1. Foreword
At present, the common methods of point cloud detection are
1. The point cloud is divided into voxels for detection. Typical models include VoxelNet, SECOND, etc; However, Dr. Shi, the author of this paper, proposed that this method will cause quantitative information loss.
2. Project the point cloud to the front view or aerial view for detection, including MV3D, PIXOR, AVOD and other detection models; At the same time, such models will also have quantitative losses.
3. The point cloud is directly generated into a pseudo image, and then processed in 2D, mainly PointPillar.
The method proposed by PointRCNN in this paper is a relatively novel point cloud detection method. Different from the previous detection model, it directly generates candidate frames according to the results of point cloud segmentation, and completes the accurate positioning and classification of objects according to the internal data of these candidate frames and the previous segmentation features.
Thesis address: https://arxiv.org/abs/1812.04244
Source code address: GitHub - sshaoshuai/PointRCNN: PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud, CVPR 2019. https://github.com/sshaoshuai/PointRCNN
https://github.com/sshaoshuai/PointRCNN
OpenPCDet code address:
https://github.com/open-mmlab/OpenPCDet/https://github.com/open-mmlab/OpenPCDet/
After completing the analysis of the network, the code of PointRCNN network in OpenPCDet point cloud detection framework will be explained in detail.
Code implementation class structure diagram of PointRCNN in OpenPCDet
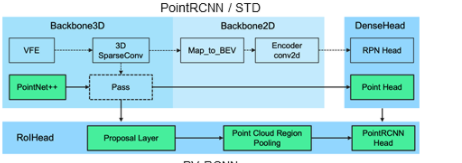
There are three main modules to realize the whole network:
PointNet2MSG: encode and decode the original point cloud (PointNet + +) Pointhead box: classify and predict the point cloud passing PointNet + + PointRCNNHead: fine tune each roi
2. Analysis of network module of PointRCNN
PointRCNN network structure diagram (from the source paper)
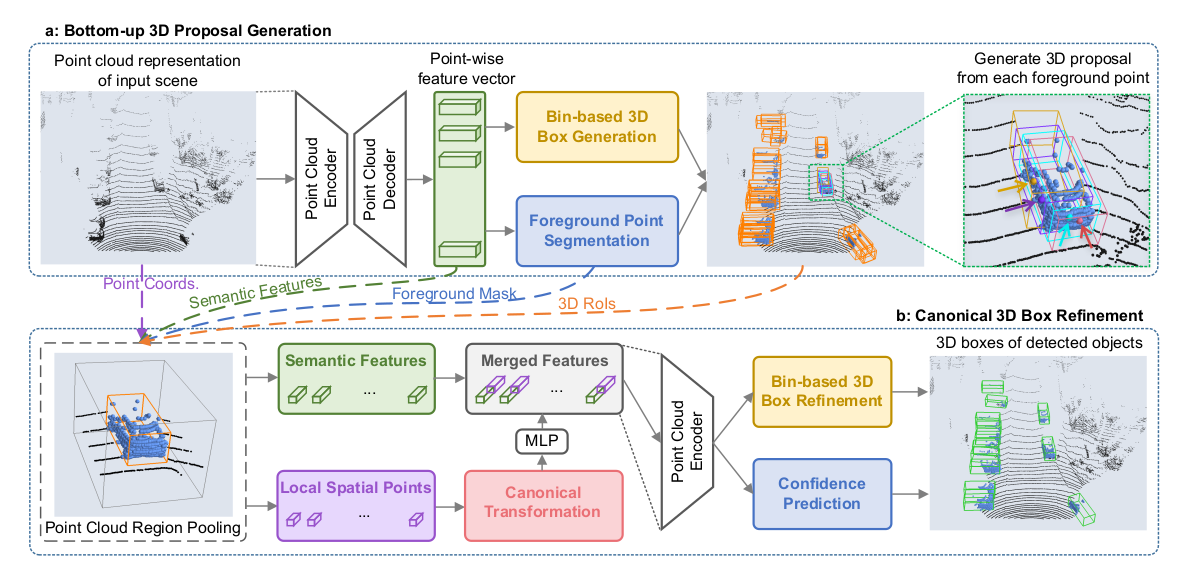
The current 2D detection framework can be divided into first-order and second-order detection models. Generally, the first-order model has higher accuracy, but it lacks the optimization of the generation frame. The second-stage module can further adjust the prediction results according to the proposed frame. It is difficult to directly transfer the two-phase of the two-dimensional detection model to the 3D detection task. Because the 3D detection task has a larger search space, and the point cloud data is not dense data. If you use this method, like AVOD, you need to place 20-100K anchor s in 3-dimensional space, which is stupid; If, like F-PointNet, the 2D detection framework is used to generate the proposal of the object on the image first, and then detect the 3D object in the viewing cone, it can greatly reduce the search range in the 3D space, but it will also lead to many objects that can only be seen in the 3D space can not be displayed in the image due to occlusion and other reasons, At the same time, this method also greatly depends on the performance of 2D detector.
Therefore, PointRCNN divides the mask directly on the point cloud data for the first time (the main reason why the mask can be directly predicted here is that the 3D label box can clearly mark the point cloud data in a GTBox, and in the natural 3D world, there will be no overlap of objects in the picture, so the mask belonging to the foreground in each point cloud is obtained), Then in the second stage, the features learned in the first stage of each proposal and the original point cloud data in the proposal are pooled. By converting the coordinate system into the canonical coordinate system (CCS) coordinate system to further optimize the results of box and cls.
2.1. Bottom up 3D suggestion box generation:
2.1.1 feature extraction network (point cloud network)
In PointRCNN, firstly, the PointNet + + network of multi scale growing is used to segment the front and background points in the point cloud and generate the proposal. Because each GTbox in the marked data can clearly mark which of the front scenic spots and which of the background points in the point cloud belong to; Obviously, the number of background points must be much more than the number of former scenic spots. Therefore, the author uses focal loss to solve the problem of category imbalance.
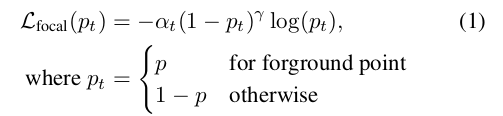
Note: (both alpha and gamma are the same as those set in RetinaNet, alpha is 0.25 and gamma is 2)
In the original PointNet + + network, there is no box region, so the author adds a regression header here to generate a proposal for scenic spots. Here, the segmentation of the front background point and the proposal generation of the front scenic spot are completed synchronously, but in the code implementation, only the box of the front scenic spot is taken. Please note that although the box generation of the proposal here is directly generated from the characteristics of the previous scenic spots, the background points also provide rich receptive field information, because the Point Cloud Encoder and Point Cloud Decoder networks have fused the point cloud data (for example, in PointNet + +, the Decoder back propagates the point information according to the distance weight interpolation).
After the above partial processing, all the front attractions in the network and the proposals generated by the front attractions are obtained. In this way, the stupid operation of setting a large number of anchor s in 3D space is solved, and the search scope of proposal is reduced.
In the process of implementation, 16384 points are randomly sampled for each needle of point cloud data (if the number of points in a frame is less than 16384, repeat the sampling to 16384). Point Cloud Network adopts PointNet + + (MSG), and the author also shows that it is also possible to adopt other networks, such as PointShift, PointNet, voxelnet with spark conv.
PointNet + + parameter settings are as follows:
Encoder consists of four set abstraction layers, and the number of farthest point samples in each layer is 40961024256 and 64 respectively.
The Decoder consists of four feature propagation layers, which are used to obtain the feature vector of each point to segment each point for the later PointHeadBox network, so as to obtain which points belong to the front scenic spots and which points belong to the background points.
Code: pcdet/models/backbones_3d/pointnet2_backbone.py
class PointNet2MSG(nn.Module):
def __init__(self, model_cfg, input_channels, **kwargs):
super().__init__()
self.model_cfg = model_cfg
self.SA_modules = nn.ModuleList()
channel_in = input_channels - 3
self.num_points_each_layer = []
skip_channel_list = [input_channels - 3]
# Initialize SetAbstraction in PointNet + +
for k in range(self.model_cfg.SA_CONFIG.NPOINTS.__len__()):
mlps = self.model_cfg.SA_CONFIG.MLPS[k].copy()
channel_out = 0
for idx in range(mlps.__len__()):
mlps[idx] = [channel_in] + mlps[idx]
channel_out += mlps[idx][-1]
self.SA_modules.append(
pointnet2_modules.PointnetSAModuleMSG(
npoint=self.model_cfg.SA_CONFIG.NPOINTS[k],
radii=self.model_cfg.SA_CONFIG.RADIUS[k],
nsamples=self.model_cfg.SA_CONFIG.NSAMPLE[k],
mlps=mlps,
use_xyz=self.model_cfg.SA_CONFIG.get('USE_XYZ', True),
)
)
skip_channel_list.append(channel_out)
channel_in = channel_out
# Initialize feature back propagation in PointNet + +
self.FP_modules = nn.ModuleList()
for k in range(self.model_cfg.FP_MLPS.__len__()):
pre_channel = self.model_cfg.FP_MLPS[k + 1][-1] if k + 1 < len(self.model_cfg.FP_MLPS) else channel_out
self.FP_modules.append(
pointnet2_modules.PointnetFPModule(
mlp=[pre_channel + skip_channel_list[k]] + self.model_cfg.FP_MLPS[k]
)
)
self.num_point_features = self.model_cfg.FP_MLPS[0][-1]
# Processing point cloud data to obtain the form of (batch, n_points,xyz)
def break_up_pc(self, pc):
batch_idx = pc[:, 0] # After preprocessing, the first dimension data of each point cloud stores the index of the point cloud in batch
xyz = pc[:, 1:4].contiguous() # Get all point cloud data
features = (pc[:, 4:].contiguous() if pc.size(-1) > 4 else None) # Get other data in addition to xyz, such as intensity
return batch_idx, xyz, features
def forward(self, batch_dict):
"""
Args:
batch_dict:
batch_size: int
vfe_features: (num_voxels, C)
points: (num_points, 4 + C), [batch_idx, x, y, z, ...]
Returns:
batch_dict:
encoded_spconv_tensor: sparse tensor
point_features: (N, C)
"""
# batch_size
batch_size = batch_dict['batch_size']
# (batch_size * 16384, 5)
points = batch_dict['points']
# Get the batch index of each point cloud and the xyz and intensity data of all point clouds
batch_idx, xyz, features = self.break_up_pc(points)
# Create a XYZ with all 0_ batch_ CNT, which is used to store the total number of point clouds in each batch
xyz_batch_cnt = xyz.new_zeros(batch_size).int()
for bs_idx in range(batch_size):
xyz_batch_cnt[bs_idx] = (batch_idx == bs_idx).sum()
# In the process of training, the number of midpoint of all point clouds in a batch needs to be equal,
assert xyz_batch_cnt.min() == xyz_batch_cnt.max()
# shape : (batch_size, 16384, 3)
xyz = xyz.view(batch_size, -1, 3)
# shape : (batch_size, 1, 16384)
features = features.view(batch_size, -1, features.shape[-1]).permute(0, 2, 1).contiguous() \
if features is not None else None
# Define a feature back propagation layer used to store the data results through PointNet + +
l_xyz, l_features = [xyz], [features]
# Use the SetAbstraction module in PointNet + + to extract the data of point cloud
for i in range(len(self.SA_modules)):
"""
Number of farthest point samples
NPOINTS: [4096, 1024, 256, 64]
# Radius of BallQuery
RADIUS: [[0.1, 0.5], [0.5, 1.0], [1.0, 2.0], [2.0, 4.0]]
# Maximum number of samples in BallQuery radius (MSG)
NSAMPLE: [[16, 32], [16, 32], [16, 32], [16, 32]]
# Dimension transformation of MLPS
# Where [16, 16, 32] represents the dimension transformation under the first radius and sampling point,
[32, 32, 64]Represents the second radius and the dimension transformation under the sampling point, and so on
MLPS: [[[16, 16, 32], [32, 32, 64]],
[[64, 64, 128], [64, 96, 128]],
[[128, 196, 256], [128, 196, 256]],
[[256, 256, 512], [256, 384, 512]]]
"""
"""
param analyze:
li_xyz shape:(batch, sample_n_points, xyz_of_centroid_of_x)
li_features shape:(batch, channel, Set_Abstraction)
detail:
1,li_xyz shape:(batch, 4096, 3), li_features shape:(batch, 32+64, 4096)
2,li_xyz shape:(batch, 1024, 3), li_features shape:(batch, 128+128, 1024)
3,li_xyz shape:(batch, 256, 3), li_features shape:(batch, 256+256, 256)
4,li_xyz shape:(batch, 64, 3), li_features shape:(batch, 512+512, 64)
"""
li_xyz, li_features = self.SA_modules[i](l_xyz[i], l_features[i])
l_xyz.append(li_xyz)
l_features.append(li_features)
# The feature back propagation layer in PointNet + + calculates the feature information of unknown points in the previous point set through distance interpolation from the known features
"""
Of which:
i=[-1, -2, -3, -4]
with-1 For example:
unknown The feature of is the coordinates of all points in the point set of the upper layer, known Is the coordinate of the point of the currently known feature, feature Is the corresponding feature
Among the known points, find out the three closest unknown points, and then interpolate the three points according to the distance,
Interpolation results are obtained( bacth, 1024, 256),Then the features obtained by interpolation and the features calculated by the previous layer are analyzed in dimension
The result of splicing( bacth, 1024+512, 256),And conduct a mlp(1 used in code implementation*1 Convolution complete) operation
To reduce the dimension and obtain the characteristics of the points on the upper layer( bacth,512, 256). In this way, the deep information is transmitted back.
"""
for i in range(-1, -(len(self.FP_modules) + 1), -1):
unknown = l_xyz[i - 1]
known = l_xyz[i]
unknow_feats = l_features[i - 1]
known_feats = l_features[i]
res = self.FP_modules[i](
unknown, known, unknow_feats, known_feats
) # (B, C, N)
l_features[i - 1] = res
# l_features[i - 1] = self.FP_modules[i](
# l_xyz[i - 1], l_xyz[i], l_features[i - 1], l_features[i]
# ) # (B, C, N)
"""
after PointNet++of feature back-probagation After treatment,
l_feature The result is
[
[batch, 128, 16384],
[batch, 256, 4096],
[batch, 512, 1024],
[batch, 512, 256],
[batch, 1024, 64],
]
"""
# Carry out dimension transformation on the original point cloud data returned in reverse (batch, 128, 16384) - > (batch, 16384, 128)
point_features = l_features[0].permute(0, 2, 1).contiguous() # (B, N, C)
# The obtained results are saved in batch_ dict (batch, 16384, 128) --> (batch * 16384, 128)
batch_dict['point_features'] = point_features.view(-1, point_features.shape[-1])
# (batch * 16384, 1) (batch * 16384, 3) change back to the input form
batch_dict['point_coords'] = torch.cat((batch_idx[:, None].float(), l_xyz[0].view(-1, 3)), dim=1)
return batch_dict
2.1.2 bin based 3D bbox generation (Thesis)
In the lidar coordinate system, a 3D Bbox can be expressed as (x, y, z, l, w, h, θ), xyz is the center of the Bbox in the center of the radar coordinate system, lwh is the length, width and height of the Bbox, θ Is the rotation angle of the object from the BEV perspective.
When generating the box of points, you only need to return the box of the former scenic spot. Although there is no regression operation on the background points, in the reverse return of PointNet + +, the background points also provide rich receptive field information for these former scenic spots.
Bin based localization (figure from the original paper)
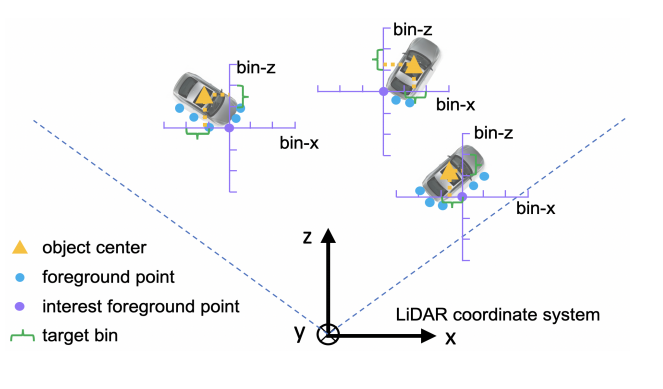
In this paper, the author uses bin based box location estimation, which is to change the original method that only needs regression residuals into classification and regression. What does it mean? If a residual is regressed directly, it is only necessary to make the offset predicted by a box smaller and smaller than the value encoded by the box, but here it is converted to the classification of which bin the GT corresponding to the former scenic spot is in and the regression of the remaining part in the bin. You can see the picture above. The calculated target formula is as follows:
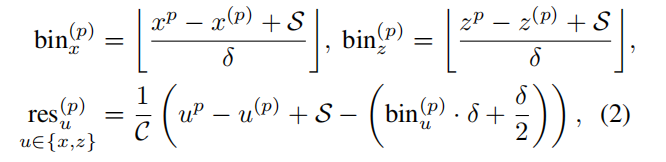
Where x^p is the central coordinate of GT and x^(p) is the origin of the current former scenic spot. S is the search range, which is set to 3m in the paper,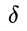 Is the size of bin, set to 0.5m. C is the length of bin for normalization.
Is the size of bin, set to 0.5m. C is the length of bin for normalization.
Then, if this setting is set, the offset to GT becomes the classification problem of the nth bin and the regression problem of residual region in the nth bin. In the paper, the author said that this method has a higher regression progress than using L1 loss function directly.
For height prediction, SmoothL1 is directly used to regress the residuals between, because the change in height is not so large.
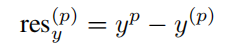
At the same time, for the prediction of angle, the bin based method is also adopted. 2pi is divided into n bins, and the bin in which GT is classified is regressed with the residual region in the corresponding classified bin.
Here, the length, width and height of the object used in box generation is a draw value directly based on the length, width and height of each category in the overall data set. When encoding box, the data is directly used for encoding.
The total loss is recorded as:
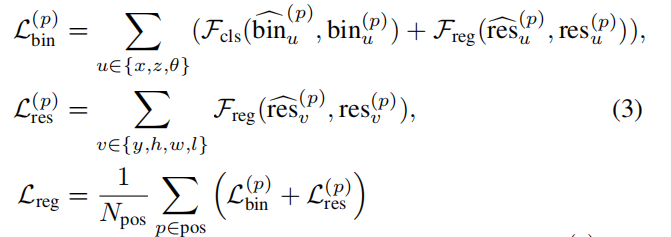
The total number of Npos is,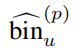 And
And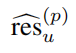 It is the result of the prediction of the former scenic spots
It is the result of the prediction of the former scenic spots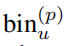 and
and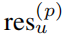 It is the coding result of GT. Fcls stands for cross entry classification loss, and Freg stands for smoothL1 loss.
It is the coding result of GT. Fcls stands for cross entry classification loss, and Freg stands for smoothL1 loss.
In the reasoning stage, the bin base prediction only needs to find the bin with the highest prediction confidence and add the prediction result of residual error. Other parameters only need to add the predicted value to the initial value.
The content implementation of this part is the same as that in the code warehouse of the original paper, but in OpenPCDet, Shi Shuai's implementation does not use the method based on bin base, but directly uses smoothL1 for prediction; At the same time, angle prediction has changed from bin based method to residual cos based method.
See the issue for details: https://github.com/open-mmlab/OpenPCDet/issues/255
2.1.2 generation of box in code (OpenPCdet)
Well, back to the main body, this blog has been parsed based on the code of OpenPCDet code warehouse. Here, the actual code has been parsed.
After PointNet + +, the output of the point feature obtained by the network is (batch * 16384128). Next, it is necessary to classify and regress each point.
Code: pcdet / Models / deny_ heads/point_ head_ box. py
def forward(self, batch_dict):
"""
Args:
batch_dict:
batch_size:
point_features: (N1 + N2 + N3 + ..., C) or (B, N, C)
point_features_before_fusion: (N1 + N2 + N3 + ..., C)
point_coords: (N1 + N2 + N3 + ..., 4) [bs_idx, x, y, z]
point_labels (optional): (N1 + N2 + N3 + ...)
gt_boxes (optional): (B, M, 8)
Returns:
batch_dict:
point_cls_scores: (N1 + N2 + N3 + ..., 1)
point_part_offset: (N1 + N2 + N3 + ..., 3)
"""
# False
if self.model_cfg.get('USE_POINT_FEATURES_BEFORE_FUSION', False):
point_features = batch_dict['point_features_before_fusion']
else:
point_features = batch_dict['point_features'] # Feature shape of each point from the dictionary (batch * 16384, 128)
""" Network details of point classification
Sequential(
(0): Linear(in_features=128, out_features=256, bias=False)
(1): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Linear(in_features=256, out_features=256, bias=False)
(4): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Linear(in_features=256, out_features=3, bias=True)
)
"""
# Classify each point (batch * 16384, num_class)
point_cls_preds = self.cls_layers(point_features)
""" Point generation proposal The network details of which the author used here residual-cos-based To codeθ,That is, the angle is (cos(∆θ), sin(∆θ))So the final regression parameters are 8
Sequential(
(0): Linear(in_features=128, out_features=256, bias=False)
(1): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Linear(in_features=256, out_features=256, bias=False)
(4): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Linear(in_features=256, out_features=8, bias=True)
)
"""
# Point regression proposal (batch * 16384, box_code_size)
point_box_preds = self.box_layers(point_features)
# From the classification prediction results of each point, take out the result with the largest prediction probability of category (batch * 16384, num_class) - > (batch * 16384, num_class)
point_cls_preds_max, _ = point_cls_preds.max(dim=-1)
# Put the category prediction score into the dictionary after sigmoid activation
batch_dict['point_cls_scores'] = torch.sigmoid(point_cls_preds_max)
# Put the category prediction results and regression results of points into the dictionary
ret_dict = {'point_cls_preds': point_cls_preds,
'point_box_preds': point_box_preds}
# If you are in the training mode, you need to generate the corresponding front background points according to the GTBox for the front background segmentation of the point cloud, and calculate the front background classification loss for the later
if self.training:
targets_dict = self.assign_targets(batch_dict)
# Put the GT category results of all points in a batch into the dictionary shape (batch * 16384)
ret_dict['point_cls_labels'] = targets_dict['point_cls_labels']
# Gt of all points in a batch_ Put the box encoding result into the dictionary shape (batch * 16384) shape (batch * 16384, 8)
ret_dict['point_box_labels'] = targets_dict['point_box_labels']
# Both training and prediction need to generate the proposal of the first stage, and then give it to the second stage to refine
if not self.training or self.predict_boxes_when_training:
# Generate forecast box
point_cls_preds, point_box_preds = self.generate_predicted_boxes(
# xyz coordinates of all points (batch*16384, 3)
points=batch_dict['point_coords'][:, 1:4],
# Forecast category of all points (batch*16384, 3)
point_cls_preds=point_cls_preds,
# box prediction of all points (batch*16384, 8)
point_box_preds=point_box_preds
)
batch_dict['batch_cls_preds'] = point_cls_preds # Category prediction results of all points (batch * 16384, 3)
batch_dict['batch_box_preds'] = point_box_preds # Regression prediction results of all points (batch * 16384, 7)
batch_dict['batch_index'] = batch_dict['point_coords'][:, 0] # Index of all points in batch (batch * 16384,)
batch_dict['cls_preds_normalized'] = False # Is it necessary to normalize the category prediction results in loss calculation
# The prediction results generated in the first stage are put into the forward propagation dictionary
self.forward_ret_dict = ret_dict
return batch_dict1. target assignment of the background point before the training stage
After classifying each point, you can get the point_cls_preds_max, the dimension is (batch * 16384, num_class), and take out the maximum value of each category and activate sigmoid to get point_cls_scores, the dimension is (batch * 16384,). Then perform target assignment.
During target assignment, the length, width and height of each GT shall be extended by 0.2m, and the target of these points at the edge of 0.2m shall be set to - 1, and the classification loss shall not be calculated. The reason is to improve the robustness of point cloud segmentation, because there will be small changes in 3D GTBox.
Code: pcdet / Models / deny_ heads/point_ head_ box. py
def assign_targets(self, input_dict):
"""
Args:
input_dict:
point_features: (N1 + N2 + N3 + ..., C)
batch_size:
point_coords: (N1 + N2 + N3 + ..., 4) [bs_idx, x, y, z]
gt_boxes (optional): (B, M, 8)
Returns:
point_cls_labels: (N1 + N2 + N3 + ...), long type, 0:background, -1:ignored
point_part_labels: (N1 + N2 + N3 + ..., 3)
"""
# Get the coordinate shape (bacth * 16384, 4) of each point, of which the four dimensions are batch respectively_ id,x,y,z
point_coords = input_dict['point_coords']
# Remove gt_box,shape (batch, num_of_GTs, 8),
# Where dimension 8 represents x, y, z, l, w, h, heading, class_id
gt_boxes = input_dict['gt_boxes']
# Make sure the dimensions are correct
assert gt_boxes.shape.__len__() == 3, 'gt_boxes.shape=%s' % str(gt_boxes.shape)
assert point_coords.shape.__len__() in [2], 'points.shape=%s' % str(point_coords.shape)
batch_size = gt_boxes.shape[0]
# In the process of training, it is necessary to ignore the points close to the GTBox in the point cloud, because the 3D GTBox will also be disturbed,
# So here by putting every GT_ The box expands by 0.2 meters in the x, y and z directions,
# To detect which points belong to the expanded points and enhance the robustness of point cloud segmentation
extend_gt_boxes = box_utils.enlarge_box3d(
gt_boxes.view(-1, gt_boxes.shape[-1]), extra_width=self.model_cfg.TARGET_CONFIG.GT_EXTRA_WIDTH
).view(batch_size, -1, gt_boxes.shape[-1])
"""
assign_stack_targets The function completes the front and background allocation of all points in a batch of data,
Each former scenic spot is assigned a corresponding category and box Seven regression parameters, xyzlwhθ
"""
targets_dict = self.assign_stack_targets(
points=point_coords, gt_boxes=gt_boxes, extend_gt_boxes=extend_gt_boxes,
set_ignore_flag=True, use_ball_constraint=False,
ret_part_labels=False, ret_box_labels=True
)
return targets_dictself. assign_ stack_ The targets () function is used to complete the front background allocation of point clouds in a batch of data and the average anchor size and GTbox encoding of each category of foreground point clouds Code: pcdet / Models / deny_ heads/point_ head_ template. py
def assign_stack_targets(self, points, gt_boxes, extend_gt_boxes=None,
ret_box_labels=False, ret_part_labels=False,
set_ignore_flag=True, use_ball_constraint=False, central_radius=2.0):
"""
Args:
points: (N1 + N2 + N3 + ..., 4) [bs_idx, x, y, z]
gt_boxes: (B, M, 8)
extend_gt_boxes: [B, M, 8]
ret_box_labels: True
ret_part_labels: Fasle
set_ignore_flag: True
use_ball_constraint: False
central_radius:
Returns:
point_cls_labels: (N1 + N2 + N3 + ...), long type, 0:background, -1:ignored
point_box_labels: (N1 + N2 + N3 + ..., code_size)
"""
assert len(points.shape) == 2 and points.shape[1] == 4, 'points.shape=%s' % str(points.shape)
assert len(gt_boxes.shape) == 3 and gt_boxes.shape[2] == 8, 'gt_boxes.shape=%s' % str(gt_boxes.shape)
assert extend_gt_boxes is None or len(extend_gt_boxes.shape) == 3 and extend_gt_boxes.shape[2] == 8, \
'extend_gt_boxes.shape=%s' % str(extend_gt_boxes.shape)
assert set_ignore_flag != use_ball_constraint, 'Choose one only!'
# Get batch data_ Size to facilitate the completion of target assign frame by frame
batch_size = gt_boxes.shape[0]
# Get the batch of all point clouds in a batch of data_ id
bs_idx = points[:, 0]
# Initialize the category of each point cloud, with all 0 by default; shape (batch * 16384)
point_cls_labels = points.new_zeros(points.shape[0]).long()
# Initialize the parameters of each point cloud prediction box, all 0 by default; shape (batch * 16384, 8)
point_box_labels = gt_boxes.new_zeros((points.shape[0], 8)) if ret_box_labels else None
# None
point_part_labels = gt_boxes.new_zeros((points.shape[0], 3)) if ret_part_labels else None
# Processing point cloud data frame by frame
for k in range(batch_size):
# Get a mask, which is used to retrieve the points belonging to the current frame in a batch of data
bs_mask = (bs_idx == k)
# Take out the corresponding point shape (16384, 3)
points_single = points[bs_mask][:, 1:4]
# Initializes the category of points in the current frame. The default is 0 (16384,)
point_cls_labels_single = point_cls_labels.new_zeros(bs_mask.sum())
"""
points_single : (16384, 3) --> (1, 16384, 3)
gt_boxes : (batch, num_of_GTs, 8) --> (Current frame GT, num_of_GTs, 8)
box_idxs_of_pts : (16384, ),The background in point cloud segmentation is-1, Front scenic spot direction GT Index in,
for example[-1,-1,3,20,-1,0],Of which, 3,20,0 Point to 0, 3 and 20 respectively GT
"""
# Calculate which points are in GTbox, box_idxs_of_pts
box_idxs_of_pts = roiaware_pool3d_utils.points_in_boxes_gpu(
points_single.unsqueeze(dim=0), gt_boxes[k:k + 1, :, 0:7].contiguous()
).long().squeeze(dim=0)
# Mask indicates which points in the frame belong to the front scenic spot and which points belong to the background; Get the mask belonging to the former scenic spot
box_fg_flag = (box_idxs_of_pts >= 0)
# Whether to ignore the point True in enlarger box
if set_ignore_flag:
# Calculate which points are in the gtbox_ In enlarger
extend_box_idxs_of_pts = roiaware_pool3d_utils.points_in_boxes_gpu(
points_single.unsqueeze(dim=0), extend_gt_boxes[k:k + 1, :, 0:7].contiguous()
).long().squeeze(dim=0)
# Former scenic spot
fg_flag = box_fg_flag
# ^It is an XOR operator. The difference is true and the same is false. In this way, we can get the point after the real GT enlarge r
ignore_flag = fg_flag ^ (extend_box_idxs_of_pts >= 0)
# Set the points on these real GT edges to - 1. Such points are not considered in loss calculation
point_cls_labels_single[ignore_flag] = -1
elif use_ball_constraint:
box_centers = gt_boxes[k][box_idxs_of_pts][:, 0:3].clone()
box_centers[:, 2] += gt_boxes[k][box_idxs_of_pts][:, 5] / 2
ball_flag = ((box_centers - points_single).norm(dim=1) < central_radius)
fg_flag = box_fg_flag & ball_flag
else:
raise NotImplementedError
# Take out all points in the foreground,
# And assign corresponding GT to these points_ box shape (num_of_gt_match_by_points, 8)
# The eight dimensions are x, y, Z, l, W, h, heading and class_ id
gt_box_of_fg_points = gt_boxes[k][box_idxs_of_pts[fg_flag]]
# Assign the category information to the corresponding front scenic spot (16384,)
point_cls_labels_single[fg_flag] = 1 if self.num_class == 1 else gt_box_of_fg_points[:, -1].long()
# The corresponding frame position in the batch from the category GT result of the assignment point
point_cls_labels[bs_mask] = point_cls_labels_single
# If the number of front attractions of GT in this frame is greater than 0
if ret_box_labels and gt_box_of_fg_points.shape[0] > 0:
# Initialize 8 regression parameters of box in this frame and set them to 0
# Code here is( Δ x, Δ y, Δ z. DX, Dy, DZ, cos (heading), sin (heading)) 8
point_box_labels_single = point_box_labels.new_zeros((bs_mask.sum(), 8))
# Encode the box belonging to the former scenic spot to get (num_of_fg_points, 8)
# Eight of them are( Δ x, Δ y, Δ z, dx, dy, dz, cos(heading), sin(heading))
fg_point_box_labels = self.box_coder.encode_torch(
gt_boxes=gt_box_of_fg_points[:, :-1], points=points_single[fg_flag],
gt_classes=gt_box_of_fg_points[:, -1].long()
)
# Assign the box information of each front scenic spot to the box parameter prediction in this frame
# fg_point_box_labels: (num_of_GT_matched_by_point,8)
# point_box_labels_single: (16384, 8)
point_box_labels_single[fg_flag] = fg_point_box_labels
# The corresponding frame position in the batch from the regression coding result of the assignment point
point_box_labels[bs_mask] = point_box_labels_single
# False
if ret_part_labels:
point_part_labels_single = point_part_labels.new_zeros((bs_mask.sum(), 3))
transformed_points = points_single[fg_flag] - gt_box_of_fg_points[:, 0:3]
transformed_points = common_utils.rotate_points_along_z(
transformed_points.view(-1, 1, 3), -gt_box_of_fg_points[:, 6]
).view(-1, 3)
offset = torch.tensor([0.5, 0.5, 0.5]).view(1, 3).type_as(transformed_points)
point_part_labels_single[fg_flag] = (transformed_points / gt_box_of_fg_points[:, 3:6]) + offset
point_part_labels[bs_mask] = point_part_labels_single
# Put the category of each point and the 7 regression parameters corresponding to each point into the dictionary
targets_dict = {
# Put the GT category results of all points in a batch into the dictionary shape (batch * 16384)
'point_cls_labels': point_cls_labels,
# Gt of all points in a batch_ Put the box encoding result into the dictionary shape (batch * 16384) shape (batch * 16384, 8)
'point_box_labels': point_box_labels,
# None
'point_part_labels': point_part_labels
}
return targets_dictIn the encoding operation of GTbox and anchor, the average length, width and height of each category in the data set is the size of anchor to complete the encoding.
Here, we use residual cos based to encode the angle, and use the "Torch" of the angle cos(rg), torch. Sin (RG) to encode the heading value of GT.
Code: pcdet/utils/box_coder_utils.py
class PointResidualCoder(object):
def __init__(self, code_size=8, use_mean_size=True, **kwargs):
super().__init__()
self.code_size = code_size
self.use_mean_size = use_mean_size
if self.use_mean_size:
self.mean_size = torch.from_numpy(np.array(kwargs['mean_size'])).cuda().float()
assert self.mean_size.min() > 0
def encode_torch(self, gt_boxes, points, gt_classes=None):
"""
Args:
gt_boxes: (N, 7 + C) [x, y, z, dx, dy, dz, heading, ...]
points: (N, 3) [x, y, z]
gt_classes: (N) [1, num_classes]
Returns:
box_coding: (N, 8 + C)
"""
# Each GT_ The length, width and height of box shall not be less than 1 * 10 ^ - 5, which is limited here
gt_boxes[:, 3:6] = torch.clamp_min(gt_boxes[:, 3:6], min=1e-5)
# This means torch The second parameter of split is torch split(tensor, split_size, dim=) split_ Size is the size of each piece after segmentation,
# Not how many pieces to cut!, Redundant parameters are received with * cags. dim=-1 indicates the parameter of the last dimension
xg, yg, zg, dxg, dyg, dzg, rg, *cgs = torch.split(gt_boxes, 1, dim=-1)
# The above split is gt_box parameters. The parameters of each point are divided below
xa, ya, za = torch.split(points, 1, dim=-1)
# True here, the average length, width and height of each category calculated based on the dataset are used
if self.use_mean_size:
# Ensure that the number of categories in GT is consistent with the category calculated by length, width and height
assert gt_classes.max() <= self.mean_size.shape[0]
"""
Average length, width and height of each category
Car: [3.9, 1.6, 1.56],
Person: [0.8, 0.6, 1.73],
Bicycle: [1.76, 0.6, 1.73]
"""
# According to the category index of each point, the anchor size of the corresponding category is generated for each point. This anchor comes from the average length, width and height of the category in the dataset
point_anchor_size = self.mean_size[gt_classes - 1]
# Split the length, width and height of each generated anchor
dxa, dya, dza = torch.split(point_anchor_size, 1, dim=-1)
# Calculate the bottom diagonal distance of each anchor
diagonal = torch.sqrt(dxa ** 2 + dya ** 2)
# The formula for calculating loss, Δ x, Δ y, Δ z, Δ w, Δ l, Δ h, Δθ
# The following encoding operations are the same as those in SECOND and Pointpillars
# Coordinate point coding
xt = (xg - xa) / diagonal
yt = (yg - ya) / diagonal
zt = (zg - za) / dza
# Encoding of length, width and height
dxt = torch.log(dxg / dxa)
dyt = torch.log(dyg / dya)
dzt = torch.log(dzg / dza)
# The encoding operation of angle is torch.cos(rg),torch.sin(rg) #
else:
xt = (xg - xa)
yt = (yg - ya)
zt = (zg - za)
dxt = torch.log(dxg)
dyt = torch.log(dyg)
dzt = torch.log(dzg)
cts = [g for g in cgs]
# On return, for each GT_ The orientation information of box is used to calculate cosine and sine
return torch.cat([xt, yt, zt, dxt, dyt, dzt, torch.cos(rg), torch.sin(rg), *cts], dim=-1)The results obtained are
targets_dict = {
# Put the GT category results of all points in a batch into the dictionary shape (batch * 16384)
'point_cls_labels': point_cls_labels,
# Gt of all points in a batch_ Put the box encoding result into the dictionary shape (batch * 16384) shape (batch * 16384, 8)
'point_box_labels': point_box_labels,
# None
'point_part_labels': point_part_labels
}2. proposal generation in the first stage
According to point_coords,point_cls_preds and point_box_preds to generate the proposal of the former scenic spot.
Code: pcdet / Models / deny_ heads/point_ head_ template. py
def generate_predicted_boxes(self, points, point_cls_preds, point_box_preds):
"""
Args:
points: (N, 3) Actual coordinates of each point
point_cls_preds: (N, num_class) Prediction results for each point category
point_box_preds: (N, box_code_size) Each point box Regression results of
Returns:
point_cls_preds: (N, num_class)
point_box_preds: (N, box_code_size)
"""
# Get the index of the maximum value of all point prediction categories (batch*16384, 3) - > (batch*16384,)
_, pred_classes = point_cls_preds.max(dim=-1)
# Decode the corresponding box according to the predicted point
# Point in the first stage_ box_ The seven features of preds (batch * 16384, 7) represent x, y, z, l, w, h, Θ
# point_box_preds (batch * 16384, 8) 8 Two features represent x, y, z, l, w, h, cos(Θ), sin(Θ)##
point_box_preds = self.box_coder.decode_torch(point_box_preds, points, pred_classes + 1)
# Return the forecast category of all anchors and the anchor generated by the corresponding category
return point_cls_preds, point_box_predsThe decoding operation code of proposal is: pcdet/utils/box_coder_utils.py
def decode_torch(self, box_encodings, points, pred_classes=None):
"""
Args:
box_encodings: (N, 8 + C) [x, y, z, dx, dy, dz, cos, sin, ...]
points: [x, y, z]
pred_classes: (N) [1, num_classes]
Returns:
"""
# Torch means here The second parameter of split is torch split(tensor, split_size, dim=) split_ Size is the size of each piece after segmentation,
# Not how many pieces to cut!, Redundant parameters are received with * cags. dim=-1 indicates the parameter of the last dimension
xt, yt, zt, dxt, dyt, dzt, cost, sint, *cts = torch.split(box_encodings, 1, dim=-1)
# Get the actual coordinate position of each point in the point cloud
xa, ya, za = torch.split(points, 1, dim=-1)
# True here, the average length, width and height of each category calculated based on the dataset are used
if self.use_mean_size:
# Ensure that the number of categories in GT is consistent with the category calculated by length, width and height
assert pred_classes.max() <= self.mean_size.shape[0]
# According to the category index of each point, the anchor size of the corresponding category is generated for each point
point_anchor_size = self.mean_size[pred_classes - 1]
# Split the length, width and height of each generated anchor
dxa, dya, dza = torch.split(point_anchor_size, 1, dim=-1)
# Calculate the bottom diagonal distance of each anchor
diagonal = torch.sqrt(dxa ** 2 + dya ** 2)
# Operation of anchor and GT code in loss calculation: g represents GT and a represents anchor
# ∆x = (x^gt − xa^da)/diagonal --> x^gt = ∆x * diagonal + x^da
# The same below
xg = xt * diagonal + xa
yg = yt * diagonal + ya
zg = zt * dza + za
# ∆ L = inverse operation of log (L ^ GT / L ^ a -- > L ^ GT = exp (∆ l) * l^a
# The same below
dxg = torch.exp(dxt) * dxa
dyg = torch.exp(dyt) * dya
dzg = torch.exp(dzt) * dza
# The decoding operation of the angle is torch.atan2(sint, cost) #
else:
xg = xt + xa
yg = yt + ya
zg = zt + za
dxg, dyg, dzg = torch.split(torch.exp(box_encodings[..., 3:6]), 1, dim=-1)
# The angle value of predicted box is inversely solved according to sint and cost
rg = torch.atan2(sint, cost)
cgs = [t for t in cts]
return torch.cat([xg, yg, zg, dxg, dyg, dzg, rg, *cgs], dim=-1)The final result is:
# Category prediction results of all points (batch * 16384, 3)
batch_dict['batch_cls_preds'] = point_cls_preds
# Regression prediction results of all points (batch * 16384, 7)
batch_dict['batch_box_preds'] = point_box_preds
# Index of all points in batch (batch * 16384,)
batch_dict['batch_index'] = batch_dict['point_coords'][:, 0]
# Is it necessary to normalize the category prediction results in loss calculation
batch_dict['cls_preds_normalized'] = False2.2. Point cloud area pooling:
After obtaining the proposal of 3DBbox, the focus will be on how to optimize the position and orientation of the box. In order to learn more detailed proposal features, PointRCNN pools the features of points in each proposal and internal points through pooling.