In the process of Python crawler, some websites need to pass the verification code before entering the web page. The purpose is very simple, that is to distinguish between human reading and machine crawler. The problem of verification code seems simple. It is not easy to achieve high accuracy. In order to learn more about reptiles, the following tweets will introduce more solutions to reptile problems. This tweet will share three ways to solve the verification code. If you have a better scheme, welcome to discuss and communicate in the message area to make progress together.
1.pytesseract
Many people study python and don't know where to start.
Many people learn python, master the basic syntax, do not know where to find cases to start.
Many people who have already done cases do not know how to learn more advanced knowledge.
Then for these three types of people, I will provide you with a good learning platform, free access to video tutorials, e-books, and the source code of the course!
QQ group: 1097524789
Pyteseract is an ocr library made by google, which can recognize the text in the picture. It is generally used to identify the verification code when the crawler logs in. During the installation of pyteseract environment, there will be various kinds of pit things. If you need to install, you can follow the following process to avoid stepping on the pit. Take mac as an example.
1. Installation method
pip install pytesseract

2. In addition, Tesseract needs to be installed. It is an open source OCR engine that can recognize more than 100 languages.
brew install tesseract
3. Check that the installation location is
brew list tesseract /usr/local/Cellar/tesseract/4.1.1/bin/tesseract /usr/local/Cellar/tesseract/4.1.1/include/tesseract/ (19 files) /usr/local/Cellar/tesseract/4.1.1/lib/libtesseract.4.dylib /usr/local/Cellar/tesseract/4.1.1/lib/pkgconfig/tesseract.pc /usr/local/Cellar/tesseract/4.1.1/lib/ (2 other files) /usr/local/Cellar/tesseract/4.1.1/share/tessdata/ (35 files)
4. Configure environment variables
export TESSDATA_PREFIX=/usr/local/Cellar/tesseract/4.1.1/share/tessdata export PATH=$PATH:$TESSDATA_PREFIX
5. How to report an error as follows
'TesseractNotFoundError: tesseract is not installed or it's not in your PATH'
6. Modify cmd of pyteseract.py
'tesseract_cmd = '/usr/local/Cellar/tesseract/4.1.1/bin/tesseract''
Verify a simple verification code first
The code is as follows
from PIL import Image,ImageFilter import pytesseract path ='/Users/****/***.jpg' captcha = Image.open(path) result = pytesseract.image_to_string(captcha) print(result)
Result output
51188
Try another one

After entering the code, the result error output is
1364
It can be seen from this that pyteseract is effective for simple methods, not as good as some people write. Of course, we can use gray-scale, binary and other methods, and the effect is not very ideal. If it is a little complex, we need to find other solutions. If we solve the above problems, let's look at the following solutions.
2. Baidu OCR interface
Call Baidu OCR interface (code example)
# encoding:utf-8
import requests
import base64
'''
//Universal character recognition (high precision version)
'''
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
#Open picture file in binary mode
f = open('[Local file]', 'rb')
img = base64.b64encode(f.read())
params = {"image":img}
access_token = '[Call the authentication interface to obtain token]'
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
print (response.json())
For the problems not solved in the above scheme, call this method to try and solve them successfully.
7364
What about more complex verification codes?

Call the result output directly first
Ygax6-
The results show that Baidu OCR interface can recognize complex verification code, but the problem of interference line cannot be solved. How to solve the above problems? For complex verification codes, we can't call them directly. We do some preprocessing first: grayscale, binarization, etc.
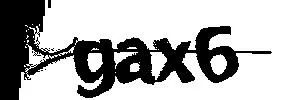
Call interface again
gax6
The above problems have been solved. How to solve the super abnormal verification code? How many zeros? How many O's? Here is a deep learning solution.

3. Deep learning
Deep learning verification code recognition may not be suitable for everyone, for the simple reason that not everyone has the algorithm basis first. Secondly, Xiaobian tests it in person, and the consumption of cpu resources is also very high. If you have cloud resources, you can run. For deep learning verification code recognition, I will introduce the idea of the solution. At present, enterprise level verification recognition is more complex.
1. Build a deep learning model based on keras framework
from keras.models import * from keras.layers import * input_tensor = Input((height, width, 3)) x = input_tensor for i in range(4): x = Convolution2D(32*2**i, 3, 3, activation='relu')(x) x = Convolution2D(32*2**i, 3, 3, activation='relu')(x) x = MaxPooling2D((2, 2))(x) x = Flatten()(x) x = Dropout(0.25)(x) x = [Dense(n_class, activation='softmax', name='c%d'%(i+1))(x) for i in range(4)] model = Model(input=input_tensor, output=x) model.compile(loss='categorical_crossentropy', optimizer='adadelta', metrics=['accuracy'])
2. Model training
model.fit_generator(gen(), samples_per_epoch=51200, nb_epoch=5, nb_worker=2, pickle_safe=True, validation_data=gen(), nb_val_samples=1280)
3. Test model
X, y = next(gen(1))
y_pred = model.predict(X)
plt.title('real: %s\npred:%s'%(decode(y), decode(y_pred)))
plt.imshow(X[0], cmap='gray')
4. Result display

conclusion
As the beginning of tweet said, the problem of verification code identification seems simple, but in fact, it is much more complex than expected. Some solutions may also be targeted solutions. At present, there is a long way to go for a universal solution. It's not terrible to encounter difficulties. We can discuss and communicate with each other