age: int]
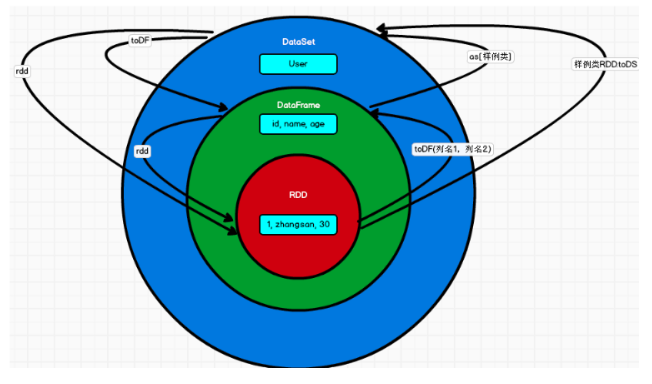
Relationship among RDD, DataFrame and DataSet
In SparkSQL, Spark provides us with two new abstractions: DataFrame and DataSet. First, from the perspective of version generation:
➢ Spark1.0 => RDD
➢ Spark1.3 => DataFrame
➢ Spark1.6 => Dataset
If the same data is given to these three data structures, they will give the same results after calculation respectively. The difference is their execution efficiency and execution mode.
In later Spark versions, DataSet may gradually replace RDD and DataFrame as the only API interface.
The commonness of the three
RDD, DataFrame and DataSet are all distributed elastic data sets under spark platform, which provide convenience for processing super large data;
They all have an inert mechanism. When creating and converting, such as map methods, they will not be executed immediately. They will start traversing operations only when they encounter actions such as foreach;
The three have many common functions, such as filter, sorting, etc;
This package is required for many operations on DataFrame and Dataset: import spark implicits._ (try to import directly after creating the SparkSession object)
All three will automatically cache operations according to Spark's memory conditions, so that even if the amount of data is large, there is no need to worry about memory overflow
All three have the concept of partition
Both DataFrame and DataSet can use pattern matching to obtain the value and type of each field
The difference between the three
RDD
RDD is generally used together with spark mllib
The sparksql operation is not supported by RDD
DataFrame
Different from RDD and Dataset, the type of each Row of DataFrame is fixed as Row, and the value of each column cannot be accessed directly. The value of each field can be obtained only through parsing
DataFrame and DataSet are generally not used together with spark mllib
Both DataFrame and DataSet support SparkSQL operations, such as select and groupby. They can also register temporary tables / windows for sql statement operations
DataFrame and DataSet support some particularly convenient saving methods, such as saving as csv and bringing the header, so that the field name of each column is clear at a glance
DataSet
DataSet and DataFrame have exactly the same member functions, except that the data type of each row is different. DataFrame is actually a special case of DataSet. type DataFrame = Dataset[Row]
DataFrame can also be called Dataset[Row]. The type of each Row is Row, which is not parsed. It is impossible to know which fields each Row has and what types each field is. You can only use the getAS method mentioned above or the pattern matching mentioned in Article 7 of the commonality to take out specific segments. In the Dataset, the type of each Row is not certain. After customizing the case class, you can freely obtain the information of each Row
The mutual transformation of the three