preface:
Hive is a data warehouse tool based on Hadoop, which operates Hadoop data warehouse (HDFS, etc.) with a kind of SQL HQL statement. Therefore, Hadoop needs to be built before installing local windows. The previous article has roughly introduced the environment construction and pit stepping summary, so here is still only the basic installation method. Because there are many articles about hive installation on the Internet. Here is more about the summary and solutions of various pits encountered by Xiaobei in the installation process.
Environmental Science:
1. windows10
2. hadoop2.7.7
3. mysql-connector-java-5.1.7-bin.jar
4. hive2.1.1 , click download
Easy installation:
1. Hadoop is built locally. Skip.
2. Hive download and installation, environment variable configuration, skip.
3. Hive config configuration.
(1). Find the following four files under hive's conf and modify them as follows.

4. Create a directory.
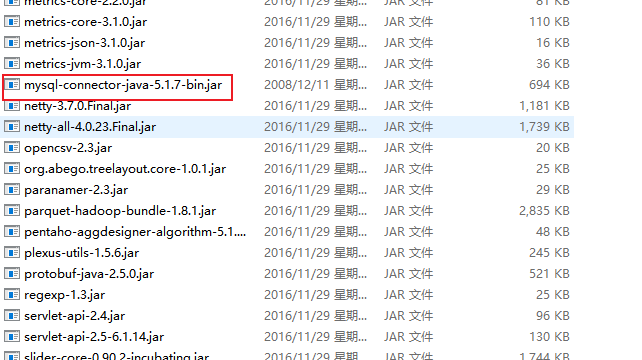
(1). First, mysql-connector-java-5.1.7-bin Move the jar file to hive's lib, as shown below.
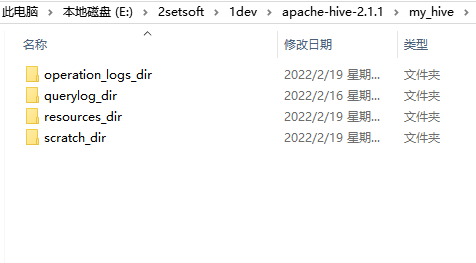
(2). Now create a my in the hive root directory_ Hive creates the following four directories.
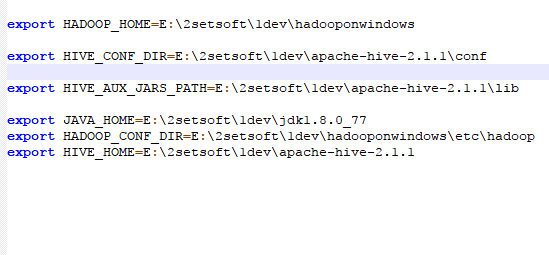
5. Modify HIV Env sh
(1). Find HIV Env under conf SH and add the following configurations.
6. Modify hive site xml
(1). Find hive site under hive's conf xml.
(2). Modify the following options.
<property>
<name>hive.exec.local.scratchdir</name>
<value>${java.io.tmpdir}/${user.name}</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>E:/2setsoft/1dev/apache-hive-2.1.1/my_hive/resources_dir/${hive.session.id}_resources</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?characterEncoding=UTF-8&createDatabaseIfNotExist=true</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
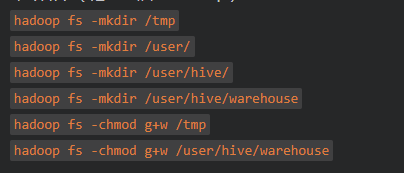
7. Create HDFS directory on Hadopp
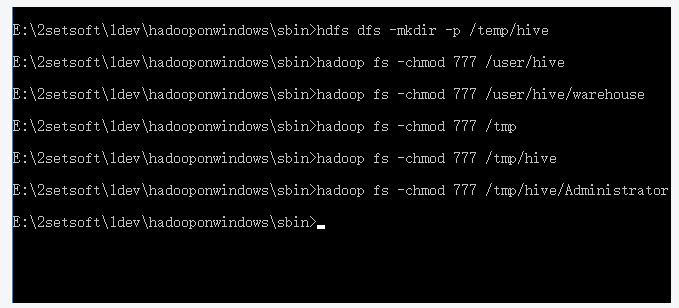
(1). Create the following directory and grant 777 permissions.
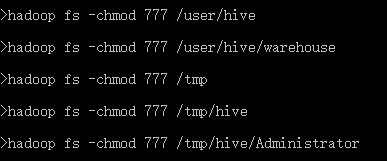
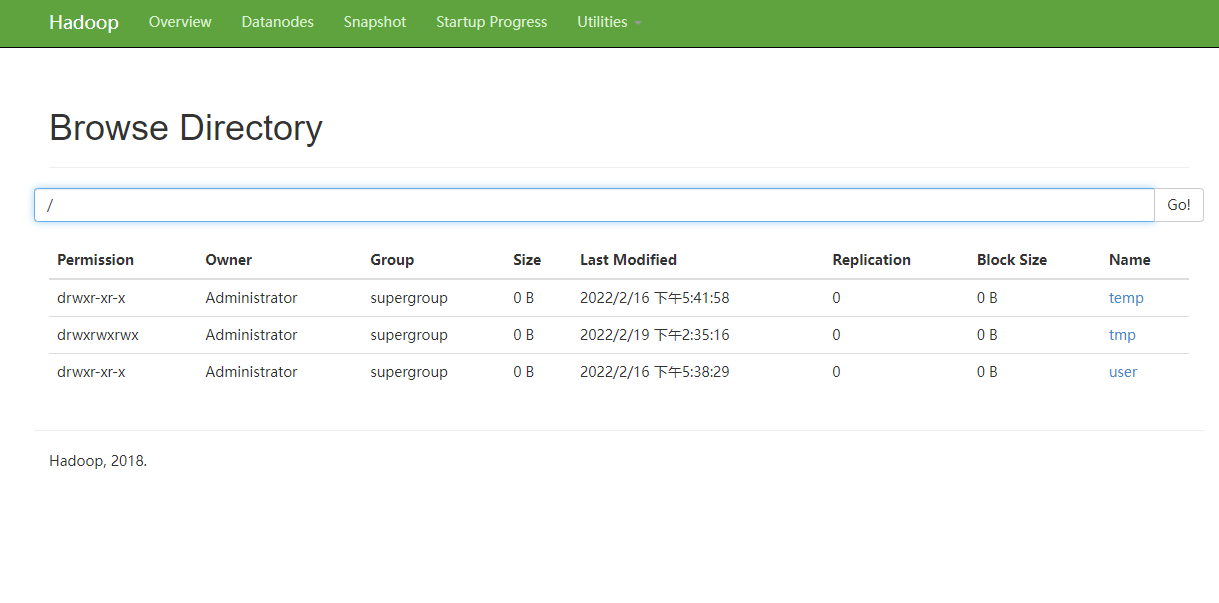
(2). View on the hadoop console.
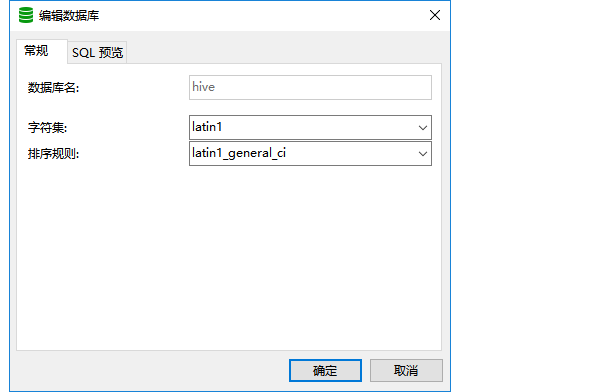
8. Create MySQL database
(1). Create hive database, which can be created by command or navicat.
create database if not exists hive default character set latin1;
9. Start Hive metastore
(1). After installation, you only need to start it once. After startup, the following tables will appear in Mysql hive database.
hive --service metastore

10. Start hive
(1). If the hive environment variable is configured, if not, enter the bin file in the hive directory and enter hive.
(2). The startup is successful and no error is reported. The example creates a table and enters the following HQL statement to create it.
create table stu(id int, name string)
(3). Enter the hadoop console to view it.
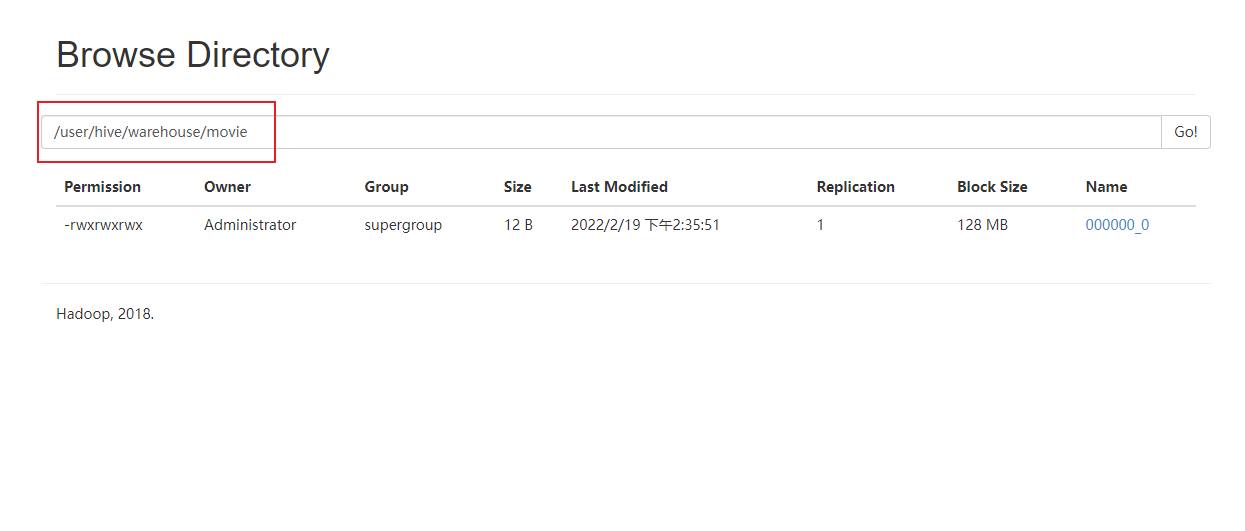
11. Several common commands of HQL
hive start-up hive show databases; View all databases use default; Open the specified database show tables; Display all data tables according to the specified database desc movie; see movie Table structure create movie(id int, name string); Created a id and name Two field table quit; sign out hive
Collection of error reports
1. HiveConf of name hive.metastore.local does not exist
Remove < property > < name > hive.metastore.local </name> <value>true</value> </property>
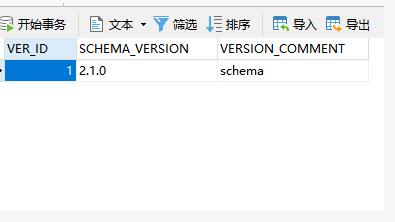
2. Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 2.1.0
Add a record in the version of hive database as follows
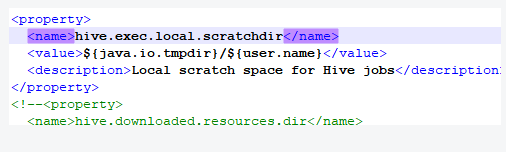
3. applying authorization policy on hive configuration: java.net.URISyntaxException: Relative path in absolute URI: ${system:java.io.tmpdir%7D/$%7Bsystem:user.name%7D Beeline version 2.1.1 by Apache Hive
Open hive site XML, find hive exec. local. Scratchdir, remove all identifiers with system:, as follows
4. hadoop's web console file system, open a directory and report an error: Permission denied: user=dr.who, access=READ_EXECUTE, inode="/tmp/hive/Administrator":Administrator:supergroup:drwx------
Enter the hadoop command and enter hadoop fs -chmod 777 /tmp/hive
attach
Default data warehouse default location: under: / user/hive/warehouse Path on hdfs
<property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> <description>location of default database for the warehouse</description> </property>
Communication learning
