The position of yolo Series in the field of target detection goes without saying. There is a code for training yolov5 implemented by pytorch on github. This paper will use its own data to train a yolov5 model. Reference code address
https://github.com/ultralytics/yolov5/tags
Note that here we select v1.0 under tags 0 version for training, different version codes are different, and the reproduction process is also different. Where v1 The training process of version 0 is very similar to yolov3
1, Prepare your own data
labelImg software is used to label the data, and all the data saved are Annotation file in xml format. This time, about 8k pictures are used to train 8 categories (no screenshots for the sample)
2, Training process
2.1 separating data sets
First, create a new folder under yolov5-1.0 folder and put your own picture data and label data in it, as shown below:
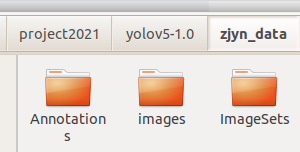
Among them, images is the original picture, Annotations is the annotation file, and the serial number corresponds to that in images one by one.
Then create a new split_ train_ The val.py file divides the training set and the verification set, and generates three files with saved file names, which are train. Under ImageSets txt val.txt trainval.txt test.txt
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
# The address of the xml file is modified according to its own data. xml is generally stored under Annotations
parser.add_argument('--xml_path', default='zjyn_data/Annotations', type=str, help='input xml label path')
# For the division of data sets, select ImageSets/Main under your own data for the address
parser.add_argument('--txt_path', default='zjyn_data/ImageSets', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0
train_percent = 0.9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()The role of this script is to separate the training set and verification set according to the ratio of 9:1, and then generate the corresponding txt file.
2.2 convert xml annotation file to txt
New XML_ 2_ txt. The PY script is as follows:
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
# Change to your own category
classes = ["person", "sport_ball", "bar", "ruler", "cursor", "blanket", "marker_post", "mark_barrels"]
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('zjyn_data/Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('zjyn_data/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
# difficult = obj.find('difficult').text
difficult = obj.find('Difficult')
if difficult is None:
difficult = obj.find('difficult')
difficult = difficult.text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# Mark out of range correction
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('zjyn_data/labels/'):
os.makedirs('zjyn_data/labels/')
image_ids = open('zjyn_data/ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('zjyn_data/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/zjyn_data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()Here are some points:
The classes list can be rewritten into its own category, which should be consistent with data / * Category correspondence of yaml file
The script is based on the previously generated train Txt and val.txt, find the corresponding label file, and then save it in the form of TXT. The specific storage form is:
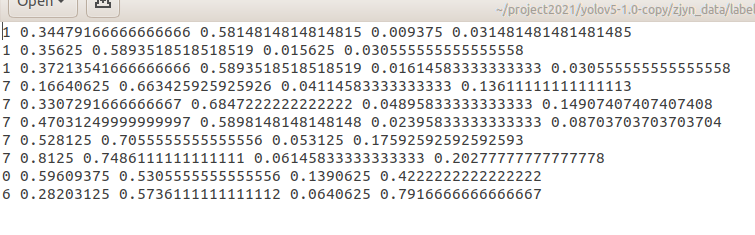
At the same time, the absolute path train of the corresponding picture is generated in the zjyn folder txt, val.txt
2.3 start training
Train under the project Py is a training file.
Set some super parameters under the main function. Just pay attention to a few places.
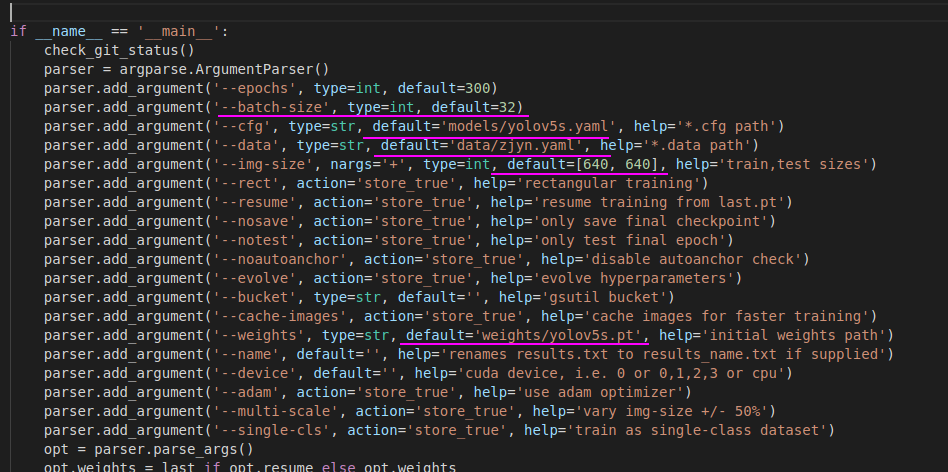
batch_size is set according to the configuration of your own graphics card. The larger the better. I use 2080Ti in batch_ When the size is 32, the video memory is almost full. If it is larger, it will report out_of_momery error.
--cfg this parameter is the network structure file of the model

The four files are the hyperparameter definition files of the network model, representing different network structures, of which yolov5s is the simplest, and the others are deepened and widened on this basis.
Pay attention to making corresponding modifications. For example, if you use yolov5s, you need to modify yolov5s Yaml file
#Change nc to its own category number nc = 8
-- data this parameter indicates the yaml file path of the data, as follows:
# train and val datasets (image directory or *.txt file with image paths) train: /home/elvis/project2021/yolov5-1.0-copy/zjyn_data/train.txt # 6648 images val: /home/elvis/project2021/yolov5-1.0-copy/zjyn_data/val.txt # 738 images train+val = 7387 test: /home/elvis/project2021/yolov5-1.0-copy/zjyn_data/test.txt # number of classes nc: 8 # class names names: ["person", "sport_ball", "bar", "ruler", "cursor", "blanket", "marker_post", "mark_barrels"]
names corresponds to your own category list
image_size parameter. This indicates the input size of the network. Theoretically, the larger the network input, the better the recognition effect for small targets. The overall recognition effect is also better
--weights pre training model file. Optional for initialization. If there is a pre training model, the loss function will converge faster.
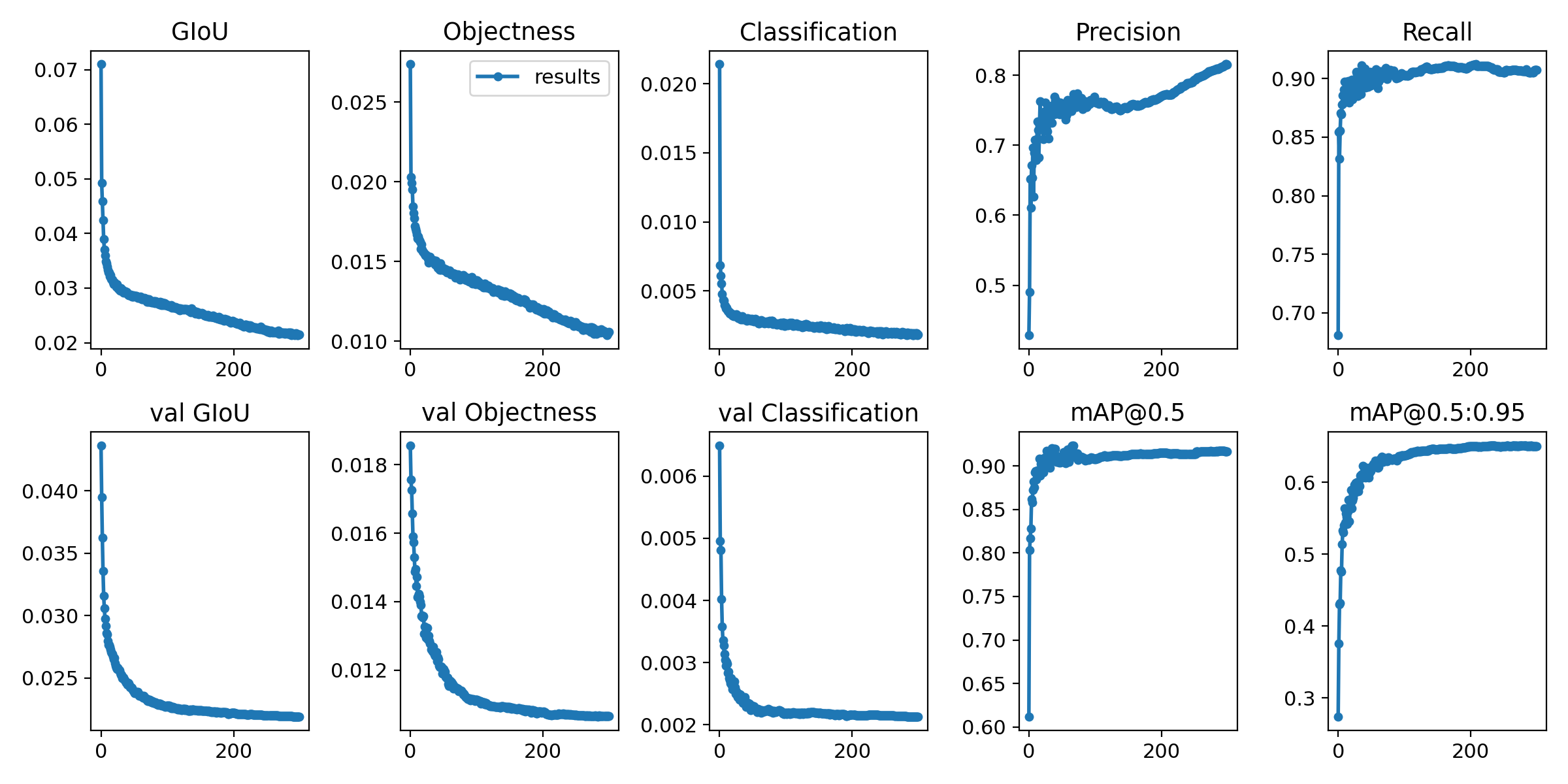
3, Training results
If your own data samples are unbalanced, for example, there are many people in my data and few other categories. Because the source code is the anchor selected by automatic clustering of data, the trained map is very low. So I cancel the clustering and select anchor, and use the default anchor instead. The effect is much better. In train Just annotate the check anchors in the PY file.

The final 8k data was trained by 300 epoch s and lasted 7 hours on 2080Ti. The training result was map = 0.65