operating system
ubuntu 18.04
premise
I want to be here c file using cuda's function, that is Content of cu
Installing nvcc is not the content here, but make sure that nvcc can be used, which is to ensure that it can be compiled On the premise of cu, view the version of nvcc, and the command is as follows
nvcc --version
The output is as follows
nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2017 NVIDIA Corporation Built on Fri_Nov__3_21:07:56_CDT_2017 Cuda compilation tools, release 9.1, V9.1.85
The first way is to use the cuda function
The first way is to use cuda's functions in the form of lib
Five gpu threads are used in the foo file to execute the kernel function foo
The contents of the document are as follows
foo. The content of H is as follows. ifdef is added to facilitate our introduction If extern is not removed when calling c, an error will be reported
#ifndef FOO_CUH #define FOO_CUH #include <stdio.h> //__global__ void foo(); #ifdef EXPORTS extern "C" #endif void useCUDA(); #endif
foo. The contents are as follows:
#define EXPORTS
#include "foo.h"
#define CHECK(res) { if(res != cudaSuccess){printf("Error : %s:%d , ", __FILE__,__LINE__); \
printf("code : %d , reason : %s \n", res,cudaGetErrorString(res));exit(-1);}}
__global__ void foo()
{
printf("CUDA!\n");
}
void useCUDA()
{
foo<<<1,5>>>();
printf("CUDA zeng!\n");
CHECK(cudaDeviceSynchronize());
}
main.c the contents are as follows:
#include <stdio.h>
#include "foo.h"
int main()
{
useCUDA();
return 0;
}
Start compilation
Compile foo into with nvcc a library
nvcc -c foo.cu -o foo.o ar cr libfoo.a foo.o
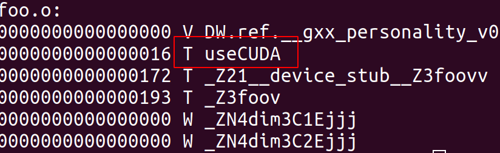
Check it out a whether the corresponding symbols have been exported
nm -g --defined-only libfoo.a
You can see the correct export
Link libfoo A and compile main c
gcc main.c -o main libfoo.a -lcudart -lcuda -lstdc++
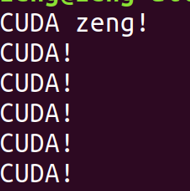
Execute generated main
.main
You can see the output as follows
If main is cpp, you can use the following command
g++ main.cpp -o main libfoo.a -lcudart -lcuda -lstdc++
Sort out the used sh file content
nvcc -c foo.cu -o foo.o ar cr libfoo.a foo.o nm -g --defined-only libfoo.a gcc main.c -o main libfoo.a -lcudart -lcuda -lstdc++
The second way is to use the cuda function
This method does not intend to use lib to introduce direct channels o to load. This form is relatively simple, but not very flexible. If one day I need to modify the contents of foo files, I have to compile main again after recompiling
The second way is common c call mode, put the script directly
rm -rf *.o main nvcc -c foo.cu -o foo.o gcc -Wall -c main.c gcc -o main foo.o main.o -lcudart -lcuda -lstdc++ ./main
The third way is to use the cuda function
Use in accordance with ffmpeg The way of cu, first of all cu compiled into ptx, and then load this in the source code ptx and use func inside, where ptx is platform independent assembly code
The following is the cubin used for the test Cu, he has three functions
#include <stdio.h>
#include <cuda_runtime.h>
extern "C" __global__ void kernel_run(){
printf("hello world!\n");
}
extern "C" __global__ void kernel_run2(void *p1, void *p2){
printf("p1:%c====p2:%c.\r\n", p1, p2);
}
extern "C" __global__ void kernel_add(int *sum, int *p1, int *p2){
*sum = *p1 + *p2;
}
main.c loads this first ptx file, then load these three functions and call
#include <stdio.h>
#include <string.h>
#include <cuda_runtime.h>
#include <cuda.h>
int main(){
CUresult error;
CUdevice cuDevice;
cuInit(0);
int deviceCount = 0;
error = cuDeviceGetCount(&deviceCount);
printf("device count is %d\n",deviceCount);
error = cuDeviceGet(&cuDevice, 0);
if(error!=CUDA_SUCCESS){
printf("Error happened in get device!\n");
}
CUcontext cuContext;
error = cuCtxCreate(&cuContext, 0, cuDevice);
if(error!=CUDA_SUCCESS){
printf("Error happened in create context!\n");
}
// Use the compiled cubin
CUmodule module;
CUfunction function; // Call kernel_run
CUfunction function2; // Call kernel_run2
CUfunction function3; // Call kernel_add
const char* module_file = "cubin.ptx";
const char* kernel_name = "kernel_run";
const char* kernel_name2 = "kernel_run2";
const char* kernel_name3 = "kernel_add";
error = cuModuleLoad(&module, module_file);
if(error!=CUDA_SUCCESS){
printf("Error happened in load moudle %d!\n",error);
}
// Test kernel_run function
error = cuModuleGetFunction(&function, module, kernel_name);
if(error!=CUDA_SUCCESS){
printf("get function error!\n");
}
cuLaunchKernel(function, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0);
cudaThreadSynchronize();
// Test kernel_run2 function
error = cuModuleGetFunction(&function2, module, kernel_name2);
if(error!=CUDA_SUCCESS){
printf("get function error!\n");
}
int age1 = 23;
int age2 = 99;
void *kernelParams[]= {(void *)&age1, (void *)&age2};
cuLaunchKernel(function2, 1, 1, 1, 1, 1, 1, 0, 0, kernelParams, 0);
cudaThreadSynchronize();
// Test kernel_run3 function
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
int cudaStatus = cudaMalloc((void**)&dev_a, sizeof(int));
cudaStatus = cudaMalloc((void**)&dev_b, sizeof(int));
cudaStatus = cudaMalloc((void**)&dev_c, sizeof(int));
int h_a = 1;
int h_b = 99;
cudaMemcpy(dev_a, &h_a, sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, &h_b, sizeof(int), cudaMemcpyHostToDevice);
void *kernelParams3[]= {&dev_c, &dev_a, &dev_b};
error = cuModuleGetFunction(&function3, module, kernel_name3);
if(error!=CUDA_SUCCESS){
printf("get function error!\n");
}
cuLaunchKernel(function3, 1, 1, 1, 1, 1, 1, 0, 0, kernelParams3, 0);
cudaThreadSynchronize();
// exchange data
int sum;
cudaMemcpy(&sum, dev_c, sizeof(int), cudaMemcpyDeviceToHost);
printf("------%d------\r\n", sum);
cudaFree( dev_a );
cudaFree( dev_b );
cudaFree( dev_c );
return 1;
}
Execution sequence
- 1. First compile with nvcc I got it ptx
- 2. Compiling main with gcc C get the final executable program
- 3. Execute the executable
The codes used are as follows
nvcc -ptx cubin.cu gcc main.c -o main -lcudart -lcuda -lstdc++ && ./main
The output is as follows
device count is 1 hello world! p1:23====p2:99. ------100------