Xiao Bai used a relational database such as Oracle before, and summarized the knack of relational database optimization - see the explanation plan. Oracle is a mature product. Interpretation plans include many categories, real and virtual. By observing different kinds of interpreted plan data, we can grasp the vast majority of sql data from input to output. Here is an example of oracle's interpretation code:
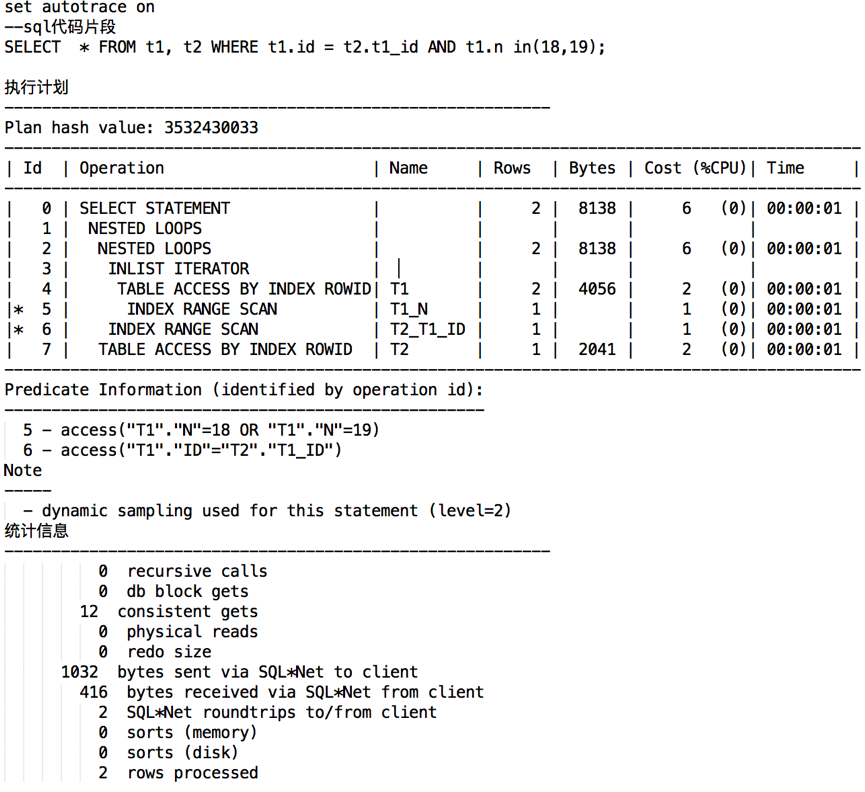
Above are Oracle's two tables t1 and t2 for join t's predictive interpretation plan.
In that section of the execution plan, we can see the logic of execution of this code. Each logic involves Rows, Bytes, Time, Cost of execution.
In the statistical information, we can see the recursive calls, db block gets, consistant gets, physical reads and other information. This information can directly understand the data parameters of each stage of sql execution for locating and tuning.
Xiao Bai feels that HIVE is also a database, and should be able to solve most of the problems with an explanation plan. With this in mind, when you can't stand the slow HIVE SQL, for the first time, open the code snippet that explains the following:
**hive> explain \> select s_age,count(1) \> from student\_tb\_txt \> group by s_age; OK STAGE DEPENDENCIES: Stage-1 is a root stage Stage-0 depends on stages: Stage-1 STAGE PLANS: Stage: Stage-1 Map Reduce Map Operator Tree: TableScan alias: student\_tb\_txt Statistics: Num rows: 20000000 Data size: 54581459872 Basic stats: COMPLETE Column stats: NONE Select Operator expressions: s_age (type: bigint) outputColumnNames: s_age Statistics: Num rows: 20000000 Data size: 54581459872 Basic stats: COMPLETE Column stats: NONE Group By Operator aggregations: count(1) keys: s_age (type: bigint) mode: hash outputColumnNames: \_col0, \_col1 Statistics: Num rows: 20000000 Data size: 54581459872 Basic stats: COMPLETE Column stats: NONE Reduce Output Operator key expressions: _col0 (type: bigint) sort order: + Map-reduce partition columns: _col0 (type: bigint) Statistics: Num rows: 20000000 Data size: 54581459872 Basic stats: COMPLETE Column stats: NONE value expressions: _col1 (type: bigint) Reduce Operator Tree: Group By Operator aggregations: count(VALUE._col0) keys: KEY._col0 (type: bigint) mode: mergepartial outputColumnNames: \_col0, \_col1 Statistics: Num rows: 10000000 Data size: 27290729936 Basic stats: COMPLETE Column stats: NONE File Output Operator compressed: false Statistics: Num rows: 10000000 Data size: 27290729936 Basic stats: COMPLETE Column stats: NONE table: input format: org.apache.hadoop.mapred.TextInputFormat output format: org.apache.hadoop.hive.\ ql.io.HiveIgnoreKeyTextOutputFormat serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe**
Xiao Bai first saw this explanation plan in a confused face, after consulting the HIVE official website information slowly understand that the above information describes the implementation logic of MapReduce. If HIVE is set up on Hadoop cluster, HIVE-SQL will resolve and transform into MapReduce operator by default (if it is set up on Spark cluster, it will transform into Spark operator) to perform calculation. Xiao Bai realizes that HIVE is actually the encapsulation of computing engine. To further understand the optimization of HIVE, the key is to understand the underlying computing engine - MapReduce. However, for the habit of writing SQL, this kind of data-oriented programming way of thinking, to understand the code written with object-oriented is really difficult. Xiao Bai was distressed for a while. To understand and master a kind of programming method, the most important thing is to practice, so Xiao Bai opened it. http://hadoop.apache.org/ The website, saw the well-known hadoop introductory case - wordcount case.
public class WordCount { #Mapper generics accept and declare four parameters. #The first two represent the data types of the read files k and v, corresponding to the first two parameter types of the map function below. #The latter two represent the data types of map output k and v. #The context.write() function in the map function accepts the same data type as these two data types. public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); # Code Acceptance of Map Execution Logic # The following code actually accepts three parameters # The Map stage key represents the offset, value represents the content of each line, and context represents the context of MapReduce public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { #Divide a row of data contents into iterative sets by spaces StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { #mapreduce does not accept java data types and must be converted to mapreduce identifiable types #For example, String in java corresponds to Text, IntWritable in int, etc. word.set(itr.nextToken()); #context writes the file to the temporary directory of HDFS and waits for the Reducer node to fetch it. #Write to the HDFS file, each line in the form of: word1 1 1 context.write(word, one); } } } #Reducer generics also accept the declaration of four parameters. #The first two represent the data types of reading Mapper output k and v, which are consistent with the data types of the latter two parameters of Mapper generic. #The latter two represent the data types of k and v output by Reducer. #The context.write() function in reduce function accepts the same data type as these two data types. public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); # Logical code for Reduce phase execution public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); #context writes the result to hdfs #In HDFS files, each line is represented as: word 1 sum #Where sum represents a specific value context.write(key, result); } } public static void main(String\[\] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); #Combiner actually executes the same logic as reducer, so the processing class of Combiner can be represented directly by the Reducer class. #Unlike Reducer, combiner is executed at the node where the Map phase is located. job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args\[0\])); FileOutputFormat.setOutputPath(job, new Path(args\[1\])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
Xiao Bai read the wordcount code several times, copy the wordcount code once, then try to use MapReduce to write some business logic previously written in Sql, such as - PV statistics, UV statistics. After writing several MapReduce examples, Xiaobai summarizes and draws the following wordcount data transformation process in MapReduce.

Xiao Bai finishes the picture above, feels that he has a clear understanding of MapReducer's data processing logic, and begins to understand the key words in the plan and the meaning of the expression. But he wondered that in relational database database, quantified data such as data that can be processed at each stage, resources consumed and processing time can be explained by the plan. But the explanation plan provided by HIVE is too simple to have any data at all. It also means that although the users of HIVE know the execution logic of the whole SQL, the resource status consumed at which stage, and the whole SQL. Where is the bottleneck of execution? What shall I do? Xiao Bai did not know what to do for a while, so he went to the old bird in the help group.
Old Bird said, "The real running information of all stages of HIVE sql can be seen in the log. Look at the links to this log. You can find them in the information printed by the console after each job is executed. You can look carefully. Xiao Bai then tried to execute one sql and got the following information:

Xiaobai found a log link in Starting Job,Tracking URL. Click on the link to get the following page:

Xiao Bai is a little excited to see such an interface. He knows from the information of the page that this page reflects the overall situation of the operation of SQL. So he continued to try to dig up more information on this page. Clicking on the Counters link, he noticed some information he was familiar with, as follows: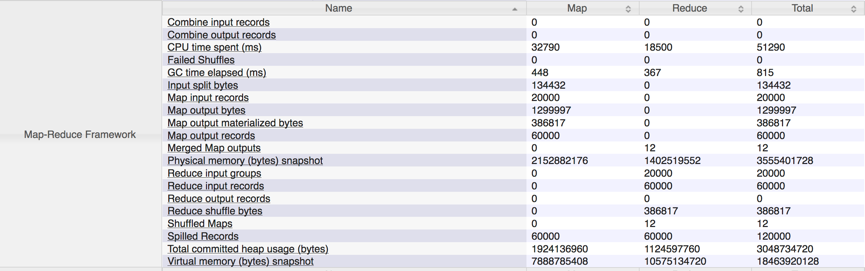
Seeing the key words of Map input/ouput, Combiner, Reduce in the picture above, Xiao Bai Daxi muttered, "This information should be the quantitative data describing MapReduce operations at all stages!" Mastering these can also play a relatively large role in the subsequent tuning. So Xiao Bai began to consult various materials, one by one to clarify the meaning of the keywords under the Counters page. But now Xiaobai is in a dilemma. We know that most of the HIV ESQL is ultimately converted to MapReduce for execution. How can HIVE tuning interfere with MapReduce to achieve the final tuning? According to Xiaobai's past experience in writing PL-SQL/T-SQL, I summarized three experiences:
1) Implement MapReduce execution process control by rewriting SQL, and then achieve optimization. 2) Control the execution process of MapRedcue through hint grammar, and then achieve optimization. 3) Realize the optimization of SQL through some configuration switches which are open to the database.
Following the three experiences summarized by Xiaobai above, Xiaobai began to sum up one by one. For the first lesson, Xiao Bai began to learn how to collect various HIVE SQL scripts to improve HIVE by rewriting SQL to optimize MapReduce execution process. For example, here is an example of Xiao Bai's collection.
Case 1
--Before rewriting select * from( select s_age,s_sex,count(1) num from student_tb_orc group by s_age,s_sex union all select s_age,null s_sex,count(1) num from student_tb_orc group by s_age ) a --After rewriting select s_age,s_sex,count(1) num from student_tb_orc group by s_age,s_sex grouping sets((s_age),(s_age,s_sex))
Case 2
--Before rewriting --Statistical analysis of different age groups, the number of different scores select s_age,count(distinct s_score) num from student_tb_orc group by s_age --After rewriting select s_age,sum(1) num from( select s_age,s_score,count(1) num group by s_age,s_score ) a
Xiao Bai collected a bunch of rewriting SQL and tried to memorize these rules. Xiao Baizizizi tirelessly collects these rules and applies them directly when he encounters similar codes. By analogizing the PL-SQL optimization method, Xiaobai first tastes sweet. Start preparing to learn the hint command of HIVE to enrich your optimization skills. Xiao Bai began to browse his wiki. He did find that HIVE supports hint commands. The following two kinds of hints are the most common. See the following cases: Case 3:
--MAPJOIN()Specifies a table with a small amount of data, which is represented in Map Phase completion a,b Connection of tables, --Will be in the original Reduce To perform connection operations, push forward to Map stage SELECT /*+ MAPJOIN(b) */ a.key, a.value FROM a JOIN b ON a.key = b.key
Case 4:
--STREAMTABLE()A table with a large amount of data specified in the table. --By default, the reduce The phase is connected. hive Put the left table data in the cache and the right table data in the stream. --If you want to change the way above, use/*+streamtable(Table name)*/To specify the table you want to use as streaming data SELECT /*+ STREAMTABLE(a) */ a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
HIVE support is limited in hint grammar, but Xiao Bai does feel that these commands have a huge performance improvement in practice. Hint grammar is frequently used in practice. Xiao Bai feels that previous experience with PL-SQL/T-SQL can be used in HIVE SQL. However, in relational databases, through some configuration switches open to the database, to achieve the optimization of SQL, which is generally a database with higher authority, can be done. Xiao Bai is skeptical about the frequency of practical application of SQL tuning through database configuration items. The project is also in a hurry, Xiao Bai has no time to study deeply, and also feels that the current skills can be used to deal with the current task is good.